SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html
关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里。
今天来写一下统计信息对于复合索引在预估时候的计算方法和潜在问题。
本文原形来自于是个实际业务问题,某SQL在利用一个符合索引做查询的时候,发现始终会出现预估误差较大的情况,
而改变复合索引的列顺序,这个预估行数的误差会发生变化,
也就是说,Create index idx_index1 ON TableName(col1,col2)与Create index idx_index2 on TableName(col2,col1)
用完全一样的的查询条件做查询,两个索引的执行计划对其预估的行数是不一样的
究其原因在哪里呢?
先造一个测试环境:
CREATE TABLE TestStatistics
(
COL1 INT IDENTITY(,) ,
COL2 INT ,
COL3 DATETIME ,
COL4 VARCHAR()
)
GO INSERT INTO TestStatistics VALUES (RAND()*,CAST(GETDATE()-RAND()* AS date),NEWID())
GO
问题重现
首先看一个非常有意思的问题,
在同一张表上,
先这么建一个索引:CREATE INDEX IDX_COL2_COL3 ON TestStatistics(COL2,COL3)
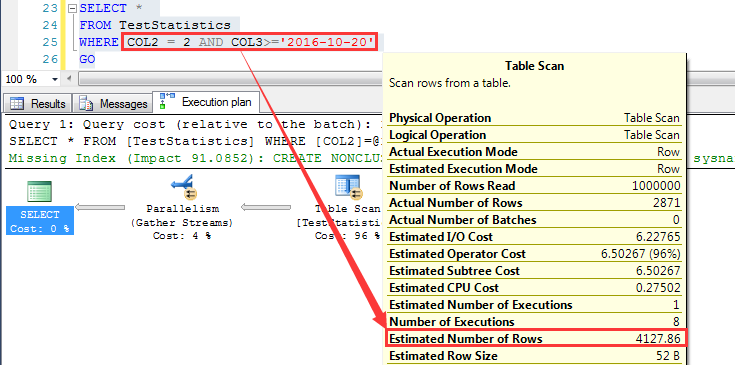
执行一个查询,预估为4127.86行
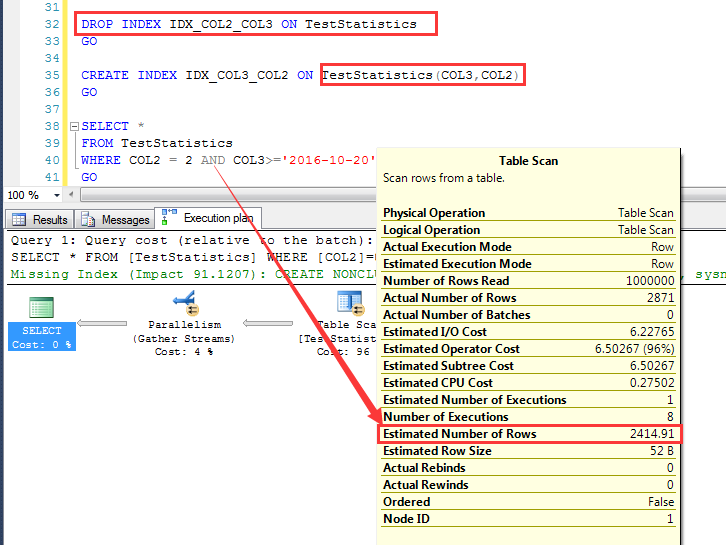
然后DROP掉上面的索引,继续创建一个索引:CREATE INDEX IDX_COL3_COL2 ON TestStatistics(COL3,COL2)
注意COL2和COL3的顺序不一致
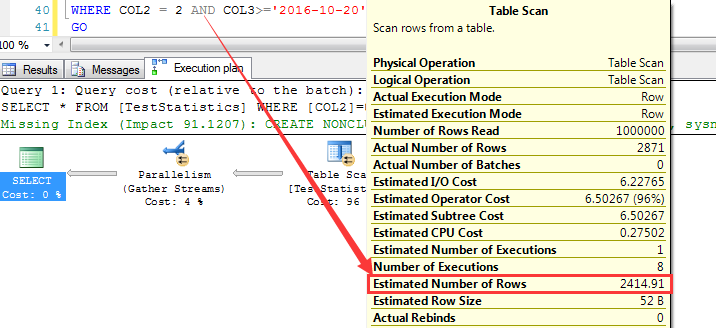
继续执行上面的查询(查询条件不变,数据不变,仅仅是索引列顺序发生了变化),这一次预估为2414.91行
查询条件一样,数据也一样,为什么改变复合索引列顺序会影响到执行计划对数据行的预估呢?
