mysql优化一之查询优化
这一篇笔记的mysql优化是注重于查询优化,根据mysql的执行情况,判断mysql什么时候需要优化,关于数据库开始阶段的数据库逻辑、物理结构的设计结构优化不是本文重点,下次再谈
查看mysql语句的执行情况,判断是否需要进行优化
当感觉操作数据库查询语句速度变慢,不符合生产效率要求时,可按照以下步骤进行查看1、 慢查询的开启与捕获,查看可能是哪些SQL语句造成的查询速度慢2、 explain+SQL语句3、 show profile分析SQL语句在服务器内执行细节和生命周期情况4、 通过以上三个步骤大致确定问题SQL之后,可联系运维人员或者DBA进行数据库服务器参数的调整优化
以下分别通过java程序员可分析的前三个方面来讨论mysql语句的查询优化
一、慢查询
慢查询日志是mysql的一个日志记录,可以用来记录mysql语句执行时间超过指定的long_query_time的SQL语句,long_query_time的默认值是10s
慢查询日志默认情况下是不开启的,因为将数据保存到日志会对性能有一定影响,测试环境下可手动打开,但注意手动开启之后只对本次启动生效,mysql关闭之后重启恢复默认状态,要想持久生效要改变my.ini配置文件(Window系统下),其他系统变量也如此
可通过show varaibles like '%slow_query_log%'来查看日志开启情况
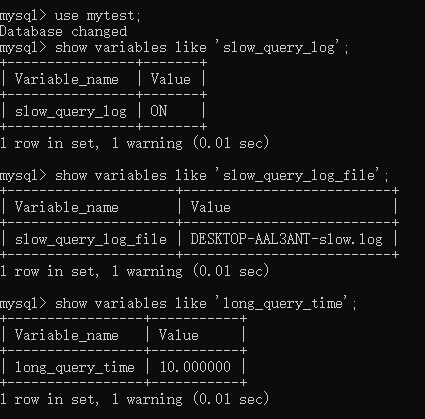
可以用set long_query_time = 3;语句来改变默认的阀值,然后我们可以用show varaiables like 'long_query_
time'来查看是否更改生效,若没有生效,可尝试重启一下mysql客户端即可
然后我们现在来测试一下,因为我们平时个人测试学习的数据库及其简单的SQL语句可能没有造成很慢的查询,我们可以采用 select sleep(time)来模拟测试
(这个函数类似于java线程中的sleep函数)
执行该函数之前slow.log文件:

执行sleep(4)函数,因为要让你设置的这个time大于记录到日志里面的时间阀值


可已看到这条慢查询话费的具体时间是4.041230,也可以看到是哪个用户在哪个数据库操作的哪条具体SQL语句,我们开启慢查询日志的目的就是找到这样的造成查速度减慢的SQL语句,为第二步的explain提供基础
mysqldumpslow日志分析工具
在实际的数据库使用过程中可能会有多条日志记录,数据复杂,人工分析费事费力,mysql提供了一个日志分析工具mysqldumpslow
可以根据你设定的参数查询出满足条件的日志记录,方便查看
可用的参数有-s, 是表示按照何种方式排序排序方式有c: 访问计数l: 锁定时间r: 返回记录t: 查询时间al:平均锁定时间ar:平均返回记录数at:平均查询时间-t, 是top n的意思,即为返回前面多少条的数据;-g, 后边可以写一个正则匹配模式,大小写不敏感的;
示例
得到返回记录集最多的10个SQL。
mysqldumpslow -s r -t 10 /database/mysql/mysql06_slow.log
得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /database/mysql/mysql06_slow.log
得到按照时间排序的前10条里面含有左连接的查询语句。
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/mysql06_slow.log
另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现刷屏的情况。
mysqldumpslow -s r -t 20 /mysqldata/mysql/mysql06-slow.log | more
二、explain+SQL语句
执行这个语句可以让开发人员看到select语句执行的详细信息,开发人员可以将上一步慢查询中捕获的慢查询SQL语句进行分析,判断查询效率低的可能原因
可以帮助选择更好的索引和写出优化的查询语句
使用explain我们可以得到以下信息
表的读取顺序
数据读取操作的类型
哪些索引可以使用
哪些索引实际被使用
表之间的引用
每张表有多少行被优化器扫描
示例

