git merge 与 rebase
- git merge
- git rebase
- merge V.S. rebase
- 参考材料
写在开始:
对merge和rebase的用法总有疑惑,好像两个都能完成“获取别的branch的commits到我的branch上”,那二者的区别又是什么。通过一些文章和实验,整理如下,参考资料附后。
1.git merge
来看两种场景中merge的不同方式。
- 场景一:切出特性分支后,develop分支上没有新的提交。
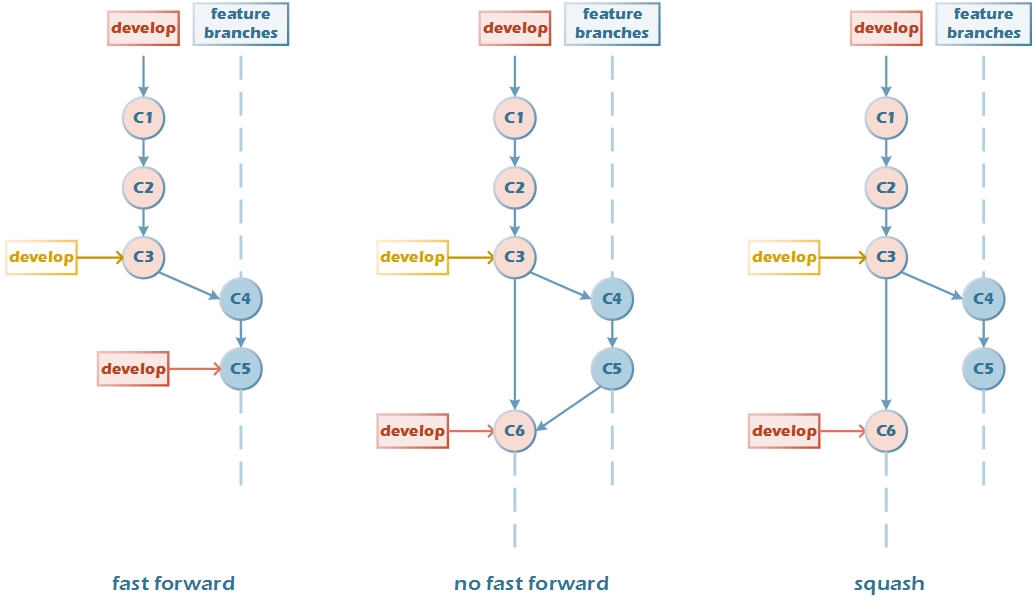
fast-forward,若无分歧,会直接移动文件指针。看不出特性分支的起始点。
no-fast-forward(--no-ff),保留提交链的完整性。
squash,压缩不必要的commit;无法看出feature分支合到develop;feature,develop保持相对独立。
- 场景二:切出特性分支后,develop分支上提交了C6,C7。
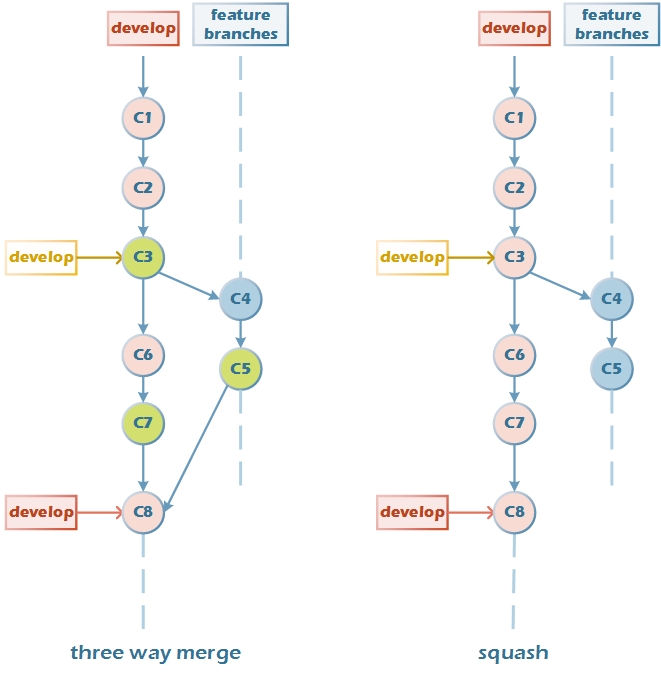
develop分支上提交了C6,C7,无法fast forward。
three way merge,
- 找到develop分支的最新节点C7;
- 找到feature分支的最新节点C5;
- 找到develop分支和feature分支的共同祖先节点C3;
- 对C3,C5,C7进行三方合并,生成最新的C8。
2.git rebase
变基/衍合,从旧的base变基到新的base,在新base的基础上重现另一个分支的修改过程,版本树像两个链条串在一起变成一个链条,以达到线性的效果。
rebase,对指定的base本身并没有什么影响;只是重写base之后的commit历史。
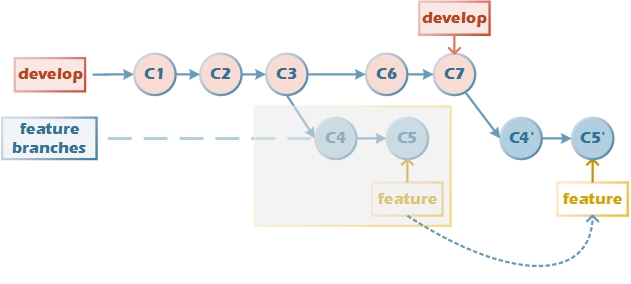
来看几个场景:
- 在继续开发的过程中和主分支develop同步
从develop上拉出分支做一些开发工作,在这个过程中develop分支可能继续往前走了,那我们需要经常和develop保持下同步(可能是别人提交了公用的模块,或者修复了对大家都有影响的bug)。之前我会通过pull操作来达到这一目的,但pull往往内置了merge(pull的效果看起来就像fetch+merge,想想提到过的“merge应该反映业务层面的合并,而非技术行为”,并且此时merge会产生一些杂乱的历史记录)。
这就相当于我们本地的开发工作(一系列的commits)是在旧的base上展开的,应该使用rebase操作,将本地的开发工作变基到develop的最新节点上。
git pull --rebase
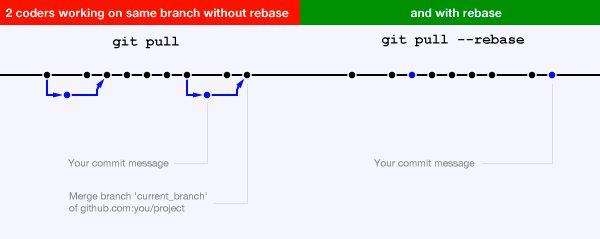
- 重新拾起搁置的工作