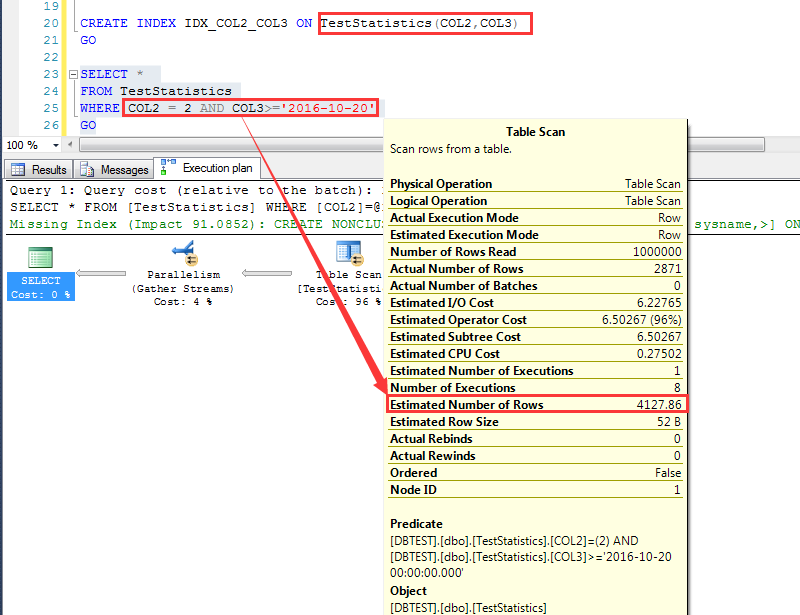
首先来看第一个索引时候的预估算法:
这个查询他预估为4127.86行,如下图
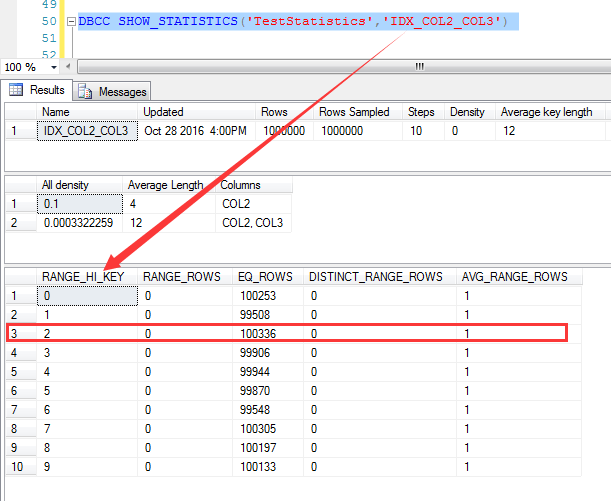
说起来预估,就离不开统计信息,首先来看IDX_COL2_COL3这个索引的统计信息,
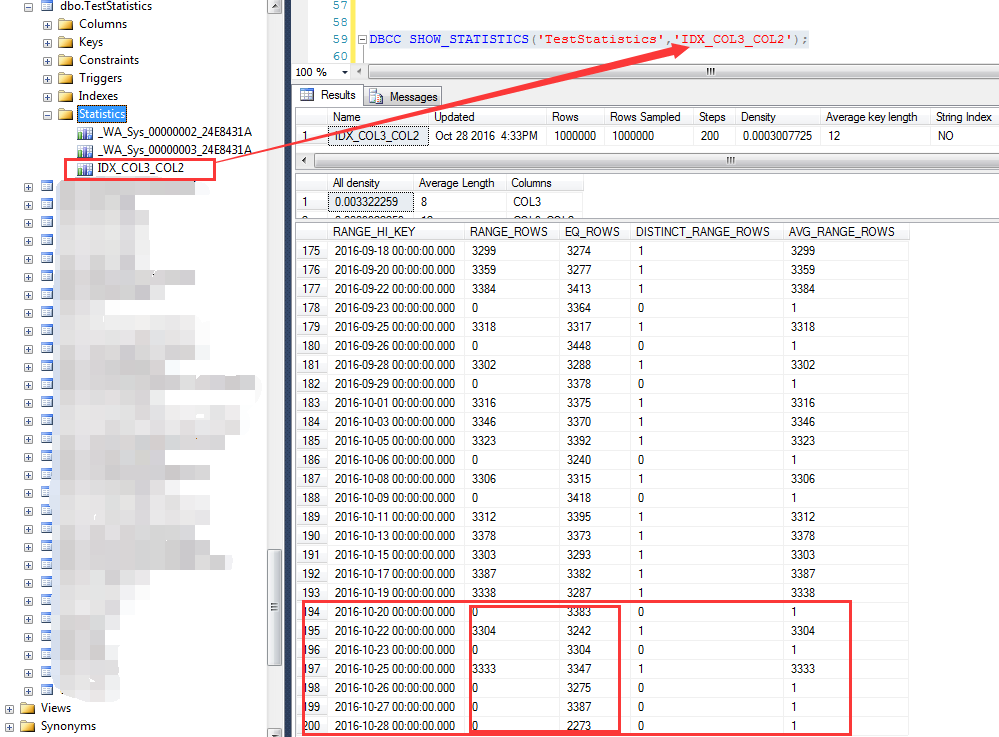
我们知道,对于复合索引,统计信息中只有前导列的统计数据,也就是说IDX_COL3_COL2这个索引只有COL2这个列的统计信息,如下截图
对于COL2=2的统计信息,统计为100336行,我们记住这个数字
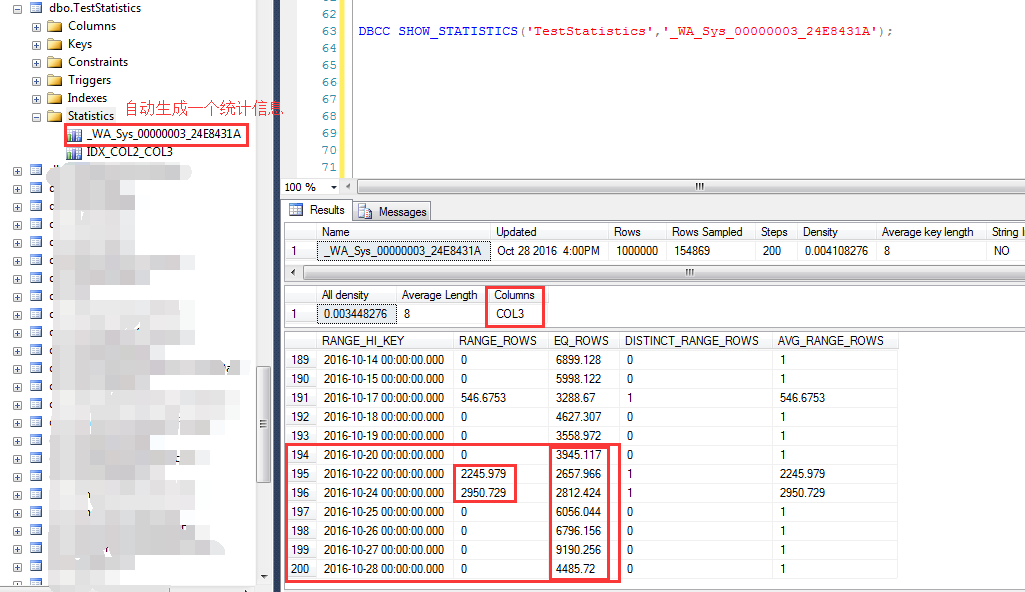
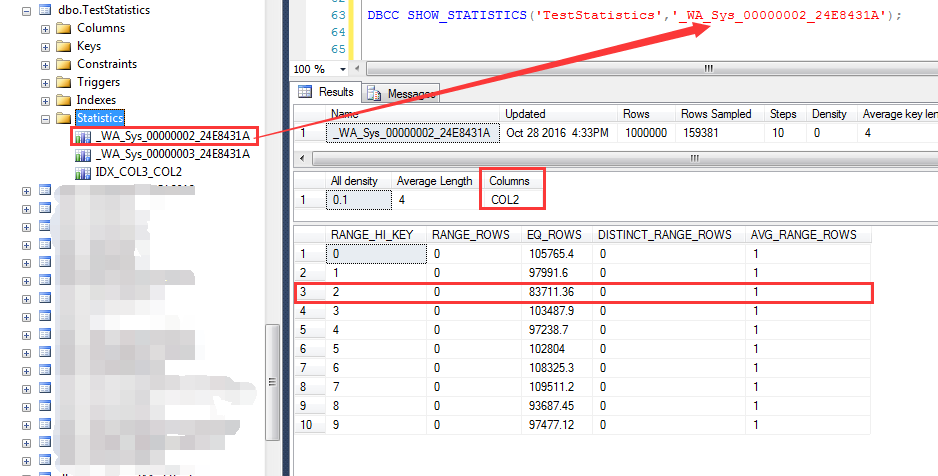
统计信息的另外一个特点就是在会在查询列(非索引列)上自动创建统计信息,如下截图
查询执行过程中,自动创建了一个名字为:_WA_Sys_00000003_24E8431A的统计信息
