python爬虫——词云分析最热门电影《后来的我们》
1 模块库使用说明
1.1 requests库
requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
1.2 urllib库
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应.
1.3jieba库
结巴”中文分词:做最好的 Python 中文分词组件
1.4 BeautifulSoup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。
1.5pandas库
pandas是python的一个非常强大的数据分析库,常用于数据分析。
1.6 re库
正则表达式re(通项公式)是用来简洁表达一组字符串的表达式。优势是简洁。使用它来进行字符串处理。
1.7 wordcloud库
python中使用wordcloud包生成的词云图。我们最后要生成当前热映电影的分析词云。
2需求说明
介绍要做什么,将采用的方法、预期得到的结果是什么及其他需求说明。
爬取豆瓣网站https://movie.douban.com/cinema/nowplaying/ankang/ 城市为安康的豆瓣电影数据主要完成以下三个步骤
抓取网页数据
清理数据
用词云进行展示
使用的python版本是3.6.并使用中文分词,词云对豆瓣电影排行榜排行第一的电影进行数据分析,进行相应的词云展示。
3抓取和处理数据算法
1)安装request模块
1.1)安装需要用到的beautifulsoup模块
2)查看要爬取网站的结构
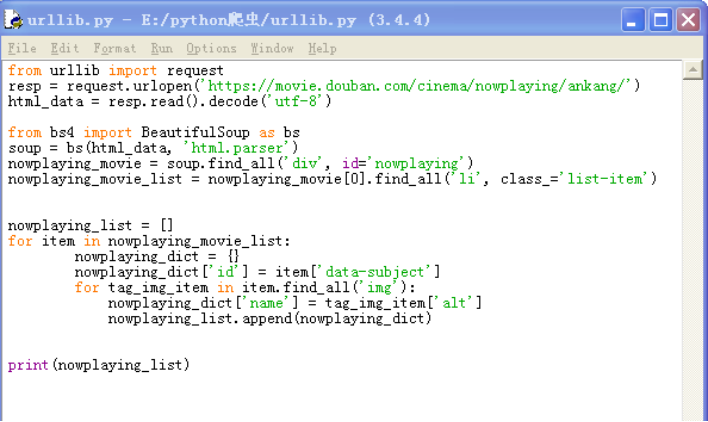
3)初步代码实现
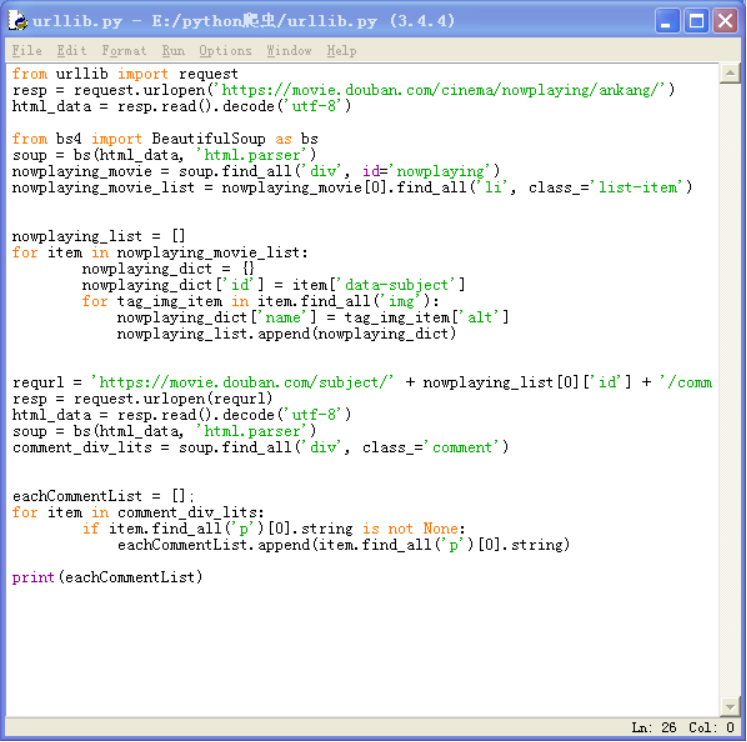
3.1)初步爬取到当前的院线上映信息
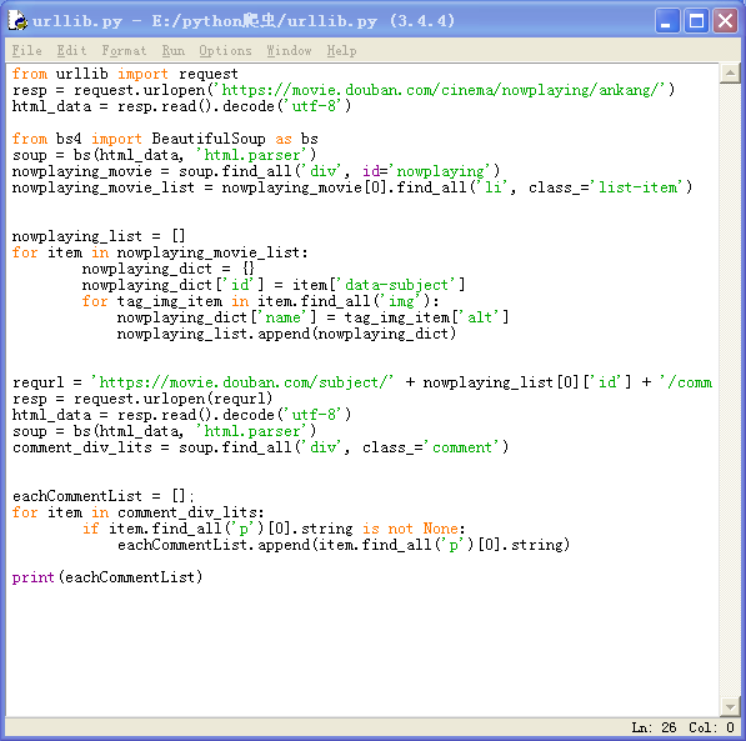
