并发编程(四):atomic
本篇博客我们主要讲述J.U.C包下的atomic包,在上篇博客“并发模拟”的最后,我们模拟高并发的情形时出现了线程安全问题,怎么解决呢?其实解决的办法有很多中,如直接在add()方法上加synchronized关键字,还有一种就是用atomic包下的类来解决这个问题,这也是现在比较推荐的一种写法,下面我们给出完整代码:
@Slf4j
public class CountExample2 { //请求总数
public static int clientTotal = 5000;
//同时并发执行的线程数
public static int threadTotal = 200; public static AtomicInteger count = new AtomicInteger(0); private static void add() {
count.incrementAndGet();
// count.getAndIncrement();
} public static void main(String[] args)throws Exception { //定义线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//定义信号量
final Semaphore semaphore = new Semaphore(threadTotal);
//定义计数器闭锁
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception",e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}",count.get());
}
}
输出结果如下:

由输出结果可知,我们已经保证了线程安全(如果对此demo有不解的地方可参考“并发编程(三)”),在这个demo中就是AtomicInteger发挥了作用,下面我们来系统的了解一下atomic包下的类。
atomic包
java8中,在atomic包中一共有17个类,其中有12个类是jdk1.5提供atomic时就有的,5个类是jdk1.8新加的。在原有的12个类中包含四种原子更新方式,分别是原子更新基本类型,原子更新数组,原子更新引用,原子更新字段(下面我会在每种类型中,选择某个类为代表以代码进行演示)

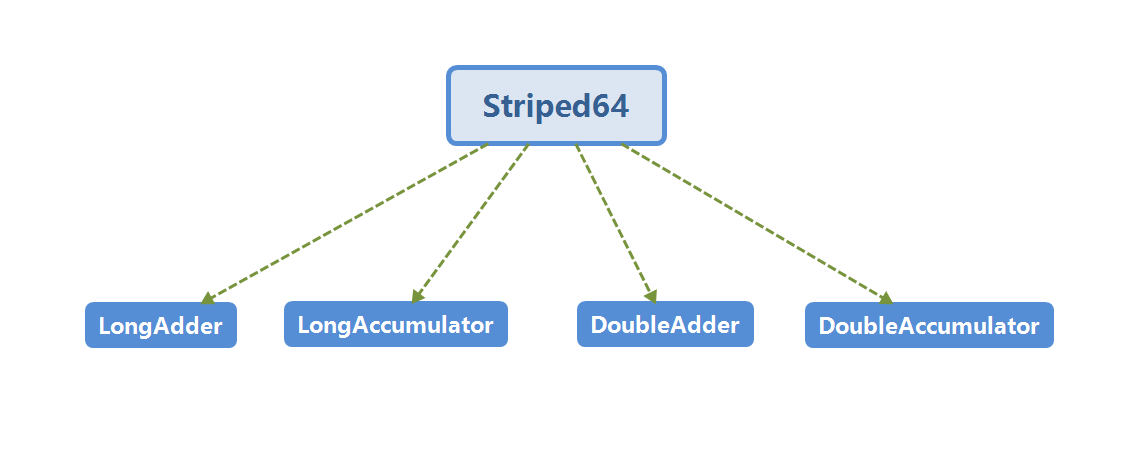
java8新增的5个类分别是Striped64,LongAdder,LongAccumulator,DoubleAdder,DoubleAccumulator,Sriped64作为父类,其余四个类继承此类,分别是long和double的具体实现
原子更新基本类型
通过原子的方式更新基本类型。以AtomicInteger为代表进行演示
AtomicInteger的常用方法如下:
int addAndGet(int delta):以原子的方式将输入的数值与实例中的值相加,并返回结果
boolean compareAndSet(int expect,int update):如果输入的数值等于预期值,则以原子方式将该值设置为输入的值
int getAndIncrement():以原子方式将当前值加1,并返回自增前的值
void lazySet(int newValue):最终设置为newValue,使用lazySet设置后,可能导致其他线程在一小段时间内还是可以读到旧的值
int getAndSet(int newValue):以原子的方式设置为newValue的值,并返回旧值
本篇博客开始的demo就是运用AtomicInteger的例子
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerTest {
static AtomicInteger ai = new AtomicInteger(1);
public static void main(String[] args) {
System.out.println(ai.getAndIncrement());
System.out.println(ai.get());
}
}
输出分别为1,2
AtomicLong-demo
@Slf4j
public class AtomicExample2 { //请求总数
public static int clientTotal = 5000;
//同时并发执行的线程数
public static int threadTotal = 200; public static AtomicLong count = new AtomicLong(0); private static void add() {
//主要为此方法(看源码)
count.incrementAndGet();
// count.getAndIncrement();
} public static void main(String[] args)throws Exception { //定义线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//定义信号量
final Semaphore semaphore = new Semaphore(threadTotal);
