apache开源项目--HBase
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
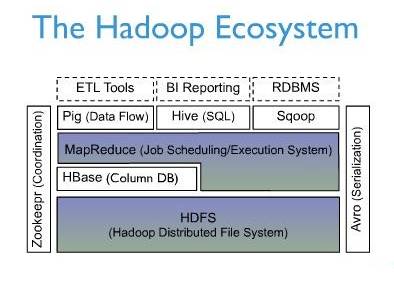
上图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
HBase访问接口
1. Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
2. HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
3. Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
4. REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
5. Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
6. Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase
HBase数据模型
Table & Column Family
| Row Key | Timestamp | Column Family | |
| URI | Parser | ||
| r1 | t3 | url=http://www.taobao.com | title=天天特价 |
| t2 | host=taobao.com | ||
| t1 | |||
| r2 | t5 | url=http://www.alibaba.com | content=每天… |
| t4 | host=alibaba.com | ||
Ø Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
Ø Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
Ø Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
Table & Region
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理:

-ROOT- && .META. Table
HBase中有两张特殊的Table,-ROOT-和.META.
Ø .META.:记录了用户表的Region信息,.META.可以有多个regoin
Ø -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
Ø Zookeeper中记录了-ROOT-表的location
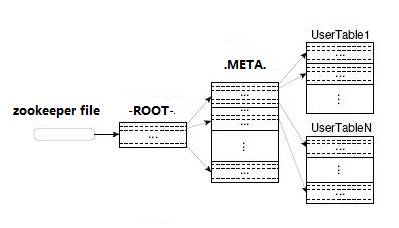
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
MapReduce on HBase
在HBase系统上运行批处理运算,最方便和实用的模型依然是MapReduce,如下图:

HBase Table和Region的关系,比较类似HDFS File和Block的关系,HBase提供了配套的TableInputFormat和TableOutputFormat API,可以方便的将HBase Table作为Hadoop MapReduce的Source和Sink,对于MapReduce Job应用开发人员来说,基本不需要关注HBase系统自身的细节。
HBase系统架构
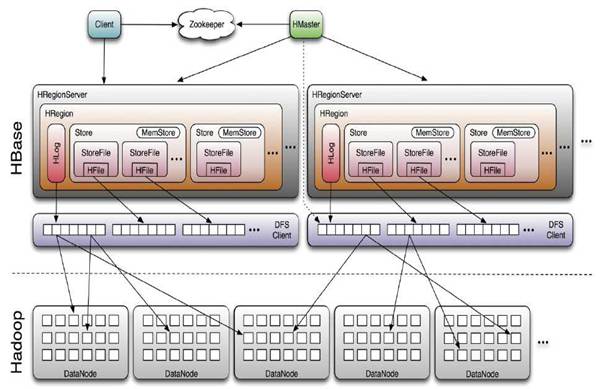
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到 Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的 单点问题,见下文描述
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
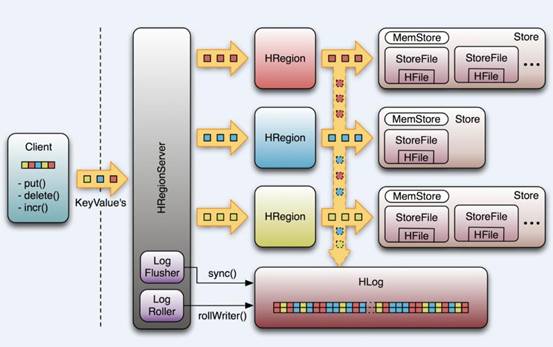
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多 个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是 Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile), 当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进 行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要 进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前 Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:

在理解了上述HStore的基本原理后,还必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问题的,但是在分布式 系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。 每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并 删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知 到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HBase存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括上述提出的两种文件类型:
1. HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
2. HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File
HFile
下图是HFile的存储格式:

首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数 据块的起始点。File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。后面会详细介绍每个KeyValue对的内部构造。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HLogFile