4.1)抓取到热映电影的第一个热评信息代码
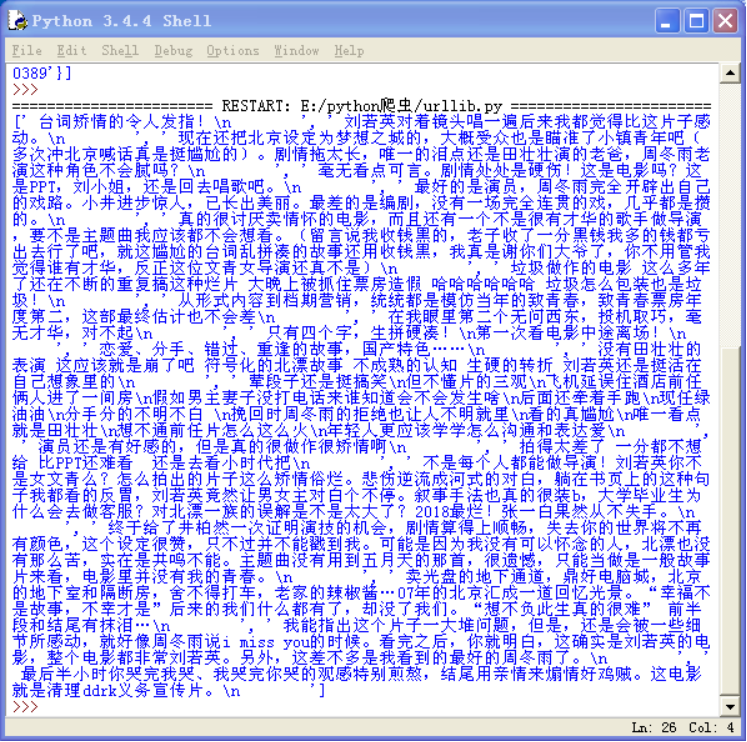
4.2)成功显示热评信息
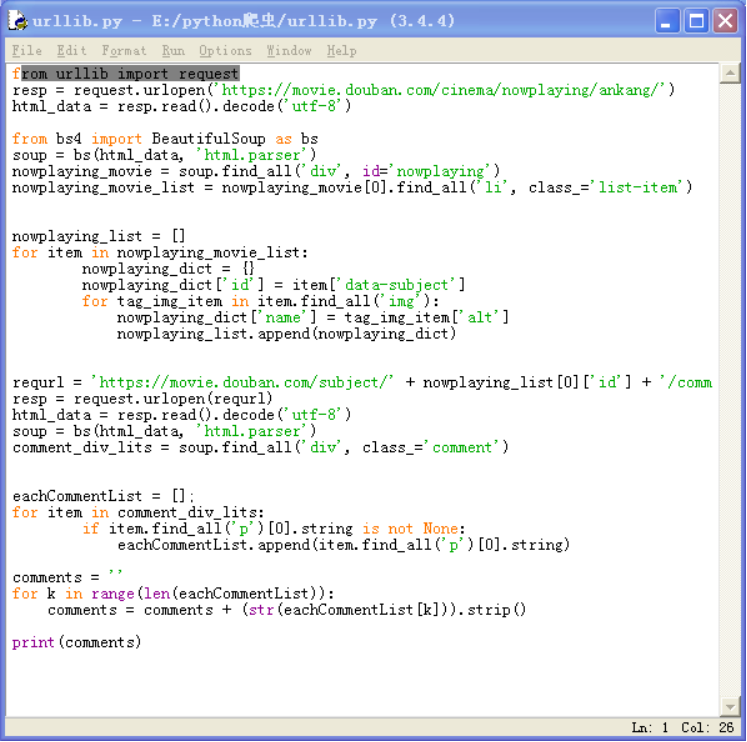
5.1)进行数据清洗上一步中格式错乱的代码
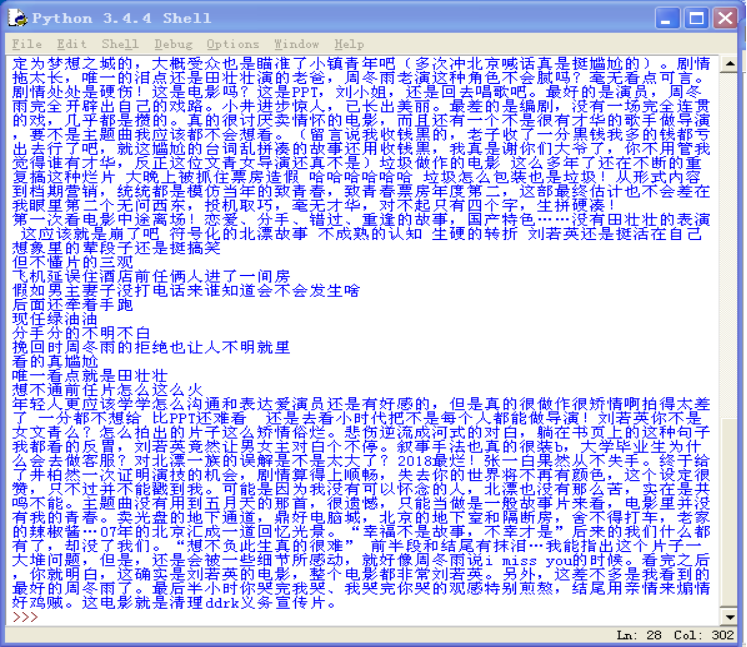
5.2)数据清洗后的《后来的我们》评论信息
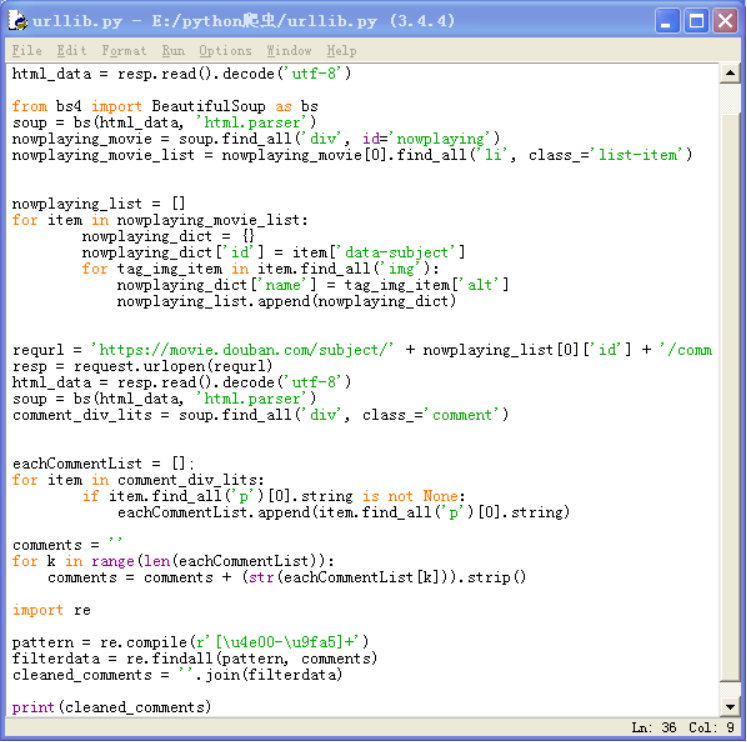
5.3)再次进行数据清洗去除掉标点符号代码
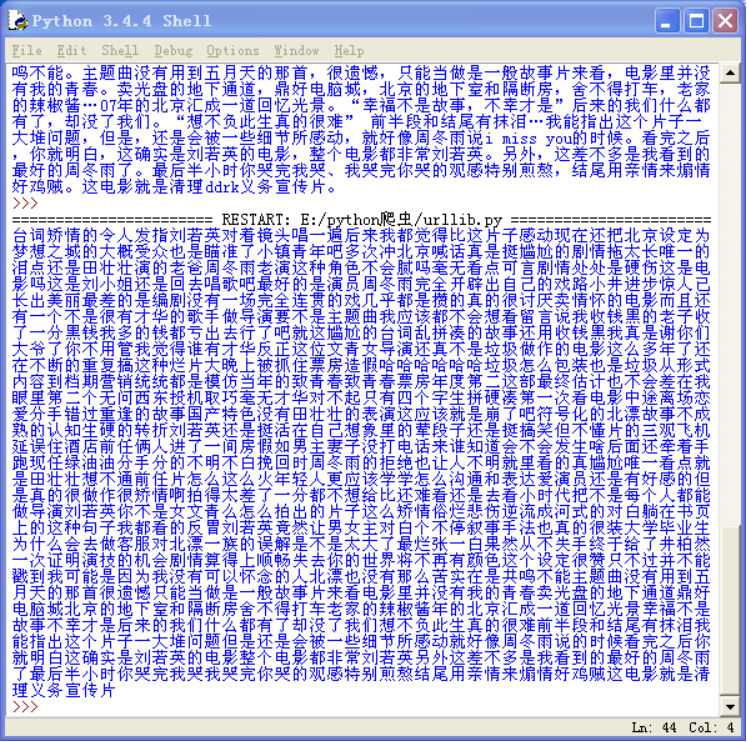
5.4)去除掉标点符号后的数据

6.1)安装pandas模块 ,用此方法依次安装wordcloud 库等。
def main():
# 循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
使用for语句循环遍历获取排行榜第一的电影的前十页评论
完整代码:
# coding:utf-8
__author__ = 'LiuYang'
import warnings
warnings.filterwarnings("ignore")
import jieba # 分词包
import numpy # numpy计算包
import codecs # codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
import re
import pandas as pd
import matplotlib.pyplot as plt
from urllib import request
from bs4 import BeautifulSoup as bs
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
from wordcloud import WordCloud # 词云包
