总结:如何使用redis缓存加索引处理数据库百万级并发
前言:事先说明:在实际应用中这种做法设计需要各位读者自己设计,本文只提供一种思想。准备工作:安装后本地数redis服务器,使用mysql数据库,事先插入1000万条数据,可以参考我之前的文章插入数据,这里不再细说。我大概的做法是这样的,编码使用多线程访问我的数据库,在访问数据库前先访问redis缓存没有的话在去查询数据库,需要注意的是redis最大连接数最好设置为300,不然会出现很多报错。
贴一下代码吧
package select; import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig; public class SelectFromMysql {
public static void main(String[] args) {
JedisPool pool; JedisPoolConfig config = new JedisPoolConfig();//创建redis连接池
// 设置最大连接数,-1无限制
config.setMaxTotal(300);
// 设置最大空闲连接
config.setMaxIdle(100);
// 设置最大阻塞时间,记住是毫秒数milliseconds
config.setMaxWaitMillis(100000);
// 创建连接池
pool = new JedisPool(config, "127.0.0.1", 6379,200000);
for (int i =9222000; i <=9222200; i++) {//这里自己设置用多少线程并发访问
String teacherName=String.valueOf(i);
new ThreadToMysql(teacherName, "123456",pool).start(); }
}
}
package select; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement; import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool; public class ThreadToMysql extends Thread {
public String teacherName;
public String password;
public JedisPool pool;
public ThreadToMysql(String teacherName, String password,JedisPool pool) {//构造函数传入要查询登录的老师姓名和密码 this.teacherName=teacherName;
this.password=password;
this.pool=pool;
} public void run() {
Jedis jedis = pool.getResource();
Long startTime=System.currentTimeMillis();//开始时间
if (jedis.get(teacherName)!=null) {
Long entTime=System.currentTimeMillis();//开始时间
System.out.println(currentThread().getName()+" 缓存得到的结果: "+jedis.get(teacherName)+" 开始时间:"+startTime+" 结束时间:"+entTime+" 用时:" +(entTime-startTime)+"ms");
pool.returnResource(jedis);
System.out.println("释放该redis连接");