这个统计信息就是对COL3列的统计,可以发现在大于等于2012-10-20之后的统计行数
在SQL Server 2012中,对数据行的预估计算方式是各个字段的选择性的乘积,
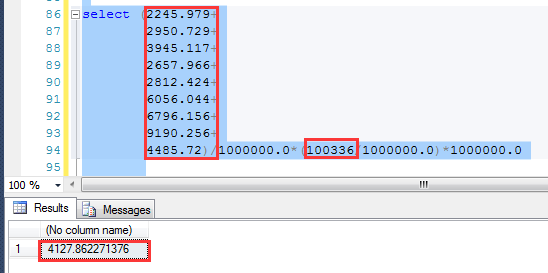
假如Pn代表不同字段的密度,那么预估行数的计算方法就是: 预估行数=p0*p1*p2*p3……*RowCount
可以利用这个算法,计算目前数据下,预估出来的结果:4217.86,跟执行计划预估是一致的,非常完美!
当删除了IDX_COL2_COL3重建建立顺序为COL3+COL2的索引的时候,预估如下
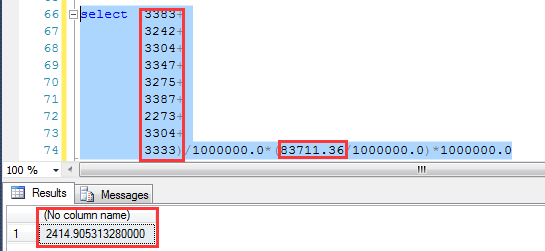
与上面同样的查询条件,预估为2414.91行
依据上面的分析步骤,首先来分析索引列上的统计信息,如下截图为大于等于2016-10-20之后的预估行数
同理,本次查询也会自动建立COL2列上的统计信息(IDX_COL2_COL3索引被删除),观察这个统计信息对COL2=2的预估为83711.36行
同样我们利用上述公式,来计算预估的行数:2414.9035行,也非常完美地吻合和执行计划预估的结果
至此,应该很清楚一开始的问题了,就是为什么复合索引列顺序不一致,在查询的时候导致预估也不一致的原因。
最根本的原因有就是:
符合索引上只有前导列的统计信息,查询引擎会根据需要自动创建非前导列的统计信息,
但是,非常关键一点,如果细心的话,你会发现查询引擎自动创建的统计信息的取样行数都不是100%取样的,这一点非常关键
正是因为非前导列取样有一定的误差,导致在预估算法的时候,也即 预估行数=p0*p1*p2*p3……*RowCount的时候,密度值是不一样的
也即在创建IDX_COL2_COL3的时候,统计出来的COL2密度为P1_1,COL3密度为P2_1,
创建IDX_COL3_COL2的时候,统计出来的COL2密度为P1_2,COL3密度为P2_2,因为P1_1<>P1_2,P2_1<>P2_2
因此,计算出的结果就是P1_1*P2_1<>P2_1*P2_2,原理很简单,希望看官能明白。
照这么计算,对于两个顺序不同的统计信息,如果P1_1=P2_1并且P2_1=P2_2,那么乘积就是一样的,预估行数也就是一样的,那么是不是呢?
