用Tensorflow实现DCGAN
1. GAN简介
最近几年,深度神经网络在图像识别、语音识别以及自然语言处理方面的应用有了爆炸式的增长,并且都达到了极高的准确率,某些方面甚至超过了人类的表现。然而人类的能力远超出图像识别和语音识别的任务,像很多需要创造力的任务却是机器很难做到的。但是GAN使得机器解决这些任务成为可能。
深度学习的领军人物Yann LeCun曾经说过:
生成对抗网络(GAN)及其变种已经成为最近10年以来机器学习领域最重要的思想。
为了能更好的了解GAN,做一个比喻,想象一下制作伪钞的犯罪嫌疑人和警察这个现实中的例子:
- 想要成为一名成功的假钞制作者,犯罪嫌疑人需要蒙骗得了警察,使得警察无法区分出哪一张是假钞、哪一张是真钞。
- 作为警察,需要尽可能高效地发现那些是假钞
整个过程被称为对抗性过程(adversarial process)GAN是由Ian Goodfellow 于2014年提出,它是一种两个神经网络相互竞争的特殊对抗过程。第一个网络生成数据,第二个网络试图区分真实数据与第一个网络创造出来的假数据。第二个网络会生成一个在[0, 1]范围内的标量,代表数据是真是数据的概率。
2.GAN的目的
GAN是生成模型的一种,主要在模型的分布中生成样本,它只能够制造数据而不是提供一个预测的密度函数。
下面是一些学习生成模型的理由:
- 生成样本,这是最直接的理由。
- 训练并不包含最大似然估计。
- 由于生成器不会看到训练数据,过拟合风险更低。
- GAN十分擅长捕获模式的分布。
3.GAN的组成
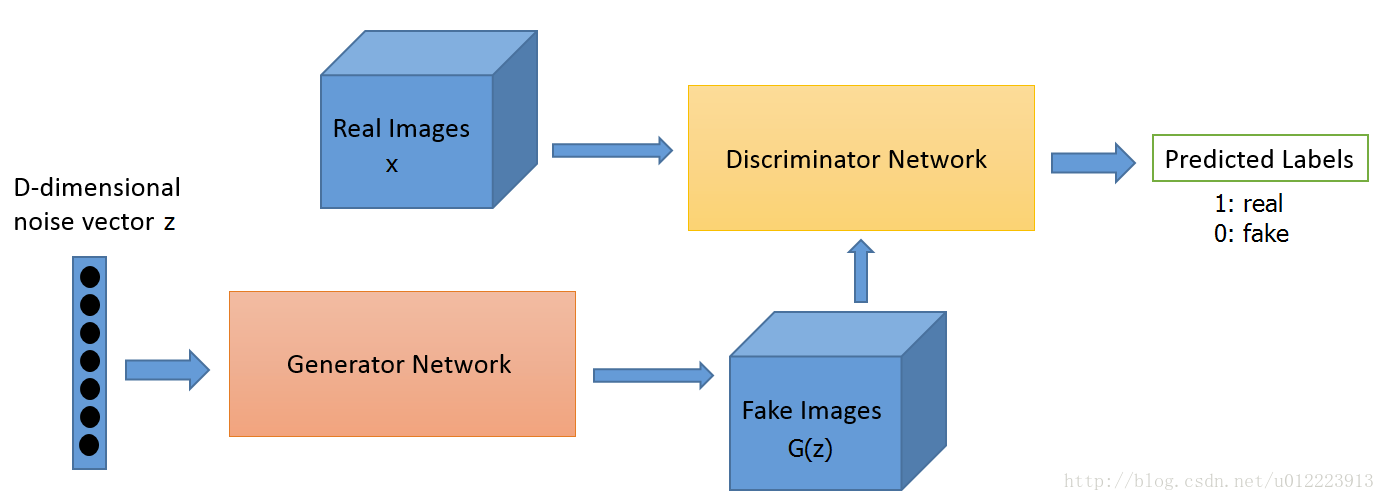
GAN的计算流程与结构如图 所示。
GAN包含两个部分,即生成器generative和判别器discriminative。以生成图片为例,生成器主要用于学习真实图像分布从而让自身生成的图像更加真实,使得判别器分辨不出生成的数据是否是真实数据。判别器则需要对接受到的图片进行真假判别。整个过程可以看作是生成器和判别器的博弈,随着时间的推移,最终两个网络达到一个动态均衡:生成器生成的图像近似于真实图像分布,而判别器对给定图像的判别概率约为0.5,相当于盲猜。
假设真实数据data分布为,生成器G学习到的数据分布为,z为随机噪声,为噪声分布,为生成映射函数,将这个随机噪声转化为数据x,为判别映射函数,输出是判别x来自真实数据data而不是生成数据的概率。训练判别器D使得判别概率最大化,同时,训练生成器G最小化,这个优化过程可以被归结于一个‘二元极小极大博弈’(two-player minimax game),目标函数被定义如下:

从判别器D的角度,D希望它自己能够尽可能地判别出真实数据和生成数据,即使得D(x)尽可能的达,D(G(z))尽可能的小,即V(D,G)尽可能的大。从生成器G的角度来说,G希望自己生成的数据尽可能地接近于真实数据,也就是希望D(G(z))尽可能地大,D(x)尽可能的小,即V(D,G)尽可能的小。两个模型相互对抗,最后达到全局最优。
4.DCGAN的实现
GAN出来后很多相关的应用和方法都是基于DCGAN的结构,DCGAN即”Deep Convolution GAN”,通常会有一些约定俗成的规则:
在Discriminator和generator中大部分层都使用batch normalization,而在最后一层时通常不会使用batch normalizaiton,目的 是为了保证模型能够学习到数据的正确的均值和方差;
因为会从random的分布生成图像,所以一般做需要增大图像的空间维度时如77->1414, 一般会使用strdie为2的deconv(transposed convolution);
通常在DCGAN中会使用Adam优化算法而不是SGD。
实现结果大概是这样的:

4.1导入数据:
import os
import sys
import tensorflow as tf
from tensorflow import logging
from tensorflow import gfile
import pprint
import pickle
import numpy as np
import random
import math
from PIL import Image
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data/', one_hot = True) output_dir = './local_run'
if not gfile.Exists(output_dir):
gfile.MakeDirs(output_dir) def get_default_params():
"""设置默认参数"""
return tf.contrib.training.HParams(
z_dim = 100,
init_conv_size = 4,
g_channels = [128, 64, 32, 1],
d_channels = [32, 64, 128, 256],
batch_size = 128,
learning_rate = 0.002,
beta1 = 0.5,
img_size = 32,
)
hps = get_default_params() class MnistData(object):
"""Mnist数据集预处理"""
def __init__(self, mnist_train, z_dim, img_size):
self._data = mnist_train
self._example_num = len(self._data)
self._z_data = np.random.standard_normal((self._example_num, z_dim))
self._indicator = 0
self._resize_mnist_img(img_size)
self._random_shuffle() def _random_shuffle(self):
"""打乱数据集所有图片,使图片数据随机分布"""