# 分析网页函数
def getNowPlayingMovie_list():
resp = request.urlopen('https://movie.douban.com/nowplaying/ankang/') # 爬取安康地区的豆瓣电影信息
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
return nowplaying_list
# 爬取评论函数
def getCommentsById(movieId, pageNum):
eachCommentList = [];
if pageNum > 0:
start = (pageNum - 1) * 20
else:
return False
requrl = 'https://movie.douban.com/subject/' + movieId + '/comments' + '?' + 'start=' + str(start) + '&limit=20'
print(requrl)
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
return eachCommentList
def main():
# 循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
# 将列表中的数据转换为字符串
comments = ''
for k in range(len(commentList)):
comments = comments + (str(commentList[k])).strip()
# 使用正则表达式去除标点符号
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filterdata = re.findall(pattern, comments)
cleaned_comments = ''.join(filterdata)
# 使用结巴分词进行中文分词
segment = jieba.lcut(cleaned_comments)
words_df = pd.DataFrame({'segment': segment})
# 去掉停用词
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'],
encoding='utf-8') # quoting=3全不引用
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
# 统计词频
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
# 用词云进行显示
wordcloud = WordCloud(font_path="simhei.ttf", background_color="white", max_font_size=80)
word_frequence = {x[0]: x[1] for x in words_stat.head(1000).values}
word_frequence_list = []
for key in word_frequence:
temp = (key, word_frequence[key])
word_frequence_list.append(temp)
wordcloud = wordcloud.fit_words(dict (word_frequence_list))
plt.imshow(wordcloud)
plt.savefig("ciyun_jieguo .jpg")
# 主函数
main()
成功获取到结果
到代码路径获取词云结果图片如图:
词云结果图

4结果分析说明