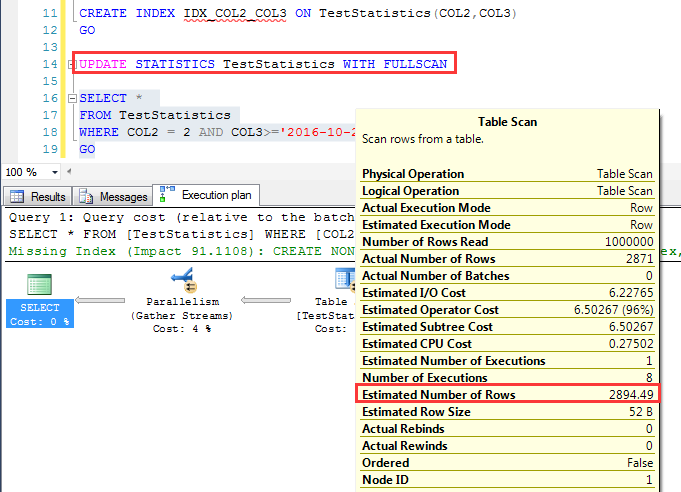
对于不同顺序的两个索引,先看COL2,COL3顺序的索引
在查询一次之后(建立了统计信息),执行一个百分之百取样(WITH FULLSCAN)的统计信息更新
重新来看其预估行数,这一次预估为:2894.49
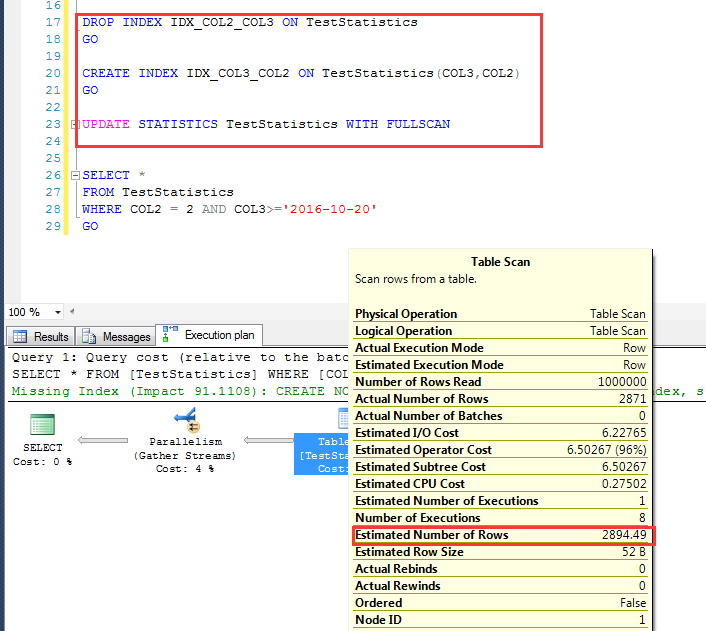
删除COL2,COL3顺序的索引,建立COL3,COL2为顺序的索引
在查询一次之后(建立了统计信息),执行一个百分之百取样(WITH FULLSCAN)的统计信息更新
重新来看其预估行数,这一次预估为:同样为2894.49,是吻合上述算法
总结:
文本简单演示了执行计划利用统计信息预估的算法和原理,以及在计算预估行数时候可能受到的干扰因素,
这就要求我们在建立索引的时候,不仅仅是说我建一个复合索引就完事了,也要注意其索引列的顺序对执行计划预估的影响,
更重要的是,要注意查询引擎自动生成的统计信息对预估的影响程度。
抛开统计信息谈索引的,都是耍流氓。抛开统计信息取样百分比谈统计信息的,也是耍流氓。
引申出来另外一个问题:维护统计信息的时候,能只更新索引列的统计信息,忽略非索引列的统计信息吗?
本人技术能力还很菜,写的不对的地方还请各位看官指出,谢谢。
SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)的更多相关文章
- SQL Server 执行计划利用统计信息对数据行的预估原理以及SQL Server 2014中预估策略的改变
前提 本文仅讨论SQL Server查询时, 对于非复合统计信息,也即每个字段的统计信息只包含当前列的数据分布的情况下, 在用多个字段进行组合查询的时候,如何根据统计信息去预估行数的. 利用不同字段 ...
- SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
说说复合索引 写索引的博客太多了,一直不想动手写,有一下两个原因:一是觉得有炒剩饭的嫌疑,有兄弟曾说:索引吗,只要在查询条件上建索引就行了,真的可以这么暴力吗?二来觉得,索引是个非常大的话题,很难概括 ...