很久之前可能启动一个并行工作(开发不着急上线的新特性或者优化一些功能),但一直没有时间处理所以就搁置了,现在又有时间重新拾起,然后就发现当时基于的base实在是太太太老了。现在肯定是希望基于最新的base展开工作,这样就可以从已解决的bugfix或已完成的新特性中中受益。
- 在push之前整理我的本地历史
git rebase -i <myBaseCommit>
这是一个使用更频繁的场景:并不是为了变基,而是清理本地的commit。很多情况我们都需要commit:
- 可能需要多个连续的commit才能完成一次bugfix;
- 切换分支需要保存本地修改(当然按理说这个时候应该使用stash或者idea提供的shelve了);
- 某些历史commit写错了msg(最近一次commit的msg可以通过 commit --amend 修改);
通过-i(--interactive,交互式的),我们可以干预rebase将要执行的脚本化过程,从而达到清理本地commit历史的目的。
关于git rebase -i 的博文:聊下 git rebase -i
熟练使用rebase,可以轻松的进行commit,只需要在最终push之前做一次清理,不必担心影响到公共仓库。
git fetch origin develop
git rebase origin/develop
... do sth ...
git push
- rebase的场景和用法还有待探索,慢慢更新了。
记住这个:
只能rebase私有分支,一旦发布到公共仓库,不要再rebase了。
3.merge V.S. rebase
什么时候用merge;基于上述不同的merge行为(fast-forward,--no-ff,squash),什么场景下用哪种merge:
merge执行一个合并,这个合并应该反应业务层面的合并,而非技术行为。我们希望在当前分支上往前走,这样它就包含了其他分支的工作。
所以问题的关键是:这个“其他分支”是什么样的分支?这个“其他分支”需要在历史图谱中展示么?
- 本地的、临时的分支,使用它仅仅是为了使master保持clean。
1.若拉出本地分支后,master往前走了,此时在本地分支:
git rebase -i master
将本地分支变基到最新的master节点(重新梳理本地历史提交信息比如合并成一个commit),好似本地分支就是在最新的master节点上做的开发工作,以保证合并到master后呈现线性增长。
2.在master上:
git merge (fast-forward)
最终以一个或几个commit展现在master上。
- 知名分支,团队明确定义的,可能是用来追踪bug/feature。
永远不要用rebase,而是用
git merge --no-ff
以保留清晰完整的历史图谱。
4.参考材料
GETTING SOLID AT GIT REBASE VS. MERGE
Git team workflows: merge or rebase?
