[CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
p.p3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 16.0px "Helvetica Neue"; color: #323333 }
p.p4 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333; min-height: 16.0px }
p.p5 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px STIXGeneral; color: #323333 }
p.p6 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px STIXGeneral; color: #323333 }
p.p7 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px "Helvetica Neue"; color: #323333; min-height: 20.0px }
p.p8 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px STIXSizeOneSym; color: #323333 }
p.p9 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 17.0px STIXGeneral; color: #323333 }
p.p10 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 14.0px "Helvetica Neue"; color: #323333 }
p.p11 { margin: 0.0px 0.0px 0.0px 0.0px; font: 9.0px STIXGeneral; color: #323333 }
li.li2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
span.s1 { text-decoration: underline }
span.s2 { }
span.s3 { vertical-align: -0.5px }
span.s4 { vertical-align: -9.0px }
ul.ul1 { list-style-type: disc }
ul.ul2 { list-style-type: circle }
https://www.csee.umbc.edu/~hpirsiav/papers/cascade_cvpr17.pdf
Weakly Supervised Cascaded Convolutional Networks, Ali Diba, Vivek Sharma, Ali Pazandeh, Hamed Pirsiavash and Luc Van Gool
亮点
- 通过多任务叠加(分类,分割)提高了多物体弱监督检测的正确率
- 通过利用segmentation筛选纯净的proposals,得到了更鲁棒的结果
- 为弱监督分割任务设计比较鲁棒的loss
- 只考虑全局的分类结果和置信度对高的部分
- 通过loss的weights关注到最需要关注的部分
相关工作
One of the most common approaches [7] consists of the following steps:
- generates object proposals,
- extracts features from the proposals,
- applies multiple instance learning (MIL) to the features and finds the box labels from the weak bag (image) labels.
弱监督物体检测难点: 弱监督物体检测对初始化要求很高,不好的初始化可能会使网络陷入局部最优解,解决的办法主要有以下几个:
- improve the initialization [31, 9, 28, 29]
- regularizing the optimization strategies [4, 5, 7]
- [17] employ an iterative self-learning strategy to employ harder samples to a small set of initial samples
- [15] use a convex relaxation of soft-max loss
Majority of the previous works [25, 32] use a large collection of noisy object proposals to train their object detector. In contrast, our method only focuses on a very few clean collection of object proposals that are far more reliable, robust, computationally efficient, and gives better performance
方法
Two-stage: proposal and image classification (conv1 till con5, global pooling) + multiple instance learning (2fc, score layer)

1. image classification: CNN with global average pooling (GAP) [36]中引入,将分类过程中fc层的weights作为原来convolutional layer输出的权重并将所有频道加权得到的图作为class activation map。在这一步中,还产生一个分类的loss LGAP
[36] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In CVPR, 2016. 3, 4, 5, 6, 7, 8
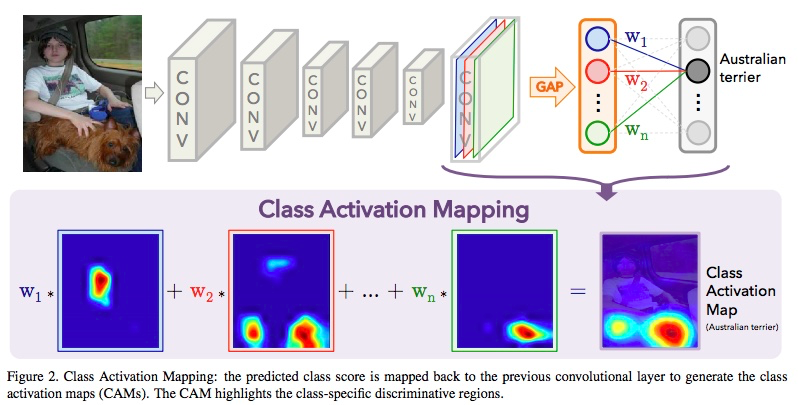
2. multiple instance learning
Proposal: edgeboxs [37] is used to generate an initial set of object proposals. Then we threshold the class activation map [36] to come up with a mask. Finally, we choose the initial boxes with largest overlap with the mask.