- SQL Server 数据库表的统计信息的更新
最近在调整基础信息数据时,新增了几个客户类型,意想不到的事情发生了,在使用新增的客户类型作为 查询条件查询报表时,居然出现了超时的现象,但是用其他以前的客户类型查询就没有问题,用一个 ...
- SQL Server用户自定义类型与统计信息
用户自定义数据类型不支持统计信息! 所以查询对它的查询会慢一些.
- sqlplus中显示sql执行计划和统计信息
31 ,32 , 33 ,34 keywords : oracle storage structure 最详细讲解: 1:doc 1 logical storage structure 2 ...
- 为准确生成执行计划更新统计信息-analyze与dbms_stats
如果我们想让CBO利用合理利用数据的统计信息,正确判断执行任何SQL查询时的最快途径,需要及时的使用analyze命令或者dbms_stats重新统计数据的统计信息. 例如索引跳跃式扫描(INDEX ...
- Oracle执行计划与统计信息的一些总结
[日期:2011-08-05]来源:Linux社区 作者:wangshengfeng1986211[字体:大 中 小] 2010-07-01 15:03 1.SET AUTOTRACE ON EXP ...
- 【SQL Server DBA】日常巡检语句3:特定监控(阻塞、top语句、索引、作业)
原文:[SQL Server DBA]日常巡检语句3:特定监控(阻塞.top语句.索引.作业) 1.查询阻塞信息.锁定了哪些资源 --1.查看阻塞信息 select spid,loginame,wai ...
- 译:SQL Server的Missing index DMV的 bug可能会使你失去理智---慎重看待缺失索引DMV中的信息
注: 本文译自https://www.sqlskills.com/blogs/paul/missing-index-dmvs-bug-that-could-cost-your-sanity/ 原文作者 ...
随机推荐
- Linux 常用命令(持续补充)
常用命令: command &:将进程放在后台执行 ctrl + z:暂停当前进程 并放入后台 jobs:查看当前后台任务 bg( %id):将任务转为后台执行 fg( %id):将任务调回前 ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- AbpZero--2.如何启动
1.直接启动 VS中直接启动 2.IIS站点 IIS中配置一个站点来启动(推荐) 3.登录 系统默认创建2个用户 默认用户名:admin 密码:123qwe 租户:Default 默认用户名:adm ...
- javascript高性能编程-算法和流程控制
代码整体结构是执行速度的决定因素之一. 代码量少不一定运行速度快, 代码量多也不一定运行速度慢. 性能损失与代码组织方式和具体问题解决办法直接相关. 倒序循环可以提高性能,如: ...
- SQL 数据优化索引建suo避免全表扫描
首先什么是全表扫描和索引扫描?全表扫描所有数据过一遍才能显示数据结果,索引扫描就是索引,只需要扫描一部分数据就可以得到结果.如果数据没建立索引. 无索引的情况下搜索数据的速度和占用内存就会比用索引的检 ...
- MSSQL 事务,视图,索引,存储过程,触发器
事务 事务是一种机制.是一种操作序列,它包含了一组数据库操作命令,这组命令要么全部执行,要么全部不执行. 在数据库系统上执行并发操作时事务是作为最小的控制单元来使用的.这特别适用于多用户同时操作的数据 ...
- Linux设备管理(四)_从sysfs回到ktype
sysfs是一个基于ramfs的文件系统,在2.6内核开始引入,用来导出内核对象(kernel object)的数据.属性到用户空间.与同样用于查看内核数据的proc不同,sysfs只关心具有层次结构 ...
- Linux设备文件简介(转载)
Linux 中的设备有2种类型:字符设备(无缓冲且只能顺序存取).块设备(有缓冲且可以随机存取).每个字符设备和块设备都必须有主.次设备号,主设备号相同的设 备是同类设备(使用同一个驱动程序).这些设 ...
- JS中关于字符串的几个常用又容易忘记的方法
1>.字符串连接:concat(): 左边字符串. concat(连接的字符串1,字符串2,....); 获取指定位置的字符:charAt(): 返回指定位置的字符: 字符串.charAt(i ...
- Openfire阶段实践总结
从3月开始研究Openfire,其实就是要做一套IM系统,也正是这个原因才了解到Openfire.之前还真没想过有这么多的开源产品可以做IM,而且也没想到XMPP这个协议竟然如何强大.看来还是标准为先 ...