A successful Git branching model
git merge 与 rebase的更多相关文章
- [git]merge和rebase的区别
前言 我从用git就一直用rebase,但是新的公司需要用merge命令,我不是很明白,所以查了一些资料,总结了下面的内容,如果有什么不妥的地方,还望指正,我一定虚心学习. merge和rebase ...
- git merge 和 rebase 区别
git pull 超级不推荐使用git pull 有坑,谨慎使用,pull底层是merge git pull 是 git fetch + git merge FETCH_HEAD 的缩写.所以,默认 ...
- git merge,rebase和*(no branch)
上一篇:http://blog.csdn.net/xiaoputao0903/article/details/23933589,说了git的分支,相关的使用方法没说到可是仅仅要google就能搜出一大 ...
- 关于git merge,rebase合并的差别,以及*(no branch)的处理。
1.merge 在上篇介绍分支的时候有简单的说了一下分支的创建和合并,当时合并就是写的merge,这是依据两个不同分支的最后一次提交的commit对象c5,c7和两个分支的交叉点的commit对象c3 ...
- Git merge 和 rebase 进一步比较
但是 假如 我不想看到 分支转折点呢 合并的分支始终会存在一个交叉点 Microsoft Windows [版本 10.0.17134.345] (c) Microsoft Corporation.保 ...
- [Git] git merge和rebase的区别
git merge 会生成一个新得合并节点,而rebase不会 比如: D---E test / A---B---C---F master 使用merge合并, 为分支合并自动识别出最佳的同源合并点: ...
- git——merge和rebase的区别
参考http://www.jianshu.com/p/129e721adc6e 我在公司里看到其他同事都使用git pull --rebase拉取远程代码,而我总是用git pull,也有同事和我说过 ...
- git merge与rebase
参考这篇文章 Git 之 merge 与 rebase 的区别 文章2 另外,使 rebase出现冲突后,先修改冲突,然后git add 某文件(我使用add .经常有问题),然后git reba ...
- git merge 与 rebase 的区别
http://gitbook.liuhui998.com/4_2.html merge rebase
随机推荐
- gradle2.0笔记——让项目升级到gradle2.0
昨晚看到QQ群消息说gradle2.0发布了,今天去看了一下,确实是昨天发布的,为rc版本:Gradle 2.0-rc-2.于是决定试一下. gradle可以在官网上下载,地址如下:http://ww ...
- iOS开发之三:常用控件--UILabel的使用
UILabel 一般用来显示文本内容. 常用的属性如下: @property(nonatomic,copy) NSString *text; // 文本的内容,默认为 nil @property(no ...
- jquery 只读
大家都理解这是什么,正常的写法如下: if (status == true) { $("#minDelistStr").val(totalAmount);// 去掉首部的" ...
- Oracle WorkFlow(工作流)(二)
2.4消息(Message) 消息主要是为通知服务的,可以把消息当作通知的内容和类型.消息也属于一个单据类型,通知只能和同一个单据类型里的消息相关联. 每个消息可以有一个或多个属性和自己相联系,消息的 ...
- 【一天一道LeetCode】#98. Validate Binary Search Tree
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given a ...
- ROS(indigo)_turtlebot仿真示例包括stage和gazebo
ROS(indigo)_turtlebot仿真示例包括stage和gazebo 现上参考网址: turtlebot:http://wiki.ros.org/Robots/TurtleBot stage ...
- 小试ImageMagik——开发篇
===================================================== ImageMagick的使用和开发的文章: 小试ImageMagik--使用篇 小试Imag ...
- 高通msm8994启动流程简介
处理器信息 8994包含如下子系统: 子系统 处理器 含义 APSS 4*Cortex-A53 应用子系统 APSS 4*Cortex-A57 应用子系统 LPASS QDSP6 v5.5A(Hexa ...
- Cocos2D中相关问题提问的几个论坛
如果和SpriteBuilder相关可以到: http://forum.spritebuilder.com 提问. 如果是Cocos2D的问题,则可以到以下论坛询问: http://forum.coc ...
- Linux下C语言的调试 - gdb
调试是每个程序员都会面临的问题. 如何提高程序员的调试效率, 更好更快地定位程序中的问题从而加快程序开发的进度, 是大家共同面对的问题. 可能Windows用户顺口就会说出:用VC呗 :-) , 它提 ...