选取安康地区院线电影排行信息,首先对正在上映的电影进行分析,获得最热门的电影信息,第二步对排行中最热门的电影《后来的我们》进行评论抓取,进行数据清洗,去除掉格式错误的错误信息,去除掉标点,中文的叠词,获取到出现频率最高的词汇,为了保证获取到的词云信息准确性,并且循环遍历十页评论信息,统计计数,再通过词云获取到此电影的词云信息。
由最终获得的词云分析图可知,我们顺利的爬取了安康地区的豆瓣电影信息,影院当前正在上映的电影信息,由此得到热门电影《后来的我们》此电影的特征标签,也基本上反映了这部电影的情况,观影者的感受,电影的主要角色,导演信息等一目了然。
python爬虫——词云分析最热门电影《后来的我们》的更多相关文章
- 如何用Python 制作词云-对1000首古诗做词云分析
公号:码农充电站pro 主页:https://codeshellme.github.io 今天来介绍一下如何使用 Python 制作词云. 词云又叫文字云,它可以统计文本中频率较高的词,并将这些词可视 ...
- 使用Python定制词云
一.实验介绍 1.1 实验内容 在互联网时代,人们获取信息的途径多种多样,大量的信息涌入到人们的视线中.如何从浩如烟海的信息中提炼出关键信息,滤除垃圾信息,一直是现代人关注的问题.在这个信息爆炸的时代 ...
- 如何用Python做词云(收藏)
看过之后你有什么感觉?想不想自己做一张出来? 如果你的答案是肯定的,我们就不要拖延了,今天就来一步步从零开始做个词云分析图.当然,做为基础的词云图,肯定比不上刚才那两张信息图酷炫.不过不要紧,好的开始 ...
- 一步一步教你如何用Python做词云
前言 在大数据时代,你竟然会在网上看到的词云,例如这样的. 看到之后你是什么感觉?想不想自己做一个? 如果你的答案是正确的,那就不要拖延了,现在我们就开始,做一个词云分析图,Python是一个当下很流 ...
- 使用python绘制词云
最近在忙考试的事情,没什么时间敲代码,一个月也没几天看代码,最近看到可视化的词云,看到网上也很多这样的工具, 但是都不怎么完美,有些不支持中文,有的中文词频统计得莫名其妙.有的不支持自定义形状.所有的 ...