//定义计数器闭锁
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception",e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}",count.get());
}
}
输出为5000,用法与AtomicInteger类似
AtomicBoolean-demo
@Slf4j
public class AtomicExample6 { private static AtomicBoolean isHappened = new AtomicBoolean(false);
//请求总数
public static int clientTotal = 5000;
//同时并发执行的线程数
public static int threadTotal = 200; public static void main(String[] args) throws Exception{ //定义线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//定义信号量
final Semaphore semaphore = new Semaphore(threadTotal);
//定义计数器闭锁
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
test();
semaphore.release();
} catch (Exception e) {
log.error("exception",e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("isHappened:{}",isHappened.get());
} private static void test() { //原子性操作,从false变为true只会执行一次
if (isHappened.compareAndSet(false, true)) {
log.info("execute");
}
}
}
test()方法中将isHappened从false变为true只会执行一次。
原子更新数组类
通过原子的方式更新数组里的某个元素。我们以AtomicIntegerArray(提供原子的方式更新数组里的整型)为例进行演示,其常用方法如下:
int addAndGet(int i,int delta):以原子的方式将输入值与数组中索引i的元素相加
boolean compareAndSet(int i,int expect,int update):如果当前值等于预期值,则以原子方式将数组位置i的元素设置成update值
AtomicIntegerArray-demo
public class AtomicIntegerArrayTest {
static int[] value = new int[] { 1, 2 };
static AtomicIntegerArray ai = new AtomicIntegerArray(value);
public static void main(String[] args) {
ai.getAndSet(0, 3);
System.out.println(ai.get(0));
System.out.println(value[0]);
}
}
输出结果分别为3,1 ,为什么value[0]的值为1呢?因为数组value通过构造方法传递进去之后,AtomicIntegerArray会将此数组复制一份,所以当AtomicIntegerArray对内部数组元素进行修改时不会影响传入的数组。
原子更新引用类型
AtomicReference:原子更新引用类型
AtomicReferenceFieldUpdater:原子更新引用类型的字段
AtomicMarkableReference:原子更新带有标记位的引用类型,可以原子的更新一个布尔类型的标记位和引用类型。
AtomicReference-demo1
class AtomicReferenceTest {
public static AtomicReference<User> atomicUserRef = new AtomicReference<User>();
public static void main(String[] args) {
User user = new User("conan", 15);
atomicUserRef.set(user);
User updateUser = new User("xiaoming", 18);
atomicUserRef.compareAndSet(user, updateUser);
System.out.println(atomicUserRef.get().getName());
System.out.println(atomicUserRef.get().getOld());
}
static class User {
private String name;
private int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
}
输出为:“xiaoming”,18 我们可以结合上篇博客“并发模拟”中,模拟高并发环境,观察原子更新引用类型与非原子更新的区别