上图中示意了HLog文件的结构,其实HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。
结束
本文对HBase技术在功能和设计上进行了大致的介绍,由于篇幅有限,本文没有过多深入地描述HBase的一些细节技术。目前一淘的存储系统就是基于HBase技术搭建的,后续将介绍“一淘分布式存储系统”,通过实际案例来更多的介绍HBase应用。
介绍内容来自:http://www.searchtb.com/2011/01/understanding-hbase.html
apache开源项目--HBase的更多相关文章
- apache开源项目--Apache Drill
为了帮助企业用户寻找更为有效.加快Hadoop数据查询的方法,Apache 软件基金会发起了一项名为“Drill”的开源项目.Apache Drill 实现了 Google's Dremel. Apa ...
- 15个非常重要的Apache开源项目汇总
15个非常重要的Apache开源项目汇总 自1999年创立以来,Apache软件基金会如今已成了众多重要的开源软件项目之家.本文列举了15个多年来非常重要的Apache项目,这些项目不仅对开源运动来说 ...
- apache开源项目 --Struts
struts简介 Struts是Apache软件基金会(ASF)赞助的一个开源项目.它最初是jakarta项目中的一个子项目,并在2004年3月成为ASF的顶级项目.它通过采用JavaServlet/ ...
- apache开源项目 -- Tuscany
tuscany是Apache组织关于SOA实现的一个开放源码的工程项目,目前处于孵化期阶段. 该项目主要基于SCA,SDO,DAS等技术上实现的. SCA 的基本概念以及 SCA 规范的具体内容并不在 ...
- apache开源项目--Mahout
Apache Mahout 是 Apache Software Foundation (ASF) 开发的一个全新的开源项目,其主要目标是创建一些可伸缩的机器学习算法,供开发人员在 Apache 在许可 ...
- apache开源项目--CouchDB
Apache CouchDB 是一个面向文档的数据库管理系统.它提供以 JSON 作为数据格式的 REST 接口来对其进行操作,并可以通过视图来操纵文档的组织和呈现. CouchDB 是 Apache ...
- apache开源项目--Cassandra
Apache Cassandra是一套开源分布式Key-Value存储系统.它最初由Facebook开发,用于储存特别大的数据.Facebook目前在使用此系统. 主要特性: 分布式 基于column ...
- apache开源项目--nutch
Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch的创始人是Doug Cutting,他同时也是Lucene.Hado ...
- 15个具有高度影响力的Apache开源项目
自1999年创立以来,Apache软件基金会如今已成了众多重要的开源软件项目之家.其中成功的项目有Geronimo,有Tomcat,有Hadoop,有如今成了大数据王国关键车毂的分布式计算系统. 虽然 ...
随机推荐
- 第1章 Git的版本控制之道
版本控制系统(Version Control System,VCS)可以帮助我们记录和跟踪项目中各文件内容的修改变化. 1.1 版本库 版本库(Repository)是版本控制系统用来存储所有历史数据 ...
- 【BZOJ 2440】[中山市选2011]完全平方数
Description 小 X 自幼就很喜欢数.但奇怪的是,他十分讨厌完全平方数.他觉得这些数看起来很令人难受.由此,他也讨厌所有是完全平方数的正整数倍的数.然而这丝毫不影响他对其他数的热爱. 这天是 ...
- sql之事务和并发
1.Transaction(事务)是什么: 事务是作为单一工作单元而执行的一系列操作.包括增删查改. 2.事务的种类: 事务分为显示事务和隐式事务: 隐式事务:就是平常我们使用每一条sql 语句就是一 ...
- 实时数据处理环境搭建flume+kafka+storm:2.flume 安装
1. 解压 tar -zxvf 2.配置 拷贝配置文件 :cp flume-conf.properties.template flume-conf.properties ...
- OnlineJudge大集合
什么是OJ Online Judge系统(简称OJ)是一个在线的判题系统.用户可以在线提交程序源代码,系统对源代码进行编译和执行,并通过预先设计的测试数据来检验程序源代码的正确性. 一个用户提交的程序 ...
- Extjs4.2——Panel
一.Panel的border属性: 示例: Ext.create('Ext.panel.Panel', { title: 'Hello', width: 200, height:100, border ...
- HTML5 中的块级链接
英文叫做 “Block-level” links,我以为只有我厂那些鸟毛不知道,没想到不知道的还挺多, 需要普及一下. 最近看了 kejun 的 PPT 前端开发理论热点面对面:从怎么看,到怎么做?, ...
- [js综合问题汇总]js窗口关闭事件,表单名称,父窗口子窗口,var变量名
<script type="text/javascript"> window.onbeforeunload = onbeforeunload_handler; //wi ...
- socket选项自带的TCP异常断开检测
TCP异常断开是指在突然断电,直接拔网线等等情况下,如果通信双方没有进行数据发送通信等处理的时候,无法获知连接已经断开的情况. 在通常的情况下,为了使得socket通信不受操作系统的限制,需要自己在应 ...
- C++ 嵌套类使用(三)
如果嵌套类型和其外部类型之间的关系需要成员可访问性语义,需要使用C++嵌套类,嵌套类型不应针对其声明类型以外的类型执行任务,而C++局部类允许类.结构和接口被分成多个小块儿并存储在不同的源文件中,这样 ...