Three-stage: more information about the objects’ boundary learned in a segmentation task can lead to acquisition of a better appearance model and then better object localization.
- 主要思想:分割监督信号帮助提升定位准确率。
- 弱分割监督信号:上一级得到的mask


实验结果
PASCAL VOC 2007
- +3.3% classification compared with [18]
- +1.6% correct localization compared with [27]
- +0.6% compared with [6]
PASCAL VOC 2010
- +3.3% compared with [6]
PASCAL VOC 2012
- +8.8% compared with [18]
- ILSVRC 2013
- +5.5% compared with [18]
Object detection training
- PASCAL VOC 2007 test set: Faster RCNN trained by the pseudo ground-truth (GT) bounding boxes generated by our cascaded networks performs slightly better than our transfered model. (+0.3%)
[6] H. Bilen and A. Vedaldi. Weakly supervised deep detection networks. In CVPR, 2016. 6, 7, 8
[18] D. Li, J.-B. Huang, Y. Li, S. Wang, and M.-H. Yang. Weakly supervised object localization with progressive domain adaptation. In IEEE Conference on Computer Vision and Pattern Recognition, 2016. 2, 6, 7
[27] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 5, 6
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 16.0px "Helvetica Neue"; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
li.li2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
span.s1 { }
ul.ul1 { list-style-type: disc }
ul.ul2 { list-style-type: circle }
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
p.p3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 16.0px "Helvetica Neue"; color: #323333 }
p.p4 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333; min-height: 16.0px }
p.p5 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px STIXGeneral; color: #323333 }
p.p6 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px STIXGeneral; color: #323333 }
p.p7 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px "Helvetica Neue"; color: #323333; min-height: 20.0px }
p.p8 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px STIXSizeOneSym; color: #323333 }
p.p9 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 17.0px STIXGeneral; color: #323333 }
p.p10 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 14.0px "Helvetica Neue"; color: #323333 }
p.p11 { margin: 0.0px 0.0px 0.0px 0.0px; font: 9.0px STIXGeneral; color: #323333 }
li.li2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
span.s1 { text-decoration: underline }
span.s2 { }
span.s3 { vertical-align: -0.5px }
span.s4 { vertical-align: -9.0px }
ul.ul1 { list-style-type: disc }
ul.ul2 { list-style-type: circle }
[CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记的更多相关文章
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- [论文阅读] Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks(MTCNN)
相关论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks 概论 用于人脸检测和对 ...
- Visualizing and Understanding Convolutional Networks论文复现笔记
目录 Visualizing and Understanding Convolutional Networks 论文复现笔记 Abstract Introduction Approach Visual ...
- 《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》
<Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks> 论文主要的三个贡 ...
- Densely Connected Convolutional Networks 论文阅读
毕设终于告一段落,传统方法的视觉做得我整个人都很奔溃,终于结束,可以看些搁置很久的一些论文了,嘤嘤嘤 Densely Connected Convolutional Networks 其实很早就出来了 ...
- 【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析(转)
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098 另外,读这篇pape ...
- 【Detection】R-FCN: Object Detection via Region-based Fully Convolutional Networks论文分析
目录 0. Paper link 1. Overview 2. position-sensitive score maps 2.1 Background 2.2 position-sensitive ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记
一.高效的训练 1.Large-batch training 使用大的batch size可能会减小训练过程(收敛的慢?我之前训练的时候挺喜欢用较大的batch size),即在相同的迭代次数 ...
随机推荐
- Git版本控制:Git查阅、撤销文件修改和撤销文件追踪
http://blog.csdn.net/pipisorry/article/details/47867097 查看文件的修改历史 git log --pretty=oneline 文件名 # 显示修 ...
- Leetcode_104_Maximum Depth of Binary Tree
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/41964475 Maximum Depth of Binar ...
- 【一天一道LeetCode】#19. Remove Nth Node From End of List
一天一道LeetCode系列 (一)题目 Given a linked list, remove the nth node from the end of list and return its he ...
- vector的简易实现
vector的简易实现整理自<数据结构与算法分析–C++描述(第3版)>3.4节“向量的实现”.详细可参考<STL源码分析>4.2节. 具体实现代码如下: #ifndef VE ...
- android 之ViewStub
在开发应用程序的时候,经常会遇到这样的情况,会在运行时动态根据条件来决定显示哪个View或某个布局.那么最通常的想法就是把可能用到的View都写在上面,先把它们的可见性都设为View.GONE,然后在 ...
- eclipse-整合struts和spring-maven
maven配置文件 <!-- servlet --> <dependency> <groupId>javax.servlet</groupId> < ...
- Gathering Initial Troubleshooting Information for Analysis of ORA-4031 Errors on the Shared Pool
In this Document Purpose Troubleshooting Steps References APPLIES TO: Oracle Database - Enterp ...
- 利用PreLoader实现一个平视显示(HUD)效果(可以运用到加载等待效果),并进行简单的讲解
什么是PreLoader? PreLoader是由Volodymyr Kurbatov设计的一个很有意思的HUD(平视显示效果(Head Up Display)),通过运动污点和固定污点之间的粘黏动画 ...
- 【39】FlexboxLayout使用介绍
FlexboxLayout介绍: Flexbox 也称为弹性盒子模型 或伸缩盒子模型,广泛用于前端开发,做过前端 web 的都知道Bootstrap 中有一套强大的 CSS Grid网格样式.Boot ...
- Understanding the Objective-C Runtime
Wednesday, January 20, 2010 Understanding the Objective-C Runtime The Objective-C Runtime is one of ...