- python爬取花木兰豆瓣影评,并进行词云分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资 ...
- 用Python做词云可视化带你分析海贼王、火影和死神三大经典动漫
对于动漫爱好者来说,海贼王.火影.死神三大动漫神作你肯定肯定不陌生了.小编身边很多的同事仍然深爱着这些经典神作,可见"中毒"至深.今天小编利用Python大法带大家分析一下这些神作 ...
- Python 词云分析周杰伦《晴天》
一.前言满天星辰的夜晚,他们相遇了...夏天的时候,她慢慢的接近他,关心他,为他付出一切:秋天的时候,两个人终於如愿的在一起,分享一切快乐的时光但终究是快乐时光短暂,因为杰伦必须出国深造,两人面临了要 ...
- [python] 基于词云的关键词提取:wordcloud的使用、源码分析、中文词云生成和代码重写
1. 词云简介 词云,又称文字云.标签云,是对文本数据中出现频率较高的“关键词”在视觉上的突出呈现,形成关键词的渲染形成类似云一样的彩色图片,从而一眼就可以领略文本数据的主要表达意思.常见于博客.微博 ...
随机推荐
- 并发编程(二):分析Boost对 互斥量和条件变量的封装及实现生产者消费者问题
请阅读上篇文章<并发编程实战: POSIX 使用互斥量和条件变量实现生产者/消费者问题>.当然不阅读亦不影响本篇文章的阅读. Boost的互斥量,条件变量做了很好的封装,因此比" ...
- 采购申请 POCIRM-001:ORA-01403: 未找到任何数据
今天同事让帮忙看一个问题,在销售模块提交销售订单生成采购订单的请求时报错 查看请求日志 +------------------------------------------------------- ...
- go: 一个通用log模块的实现
在go里面,虽然有log模块,但是该模块提供的功能并不强,譬如就没有我们常用的level log功能,但是自己实现一个log模块也并不困难. 对于log的level,我们定义如下: const ( L ...
- Ubuntu 安装 Mysql 5.6 数据库
Ubuntu 安装 Mysql 5.6 数据库 1)下载: mysql-5.6.13-debian6.0-x86_64.deb http://dev.mysql.com/downloads/mirro ...
- mysql的基本使用命令
启动:net start mySql; 进入:mysql -u root -p/mysql -h localhost -u root -p databaseName; 列出数据库:show datab ...
- 【Android 应用开发】Activity 状态保存 OnSaveInstanceState参数解析
作者 : 韩曙亮 转载请著名出处 : http://blog.csdn.net/shulianghan/article/details/38297083 一. 相关方法简介 1. 状态保存方法示例 p ...
- RecyclerView 实现横向滚动效果
我相信很久以前,大家在谈横向图片轮播是时候,优先会选择具有HorizontalScrollView效果和ViewPager来做,不过自从Google大会之后,系统为我们提供了另一个控件Recycler ...
- JAVA之旅(四)——面向对象思想,成员/局部变量,匿名对象,封装 , private,构造方法,构造代码块
JAVA之旅(四)--面向对象思想,成员/局部变量,匿名对象,封装 , private,构造方法,构造代码块 加油吧,节奏得快点了 1.概述 上篇幅也是讲了这点,这篇幅就着重的讲一下思想和案例 就拿买 ...
- 关于学习MMU的一点感想
MMU的一个主要服务是能把各个人物作为各自独立的程序在其自己的虚拟存储空间中运行. 虚拟存储器系统的一个重要特征是地址重定位.地址重定位是将处理器核产生的地址转换到主存的不同地址,转换由MMU硬件完成 ...
- 青年之锋文学网( www.xcqnzf…
青年之锋文学网( www.xcqnzf.com )简介: 青年之锋文学网创建于2013年秋,是河南农业大学(应用科技学院)--青年之锋文学社的官方网站,网站以长篇写作和出版校刊为主题,短篇精彩丰富为中 ...