我们来逐个分析各字段
id:select查询的序列号,代表的是select执行的顺序,主要有以下三种情况
id相同时,则按照从上到下依次执行id不同时,id值越大优先级越高,越先被执行id有相同有不同,则相同的id为一个组,不同组的id值按照规则二的优先级执行,同组id则按照规则一依次执行
select_type:select查询的类型,有以下常用几种
simple:表示该查询没有子查询和UNION连接查询primary:有子查询时的最外层查询subquery:有子查询时的内层嵌套查询derived:在from中包含的select就称为derived(衍生) ,mysql会递归这些子查询,把结果放在临时表中union:union的第二个或者最后一个union result:union的结果
table:执行当前SQL语句用到的表
partitions:代表当前表所使用的分区
type:显示使用了何种查询,按照常见的几种查询最好到最坏排序为system>const>eq_ref>ref>range>index>all
system,const:mysql能够对这部分进行查询优化使能够将其转换成一个常量(system只返回一行,const有多行),如某一行的主键放入WHERE子句里的方式来选取此行的主键,MySQL就能将这个查询转换成一个常量。然后就可以高效的将表从联接执行中移除eq_ref:使用该索引查找,mysql知道最多返回一条数据,可以在使用主键或者唯一性索引查找时用到ref:非唯一性索引的索引查找range:范围扫描,例如带有between或者>,<,in等index:扫描所有索引行all:扫描所有数据行
possible_keys/kesy:代表可能用到的索引和实际用到的索引
key_len:在索引中使用的字节数
ref:显示了之前的表在key列记录的索引中查找值所用的列或常量
rows:mysq估计的要找到满足条件的行所需要扫描的行数
filtered:给出了一个百分比的值,这个百分比的值和rows列的值一起使用,可以估计出那些将要和QEP中的前一个表进行连接的行的数目。前一个表就是指id列的值比当前表的id小的表
extra:给出一些额外但重要的信息,常见重要的信息有
using index:使用了覆盖索引,以避免扫描表(良好情况)using filesort:索引创建数据排序方式不满足要求,mysql在外部重新排序(严重,需要优化)using temporary:mysql创建使用了临时表来保存信息(严重,需要优化)using where:使用了whereusing join buffer:在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果(需要增加索引进行优化)
这个里面我们需要重点关注的属性是type,keys,row,extra来判断是否为一个良好的查询
更多栗子及分析见下一篇文章索引详解
三、show profile
show profile是mysql用来分析SQL查询语句的资源使用情况的工具
使用方法:
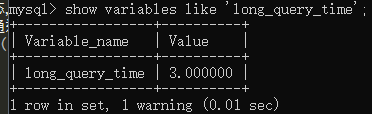
1、 因为mysql这个功能默认是关闭的,所以先查看一下并开启

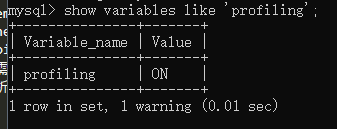
(与开启慢查询日志类似,可能需要重启mysql客户端才能生效)
2、 我们执行一些测试的SQL语句之后运行show profiles语句
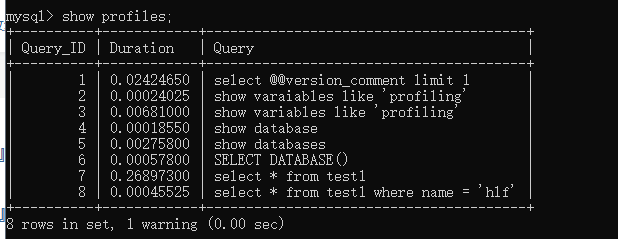
3、 我们可以选择指定项指定SQL语句来分析