} else { String url = "jdbc:mysql://127.0.0.1/teacher";
String name = "com.mysql.jdbc.Driver";
String user = "root";
String password = "123456";
Connection conn = null;
try {
Class.forName(name);
conn = DriverManager.getConnection(url, user, password);//获取连接
conn.setAutoCommit(false);//关闭自动提交,不然conn.commit()运行到这句会报错
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
if (conn!=null) { String sql="select t_name from test_teacher where t_name='"+teacherName+"' and t_password='"+password+"' ";//SQL语句
String t_name=null;
try {
Statement stmt=conn.createStatement();
ResultSet rs=stmt.executeQuery(sql);//获取结果集
if (rs.next()) {
t_name=rs.getString("t_name");
jedis.set(teacherName, t_name);
System.out.println("释放该连接");
}
conn.commit();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}finally {
pool.returnResource(jedis);
System.out.println("释放该连接");
}
Long end=System.currentTimeMillis();
System.out.println(currentThread().getName()+" 数据库得到的查询结果:"+t_name+" 开始时间:"+startTime+" 结束时间:"+end+" 用时:"+(end-startTime)+"ms"); } else {
System.out.println(currentThread().getName()+"数据库连接失败:");
} }
} }
我的数据库表数据是这样的。可以看到我的t_name是1-10000000,密码固定123456.利用循环创建线程很好做传入循环的次数作为查询的t_name就行了
采用redis缓存替换加索引的方案
1.在200并发访问下:
第一次访问结果:由于第一次访问缓存不存在该数据,速度很慢
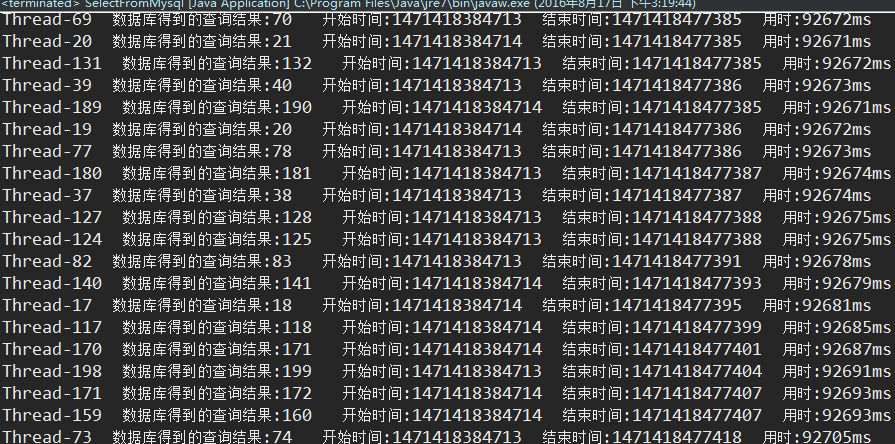
最慢90多秒
运行第二次访问后(redis数据库已存在数据)的结果:
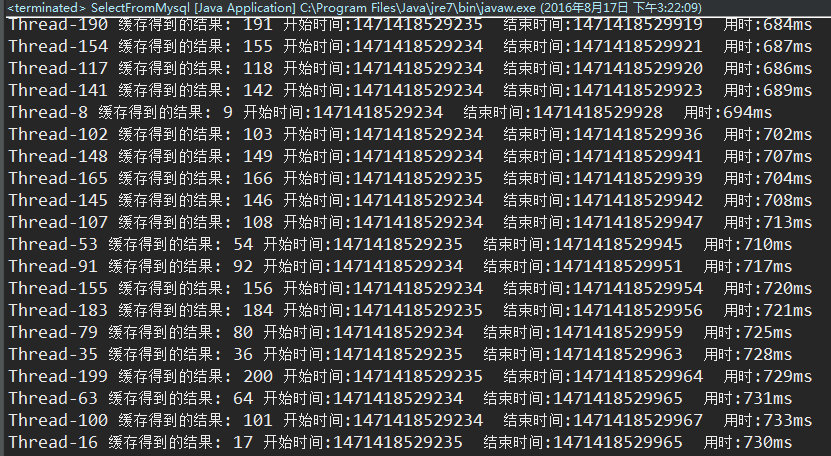
最慢700多毫秒
2.当我尝试1000线程并发访问时redis直接挂掉,原因在于reids缓存并没有要查找的数据,就从数据库查找,1000个线程同时并发访问数据库等待时间太长了,造成redis连接等待超时(就算把redis的超时等待时间设置为100分钟也没用,会报redis连接被拒绝的错误)

3.当我利用循环事先把100万条数据插入redis缓存服务器后,在1万个线程并发访问测试下只需要5~6秒就拿到了查询结果,效率出奇的快,而且没有报任何错
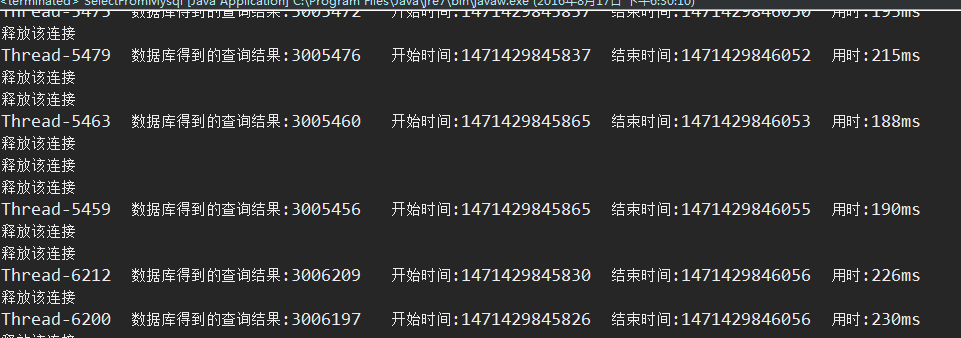