AtomicReference-demo2
@Slf4j
public class AtomicExample4 { private static AtomicReference<Integer> count = new AtomicReference<>(0); public static void main(String[] args) { count.compareAndSet(0, 2); //
count.compareAndSet(0, 1); //no
count.compareAndSet(1, 3); //no
count.compareAndSet(2, 4); //
count.compareAndSet(3, 5); //no log.info("count:{}", count.get());
}
}
上述代码输出结果为4,因为只有第一句和第二句代码得到执行,具体原因可参考下篇博客cas相关的内容
原子更新字段类
AtomicIntegerFiledUpdater:原子更新整型的字段的更新器
AtomicLongFiledUpdater:原子更新长整型字段的更新器
AtomicStampedReference:原子更新带有版本号的引用类型,该类将整数值与引用关联起来,可原子的更数据和数据的版本号,可以解决使用cas进行原子更新时,可能出现的aba问题,原子更新字段类都是抽象类,每次使用都必须使用静态方法newUpdater创建一个更新器,原子更新类的字段必须使用public volatile修饰,我们以AtomicIntergerFieldUpdater为例进行演示
AtomicIntergerFieldUpdater-demo1
public class AtomicIntegerFieldUpdaterTest {
private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater
.newUpdater(User.class, "old");
public static void main(String[] args) {
User conan = new User("conan", 10);
System.out.println(a.getAndIncrement(conan));
System.out.println(a.get(conan));
}
public static class User {
private String name;
public volatile int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
}
输出为10,11
AtomicIntergerFieldUpdater-demo2
@Slf4j
public class AtomicExample5 { //更新某个类的某一字段的值
private static AtomicIntegerFieldUpdater<AtomicExample5> updater = AtomicIntegerFieldUpdater.newUpdater(AtomicExample5.class, "count"); //这个字段必须要用volatile修饰,并且是非static字段才可以
@Getter
public volatile int count = 100; private static AtomicExample5 example5 = new AtomicExample5(); public static void main(String[] args) {
if (updater.compareAndSet(example5,100,120)) {
log.info("update success 1,{}", example5.getCount());
}
if (updater.compareAndSet(example5, 100, 120)) {
log.info("update success 2,{}", example5.getCount());
} else {
log.info("update failed,{}", example5.getCount());
}
}
}
输出如下:

我们同样可以发现,“update success 2”没有执行,这也涉及到了cas的基本原理,我会在下篇博客具体介绍
下面我们看一下在atomic包中新增的5个类:
Striped64
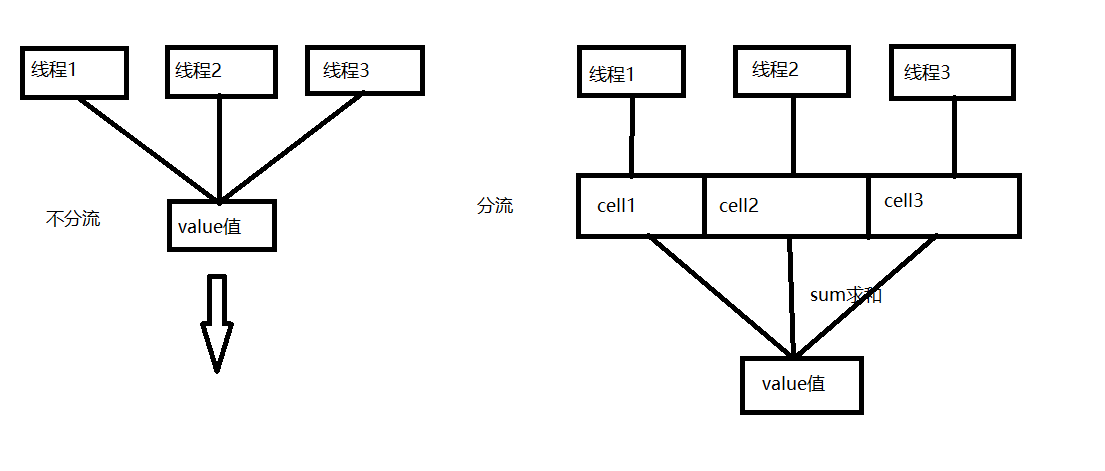
Striped64里面维持一个volatile的base,还有一个cell数据,cell数组主要存储线程需要增加或减少的值,它能够将竞争的线程分散到自己内部的私有cell数组里面,所以当并发量很大的时候,线程会被部分分发去访问内部的cell数组。Striped64里面有两个主要的方法longAccumulate和doubleAccumulate,两个方法非常相似。实现的主要思路是如果能通过cas修改base成功,那么直接退出(并发量不大的时候),否则去cells里面占一个非空的空(并发量大的时候),并把要操作的值赋值保存在一个cell里面,这样在并发特别高的时候可能将热点分离
LongAdder
