基于dns搭建eureka集群
eureka集群方案:
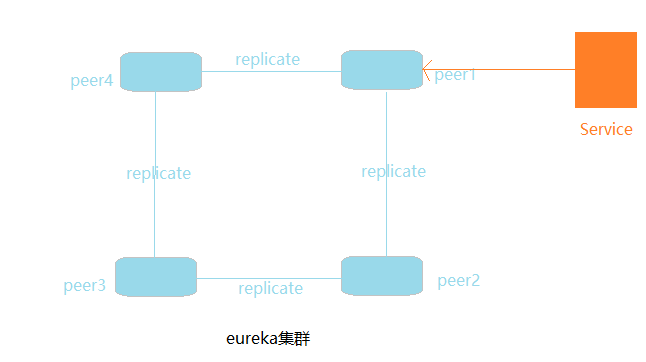
1.通常我们部署的eureka节点多于两个,根据实际需求,只需要将相邻节点进行相互注册(eureka节点形成环状),就达到了高可用性集群,任何一个eureka节点挂掉不会受到影响。
2.可能会有初学者和我一样,一开始的时候没有完全理解eureka集群的原理,直接把每个eureka节点的url写进配置文件,期望所有的eureka节点进行相互注册。实际上,节点间进行信息同步的时候,只会选取配置文件第一个eureka的url,除非发生url错误,才会依次选取有效url进行信息同步。
3.可能有的童鞋有这样的疑问,eureka节点形成环状以后,相隔的多个节点挂掉,eureka节点的数据就会出现不一致的情况。长话短说,要么忍,要么改变方案。
忍其实也是合理的,毕竟挂掉的eureka节点重新启动后会自动同步数据。
改变方案可以把所有的eureka进行相互注册,但把所有的eureka url都写一遍,这个着实有点令人不爽,万一新增节点,所有的节点都需要改一遍!!
所以我们很自然的想到了是否可以通过dns来解决上面的问题?eureka的开发者当然也想到了这种问题,并提供了基于dns的解方案。
一、搭建DNS服务器(unbutun环境)
1.ubuntu需安装bind9软件包来配置dns-server
apt-get install bind9
2.配置dns
2.1添加zone
vim /etc/bind/named.conf.local 加入以下配置,可参考/etc/bind/zones.frc1918中的格式
"eureka.com" { type master; file "/etc/bind/db.eureka.com"; };
2.2创建db.eureka.com文件(需要和2.1添加的file文件同名)
cp db.local db.eureka.com
2.3修改db.eureka.com
添加以下内容
txt.huabei.huabei IN TXT "huabei.eureka.com"
txt.huabei IN TXT "192.168.0.1" "192.168.0.2" "192.168.3"
2.4修改named.conf.options配置文件,这里选用循环给出结果的方式
rrset-order { order cyclic; };
3.修改域名解析配置文件
vim /etc/resolv.conf
加入nameserver 192.168.0.1
注意nameserver顶格写 ip可配置本机ip
4.重启服务
/etc/init.d/bind9 restart
二、eureka集群配置
spring:
application:
name: eureka-server
server:
port: 8081
eureka:
environment: alpha
client:
region: huabei
availability-zones:
huabei: hb10
eureka-server-d-n-s-name: huabei.eureka.com
use-dns-for-fetching-service-urls: true
eureka-server-port: 8081
三、总结
笔者也是首次使用spring-cloud,网上有很多适合入门的使用文档,但在实际项目应用中,我们需要进一步挖掘spring-cloud的特性。后续我继续分享关于eureka的相关知识,比如如何使用region、zone等。
基于dns搭建eureka集群的更多相关文章
- SpringCloud学习之搭建eureka集群,手把手教学,新手教程
一.为什么需要集群 上一篇文章讲解了如何搭建单个节点的eureka,这篇讲解如何搭建eureka集群,这里的集群还是本地不同的端口执行三个eureka,因为条件不要允许,没有三台电脑,所以大家将就一下 ...
- 庐山真面目之十二微服务架构基于Docker搭建Consul集群、Ocelot网关集群和IdentityServer版本实现
庐山真面目之十二微服务架构基于Docker搭建Consul集群.Ocelot网关集群和IdentityServer版本实现 一.简介 在第七篇文章<庐山真面目之七微服务架构Consul ...