4.在3的条件下我把并发线程提升到100万个时,测试在百万并发条件下查询性能,发现完全没有压力,每个线程也是几毫秒就能查到结果,这个时候限制我速度的就是电脑CPU了。我的测试电脑是4核的,处理100万个线程起来比较慢,下面是截图,运行到50多万个线程的时候我就停止了运行
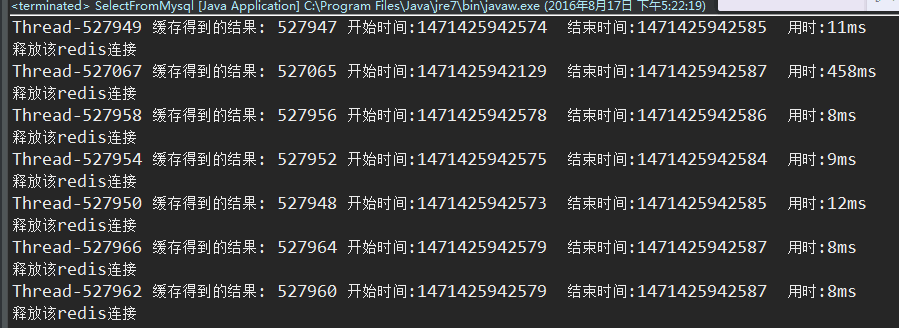
好了,以上都是数据库查询的字段没有加索引直接利用redis缓存查找的
而且有个弊端,百万级的并发访问需要事先把数据放到缓存中,在实际中并不科学(因为并不知道那些是热点数据),下面来看看如何使用索引加缓存的效果
1.给t_name和t_password字段加组合索引
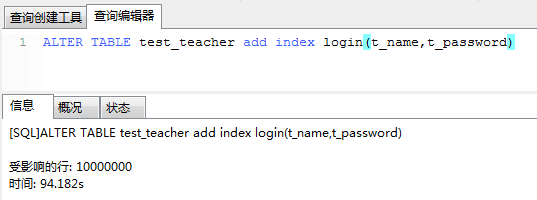
我们来看看在有索引且redis缓存事先没有数据的时候,创建100万个线程并发访问的结果
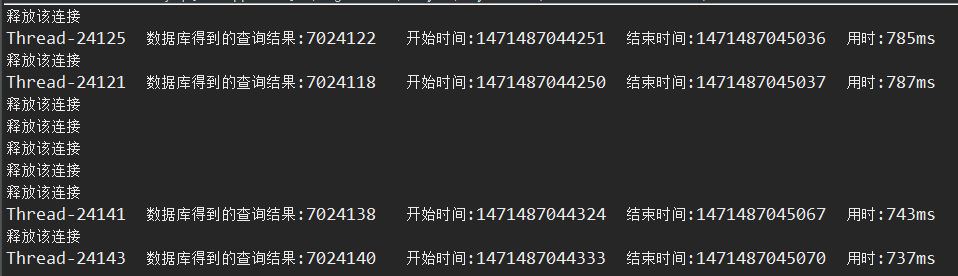
没问题,这样就完成了百万级别下的并发访问,但是这样我的程序创建线程很慢,因为我的电脑4核CPU的(但是要创建100万个线程),这个时候就是硬件设备的性能了,在设备硬件性能足够的条件下是没问题的
以下是我的总结:
1.我的优化方案中只有两种,一种是给查询的字段加组合索引。另一种是给在用户和数据库中增加缓存
2.添加索引方案:面对1~2千的并发是没有压力的,在往上则限制的瓶颈就是数据库最大连接数了,在上面中我用show global status like 'Max_used_connections’查看数据库可以知道数据库最大响应连接数是5700多,超过这个数tomcat直接报错连接被拒绝或者连接已经失效
3.缓存方案:在上面的测试可以知道,要是我们事先把数据库的千万条数据同步到redis缓存中,瓶颈就是我们的设备硬件性能了,假如我们的主机有几百个核心CPU,就算是千万级的并发下也可以完全无压力,带个用户很好的。
4.索引+缓存方案:缓存事先没有要查询的数据,在一万的并发下测试数据库毫无压力,程序先通过查缓存再查数据库大大减轻了数据库的压力,即使缓存不命中在一万的并发下也能正常访问,在10万并发下数据库依然没压力,但是redis服务器设置最大连接数300去处理10万的线程,4核CPU处理不过来,很多redis连接不了。我用show global status like 'Max_used_connections'查看数据库发现最大响应连接数是388,这么低所以数据库是不会挂掉的。
5.使用场景:a.几百或者2000以下并发直接加上组合索引就可以了。b.不想加索引又高并发的情况下可以先事先把数据放到缓存中,硬件设备支持下可解决百万级并发。c.加索引且缓存事先没有数据,在硬件设备支持下可解决百万级并发问题。d.不加索引且缓存事先没有数据,不可取,要80多秒才能得到结果,用户体验极差。
6.原理:其实使用了redis的话为什么数据库不会崩溃是因为redis最大连接数为300,这样数据库最大同时连接数也是300多,所以不会挂掉,至于redis为什么设置为300是因为设置的太高就会报错(连接被拒绝)或者等待超时(就算设置等待超时的时间很长也会报这个错)。
最后说明:本文不代表实际应用开发场景,更多的是提供一种思想,一种解决方案,如有错误,请指正,谢谢
技术交流群:494389786
本文源码:
http://download.csdn.net/detail/qq_32780741/9606370
本代码需要的jar包下载地址:
http://download.csdn.net/detail/qq_32780741/9606380
总结:如何使用redis缓存加索引处理数据库百万级并发的更多相关文章
- 使用redis缓存加索引处理数据库百万级并发
使用redis缓存加索引处理数据库百万级并发 前言:事先说明:在实际应用中这种做法设计需要各位读者自己设计,本文只提供一种思想.准备工作:安装后本地数redis服务器,使用mysql数据库,事先插入1 ...