当并发量不高时,LongAdder和AtomicLong性能差不多,但是当并发超过一定限度,cas会频繁失败,对于AtomicLong没有其他解决办法,对于LongAdder则可以通过cells数组来进行部分分流操作。LongAdder使用的思想是热点分离,就是将value值分离成一个数组,当多线程访问时通过hash算法映射到其中一个数字进行计数,最终的结果就是这些数组的求和累加,这样一来减小了锁的粒度。LongAdder一开始不会直接使用cell []存储,而是先使用long类型的base存储,当casBase()出现失败时,则会创建cell[],如果在单个cell上面出现了cell更新冲突,则会尝试创建新的cell或将cell[]扩容为2倍。 LongAdder中的方法如下:
void add(long x):增加x
void increment():自增1
void decrement():自减1
long sum():求和
void reset():重置cell数组
long sumThenReset():求和并重置
LongAdder-demo1
@Slf4j
@ThreadSafe
public class AtomicExample3 { //请求总数
public static int clientTotal = 5000;
//同时并发执行的线程数
public static int threadTotal = 200; //与AtomicLong的区别是,可以将热点分离,在并发特别高的时候可能提高性能,在并发不是特别高的时候可以用atomiclong(序列化生成,全局唯一也可以用这个)(再去查)
public static LongAdder count = new LongAdder(); private static void add() {
count.increment();
// count.getAndIncrement();
} public static void main(String[] args)throws Exception { //定义线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//定义信号量
final Semaphore semaphore = new Semaphore(threadTotal);
//定义计数器闭锁
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception",e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}",count); }
}
输出为5000,没有出现线程安全问题
LongAccumulator
LongAccumulator是LongAdder的功能增强版,LongAdd的api只是对数值的加减,而LongAccumulator提供了自定义的函数操作
LongAccumulator-demo
public class LongAccumulatorDemo {
public static void main(String[] args)throws InterruptedException {
LongAccumulator accumulator = new LongAccumulator(Long::max, Long.MIN_VALUE);
Thread[] ts = new Thread[1000];
for (int i = 0; i < 1000; i++) {
ts[i] = new Thread(() ->{
Random random = new Random();
long value = random.nextLong();
//比较value和上一次的比较值,存储较大值
accumulator.accumulate(value);
});
ts[i].start();
}
//使用join方法,等到所有的线程结束后再执行下面的代码
for (int i = 0; i < 1000; i++) {
ts[i].join();
}
System.out.println(accumulator.longValue());
}
}
上述代码作用为accumulate(value)传入的值会与上一次比较值对比,保留较大者
DoubleAdder与DoubleAccumulator
这两个类的实现思路与long类型的实现一致,只是将double转为long类型后运算的。
并发编程(四):atomic的更多相关文章
- 【Java并发编程四】关卡
一.什么是关卡? 关卡类似于闭锁,它们都能阻塞一组线程,直到某些事件发生. 关卡和闭锁关键的不同在于,所有线程必须同时到达关卡点,才能继续处理.闭锁等待的是事件,关卡等待的是其他线程. 二.Cycli ...
- Java 并发编程(四):如何保证对象的线程安全性
01.前言 先让我吐一句肺腑之言吧,不说出来会憋出内伤的.<Java 并发编程实战>这本书太特么枯燥了,尽管它被奉为并发编程当中的经典之作,但我还是忍不住.因为第四章"对象的组合 ...
- Go并发编程(四)
并发基础 多进程 多线程 基于回调的非阻塞/异步IO 协程 协程 与传统的系统级线程和进程相比,协程的最大优势在于其“轻量级”,可以轻松创建上百万个而不会导致系统资源衰竭, ...