一般我们查看的属性就是cpu和block io两个模块
注意:
若出现以下任意一个情况,都表示这是一个糟糕的SQL语句,需要优化
1、 convering heap to MyIsam查询结果过大,内存不够,需要记录到磁盘上
2、 creating tmp table创建临时表储存数据,用完之后删除
3、 copying to tmp table on disk将临时表中的数据储存到磁盘上
4、 locked
mysql优化一之查询优化的更多相关文章
- 3.MySQL优化---单表查询优化的一些小总结(非索引设计)
整理自互联网.摘要: 接下来这篇是查询优化.其实,大家都知道,查询部分是远远大于增删改的,所以查询优化会花更多篇幅去讲解.本篇会先讲单表查询优化(非索引设计).然后讲多表查询优化.索引优化设计以及库表 ...
- Mysql优化系列之查询优化干货1
从这一篇开始,准备总结一些直接受用的sql语句优化,写sql是第二要紧的,第一要紧的,是会分析怎么查最快, 因为当你写过很多sql后,查询出结果已经不是目标,快,才是目标.另外,通过测试和比较的结果才 ...
- 4.MySQL优化---多表查询优化
整理自互联网 一.多表查询连接的选择: 相信这内连接,左连接什么的大家都比较熟悉了,当然还有左外连接什么的,基本用不上我就不贴出来了.这图只是让大家回忆一下,各种连接查询. 然后要告诉大家的是,需要 ...
- MySql学习(六) —— 数据库优化理论(二) —— 查询优化技术
逻辑查询优化包括的技术 1)子查询优化 2)视图重写 3)等价谓词重写 4)条件简化 5)外连接消除 6)嵌套连接消除 7)连接消除 8)语义优化 9)非SPJ优化 一.子查询优化 1. ...
- MySQL优化 - 性能分析与查询优化(转)
出处: MySQL优化 - 性能分析与查询优化 优化应贯穿整个产品开发周期中,比如编写复杂SQL时查看执行计划,安装MySQL服务器时尽量合理配置(见过太多完全使用默认配置安装的情况),根据应用负载 ...
- Mysql单表访问方法,索引合并,多表连接原理,基于规则的优化,子查询优化
参考书籍<mysql是怎样运行的> 非常推荐这本书,通俗易懂,但是没有讲mysql主从等内容 书中还讲解了本文没有提到的子查询优化内容, 本文只总结了常见的子查询是如何优化的 系列文章目录 ...
- mysql系列八、mysql数据库优化、慢查询优化、执行计划分析
mysql的性能优化无法一蹴而就,必须一步一步慢慢来,从各个方面进行优化,最终性能就会有大的提升. 一.介绍 对mysql优化是一个综合性的技术,主要包括 表的设计合理化(符合3NF) 添加适当索引( ...
- Mysql优化系列(2)--通用化操作梳理
前面有两篇文章详细介绍了mysql优化举措:Mysql优化系列(0)--总结性梳理Mysql优化系列(1)--Innodb引擎下mysql自身配置优化 下面分类罗列下Mysql性能优化的一些技巧,熟练 ...
- [转] MySql 优化 大数据优化
一.我们可以且应该优化什么? 硬件 操作系统/软件库 SQL服务器(设置和查询) 应用编程接口(API) 应用程序 ------------------------------------------ ...
随机推荐
- 关于<input type="date">这种取值的问题 【原创】
举例 <input type="date" id="date1"> var num = $("#date1").val(); a ...
- linxu安装SNMP
http://wiki.jiankongbao.com/doku.php/%E6%96%87%E6%A1%A3:%E5%AE%89%E5%85%A8%E6%8C%87%E5%BC%95#linux_s ...
- http_server.go
, fmt.Sprintf("%s: closing %s", proto, listener.Addr())) }
- bzoj 2724 蒲公英 分块
分块,预处理出每两个块范围内的众数,然后在暴力枚举块外的进行比较 那么怎么知道每一个数出现的次数呢?离散后,对于每一个数,维护一个动态数组就好了 #include<cstdio> #inc ...
- BZOJ_4002_[JLOI2015]有意义的字符串_矩阵乘法
BZOJ_4002_[JLOI2015]有意义的字符串_矩阵乘法 Description B 君有两个好朋友,他们叫宁宁和冉冉.有一天,冉冉遇到了一个有趣的题目:输入 b;d;n,求 Input 一行 ...
- "unresolved reference 'appium' "问题解决
根据github的教程安装好"Appium-Python-Client"后,代码里写入"from appium import webdriver"就报错&quo ...
- [转]现代Linux系统上的栈溢出攻击
1. 基本内容 这个教程试着向读者展示最基本的栈溢出攻击和现代Linux发行版中针对这种攻击的防御机制.为此我选择了最新版本的Ubuntu系统(12.10),因为它默认集成了几个安全防御机制,而且它也 ...
- 8天入门docker系列 —— 第四天 使用aspnetcore小案例熟悉端口映射和挂载目录
到目前为止大家应该对镜像和容器有了一个大概认知,而且也用了docker进行了一个简单化的部署,但仔细一看问题还有很多,所以这篇我们继续完善. 一:如何让外网访问到容器内应用 我们知道容器内拥有自己的子 ...
- Java实现大批量数据导入导出(100W以上) -(一)导入
最近业务方有一个需求,需要一次导入超过100万数据到系统数据库.可能大家首先会想,这么大的数据,干嘛通过程序去实现导入,为什么不直接通过SQL导入到数据库. 大数据量报表导出请参考:Java实现大批量 ...
- WebApi管理和性能测试工具WebApiBenchmarks
说到WebApi管理和测试工具其实已经非常多的了,Postman.Swagger等在管理和维护上都非常出色:在性能测试方面也有不少的工具如:wrk,bombardier,http_load和ab等等. ...