- springboot整合redis缓存一些知识点
前言 最近在做智能家居平台,考虑到家居的控制需要快速的响应于是打算使用redis缓存.一方面减少数据库压力另一方面又能提高响应速度.项目中使用的技术栈基本上都是大家熟悉的springboot全家桶,在 ...
- 本地缓存,Redis缓存,数据库DB查询(结合代码分析)
问题背景 为什么要使用缓存?本地缓存/Redis缓存/数据库查询优先级? 一.为什么要使用缓存 原因:CPU的速度远远高于磁盘IO的速度问题:很多信息存在数据库当中的,每次查询数据库就是一次IO操作所 ...
- Windows下Redis缓存服务器的使用 .NET StackExchange.Redis Redis Desktop Manager
Redis缓存服务器是一款key/value数据库,读110000次/s,写81000次/s,因为是内存操作所以速度飞快,常见用法是存用户token.短信验证码等 官网显示Redis本身并没有Wind ...
- redis缓存技术学习
1 什么是redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串). list(链表).set(集合)和zset ...
- Windows下Redis缓存服务器的使用 .NET StackExchange.Redis Redis Desktop Manager 转发非原创
Windows下Redis缓存服务器的使用 .NET StackExchange.Redis Redis Desktop Manager Redis缓存服务器是一款key/value数据库,读11 ...
- $.ajax()方法详解 ajax之async属性 【原创】详细案例解剖——浅谈Redis缓存的常用5种方式(String,Hash,List,set,SetSorted )
$.ajax()方法详解 jquery中的ajax方法参数总是记不住,这里记录一下. 1.url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址. 2.type: 要求为Str ...
- 02: Redis缓存系统
目录: 1.1 在centos6.5中安装Redis 1.2 Redis的简介及两种基本操作 1.3 Redis对string操作(第一类) 1.4 redis对Hash操作,字典格式(第二类) 1. ...
- Redis 缓存服务器
Redis 服务器 Remote Dictionay Server Redis是一个key-value持久化产品,通常被称为数据结构服务器. Redis的key是string类型:value可以是 ...
随机推荐
- 0.Win8.1,Win10,Windows Server 2012 安装 Net Framework 3.5
后期会在博客首发更新:http://dnt.dkill.net 网站部署之~Windows Server | 本地部署:http://www.cnblogs.com/dunitian/p/482280 ...
- [C#] C# 知识回顾 - 表达式树 Expression Trees
C# 知识回顾 - 表达式树 Expression Trees 目录 简介 Lambda 表达式创建表达式树 API 创建表达式树 解析表达式树 表达式树的永久性 编译表达式树 执行表达式树 修改表达 ...
- 玩转spring boot——结合AngularJs和JDBC
参考官方例子:http://spring.io/guides/gs/relational-data-access/ 一.项目准备 在建立mysql数据库后新建表“t_order” ; -- ----- ...
- JavaScript基础知识总结(二)
JavaScript语法 二.数据类型 程序把这些量.值分为几大类,每一类分别叫什么名称,有什么特点,就叫数据类型. 1.字符串(string) 字符串由零个或多个字符构成,字符包括字母,数字,标点符 ...
- java时间
Calendar.getInstance().getTime() 获取当前时间(包括星期和时区 CST China Standard Time): Fri Jan 06 21:03:36 CST 2 ...
- 解决IE8下不兼容rgba()的解决办法
rgba()是css3的新属性,所以IE8及以下浏览器不兼容,这怎么办呢?终于我找到了解决办法. 解决办法 我们先来解释以下rgba rgba: rgba的含义,r代表red,g代表green,b代表 ...
- Linux实战教学笔记04:Linux命令基础
第四节:Linux命令基础 标签(空格分隔):Linux实战教学笔记 第1章 认识操作环境 root:当前登陆的用户名 @分隔符 chensiqi:主机名 -:当前路径位置 用户的提示符 1.1 Li ...
- 三大框架SSH整合
三大框架SSH整合 -------------------------------Spring整合Hibernate------------------------------- 一.为什么要整合Hi ...
- 用命令行工具创建 NuGet 程序包
NuGet.exe 下载地址 本文翻译自: https://docs.nuget.org/Create/Creating-and-Publishing-a-Package https://docs.n ...
- Jquery双向select控件Bootstrap Dual Listbox
效果预览: 一. 下载插件 github地址:https://github.com/istvan-ujjmeszaros/bootstrap-duallistbox 也可以在这个网站中下载:http: ...