- 并发编程>>四种实现方式(三)
概述 1.继承Thread 2.实现Runable接口 3.实现Callable接口通过FutureTask包装器来创建Thread线程 4.通过Executor框架实现多线程的结构化,即线程池实现. ...
- Java并发编程 (四) 线程安全性
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.线程安全性-原子性-atomic-1 1.线程安全性 定义: 当某个线程访问某个类时,不管运行时环境 ...
- Java并发编程(四):并发容器(转)
解决并发情况下的容器线程安全问题的.给多线程环境准备一个线程安全的容器对象. 线程安全的容器对象: Vector, Hashtable.线程安全容器对象,都是使用 synchronized 方法实现的 ...
- 并发编程从零开始(十一)-Atomic类
并发编程从零开始(十一)-Atomic类 7 Atomic类 7.1 AtomicInteger和AtomicLong 如下面代码所示,对于一个整数的加减操作,要保证线程安全,需要加锁,也就是加syn ...
- 并发编程(四):ThreadLocal从源码分析总结到内存泄漏
一.目录 1.ThreadLocal是什么?有什么用? 2.ThreadLocal源码简要总结? 3.ThreadLocal为什么会导致内存泄漏? 二.ThreadLoc ...
- java并发编程的艺术——第四章总结
第四章并发编程基础 4.1线程简介 4.2启动与终止线程 4.3线程间通信 4.4线程应用实例 java语言是内置对多线程支持的. 为什么使用多线程: 首先线程是操作系统最小的调度单元,多核心.多个线 ...
随机推荐
- UNIX网络编程——sockatmark函数
每当收到一个带外数据时,就有一个与之关联的带外标记.这是发送进程发送带外字节时该字节在发送端普通数据流中的位置.在从套接字读入期间,接收进程通过调用sockatmark函数确定是否处于带外标记. #i ...
- 网站开发进阶(三十五)JSP页面中的pageEncoding和contentType两种属性
JSP页面中的pageEncoding和contentType两种属性 本文介绍了在JSP页面中经常用的两种属性,分别是pageEncoding和contentType,希望对你有帮助,一起来看. 关 ...
- Linux IPC实践(7) --Posix消息队列
1. 创建/获取一个消息队列 #include <fcntl.h> /* For O_* constants */ #include <sys/stat.h> /* For m ...
- Java对象引用处理机制
翻译人员: 铁锚 翻译时间: 2013年11月13日 原文链接: How does Java handle aliasing? 什么是Java的引用别名机制 Java的引用别名机制(原文为Aliasi ...
- java 二进制数字符串转换工具类
java 二进制数字符串转换工具类 将二进制转换成八进制 将二进制转换成十进制 将二进制转换成十六进制 将十进制转换成二进制 package com.iteye.injavawetrust.ad; i ...
- ORA-04091错误原因与解决方法
最近工作中写了一触发器报错:ORA-04091:table XX is mutating, trigger/function may not see it. 下面通过官方文档及网友提供资料分析一下错 ...
- myBatis源码之BatchExecutor
BatchExecutor是实现批处理操作,会将根据相同操作通过判断sql语句和MappedStatement来将执行放到List中,来执行批处理操作. /** * @author Jeff Butl ...
- ConcurrentHashMap和HashTable的区别
hashtable是做了同步的,hashmap未考虑同步.所以hashmap在单线程情况下效率较高.hashtable在的多线程情况下,同步操作能保证程序执行的正确性. 但是hashtable每次同步 ...
- MPLSVPN 命令集
载请标明出处:http://blog.csdn.net/sk719887916,作者:skay 读懂下面配置命令需要有一定的TCP/IP,路由协议基础,现在直接上关键VPN命令. router ...
- (十七)TableView的本地性能优化
面试中常常会问TableView的性能优化. TableView只会加载能看到的Cell,每当有一个Cell进入视野范围内,就会调用. 存在着内存隐患,如果用户拖动的很快,所以内存会飙升的很快,因此要 ...