- 基于docker搭建elasticsearch集群
es集群的搭建 - 基于单机搭建elasticsearch集群见官网 https://www.elastic.co/guide/en/elasticsearch/reference/current/d ...
- 基于Dokcer搭建Redis集群搭建(主从集群)
最近陆陆续续有不少园友加我好友咨询 redis 集群搭建的问题,我觉得之前写的这篇 <基于Docker的Redis集群搭建> 文章一定是有问题了,所以我花了几分钟浏览之前的文章总结了下面几 ...
- 基于 twemproxy 搭建 redis 集群
概述 由于单台redis服务器的内存管理能力有限,使用过大内存redis服务器的性能急剧下降,且服务器发生故障将直接影响大面积业务.为了获取更好的缓存性能及扩展型,我们将需要搭建redis集群来满足需 ...
- SpringCloud搭建Eureka集群
第一部分:搭建Eureka Server集群 Step1:新建工程,引入依赖 依赖文件pom.xml如下 <?xml version="1.0" encoding=" ...
- 基于pgpool搭建postgresql集群
postgresql集群搭建 基于pgpool中间件实现postgresql一主多从集群部署,这里用两台服务器作一主一从示例 虚拟机名 IP 主从划分 THApps 192.168.1.31 主节点 ...
- 基于pgpool搭建postgressql集群部署
postgresql集群搭建 基于pgpool中间件实现postgresql一主多从集群部署,这里用两台服务器作一主一从示例 虚拟机名 IP 主从划分 THApps 192.168.1.31 主节点 ...
- 搭建Eureka集群
1.pom文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="htt ...
随机推荐
- Java中常见数据结构Map之HashMap
之前很早就在博客中写过HashMap的一些东西: 彻底搞懂HashMap,HashTableConcurrentHashMap关联: http://www.cnblogs.com/wang-meng/ ...
- DDOS和cc攻击的防御
DDOS和cc攻击的防御 author:headsen chen 2017-10-21 10:47:39 个人原创,转载请注明作者,否则依法追究法律责任: DDOS攻击形式:黑客挟持多个电脑( ...
- Python基础-week04
本节内容摘要:#Author:http://www.cnblogs.com/Jame-mei 装饰器 迭代器&生成器 Json & pickle 数据序列化 软件目录结构规范 作业:A ...
- Linux系统命令归纳
常规操作命令: # netstat -atunpl |egrep "mysql|nginx"# vimdiff php.ini*# runlevel# rpm -e httpd - ...
- 20165230 《Java程序设计》第1周学习总结
20165230 2017-2018-2 <Java程序设计>第1周学习总结 教材学习内容总结 本周通过学习了解了java的历史,地位,特点以及java的应用和基本的开发步骤,对Java有 ...
- Python sort后赋值 操作陷阱
x=[1,4,2,0] # 错误的方式,因为sort没有返回值 y=x.sort() type (y) #NoneType #正确的方式 x.sort() y=x[:]
- poj 1154 letters (dfs回溯)
http://poj.org/problem?id=1154 #include<iostream> using namespace std; ]={},s,r,sum=,s1=; ][]; ...
- MIP (百度移动网页加速器)
前言:第一次用移动网页加速器,感觉好心情都被弄坏了.确实性能提高了不少,但是限制js,对于一些交互实现都成问题.MIP是Mobile Instant Pages的缩写,指百度移动网页加速器, 是一套应 ...
- Algorithm --> Dijkstra和Floyd最短路径算法
Dijkstra算法 一.最短路径的最优子结构性质 该性质描述为:如果P(i,j)={Vi....Vk..Vs...Vj}是从顶点i到j的最短路径,k和s是这条路径上的一个中间顶点,那么P(k,s)必 ...
- Algorithm --> 全排列
1.算法简述 简单地说:全排列就是从第一个数字起每个数分别与它后面的数字交换. E.g:E = (a , b , c),则 prem(E)= a.perm(b,c)+ b.perm(a,c)+ c.p ...