p = np.random.permutation(self._example_num)
self._z_data = self._z_data[p]
self._data = self._data[p] def _resize_mnist_img(self, img_size):
"""
Resize mnist image to goal img_size.
1. numpy -> PIL img
2. PIL img -> resize
3. PIL img -> numpy
"""
data = np.asarray(self._data * 255, np.uint8)
data = data.reshape((self._example_num, 1, 28, 28)) # [example_num, 784] - > [example_num, 28, 28]
data = data.transpose((0, 2, 3, 1))
new_data = []
for i in range(self._example_num):
img = data[i].reshape((28, 28))
img = Image.fromarray(img)
img = img.resize((img_size, img_size))
img = np.asarray(img)
img = img.reshape((img_size, img_size, 1))
new_data.append(img)
new_data = np.asarray(new_data, dtype=np.float32)
new_data = new_data / 127.5 - 1
# self._data: [num_example, img_size, img_size, 1]
self._data = new_data def next_batch(self, batch_size):
"""使用mini-batch的方法加载数据集"""
end_indicator = self._indicator + batch_size
if end_indicator > self._example_num:
self._random_shuffle()
self._indicator = 0
end_indicator = self._indicator + batch_size
assert end_indicator < self._example_num batch_data = self._data[self._indicator: end_indicator]
batch_z = self._z_data[self._indicator: end_indicator]
self._indicator = end_indicator
return batch_data, batch_z mnist_data = MnistData(mnist.train.images, hps.z_dim, hps.img_size)
batch_data, batch_z = mnist_data.next_batch(5)
(数据处理)
4.2定义模型
def conv2d_transpose(inputs, out_channel, name, training, with_bn_relu=True):
"""将生成器要使用的卷积层函数打包,增加batch normalization层"""
with tf.variable_scope(name):
conv2d_trans = tf.layers.conv2d_transpose(inputs,
out_channel,
[5, 5],
strides=(2,2),
padding='SAME')
if with_bn_relu:
bn = tf.layers.batch_normalization(conv2d_trans, training=training)
relu = tf.nn.relu(bn)
return relu
else:
return conv2d_trans def conv2d(inputs, out_channel, name, training):
"""将判别器要使用的卷积层函数打包,使用Leaky_relu激活函数"""
def leaky_relu(x, leak = 0.2, name = ''):
return tf.maximum(x, x * leak, name = name)
with tf.variable_scope(name):
conv2d_output = tf.layers.conv2d(inputs,
out_channel,
[5, 5],
strides = (2, 2),
padding = 'SAME')
bn = tf.layers.batch_normalization(conv2d_output,
training = training)
return leaky_relu(bn, name = 'outputs')
(打包需要经常使用的函数)
class Generator(object):
"""生成器"""
def __init__(self, channels, init_conv_size):
assert len(channels) > 1
self._channels = channels
self._init_conv_size = init_conv_size
self._reuse = False def __call__(self, inputs, training):
inputs = tf.convert_to_tensor(inputs)
with tf.variable_scope('generator', reuse=self._reuse):
with tf.variable_scope('inputs'):
fc = tf.layers.dense(
inputs,
self._channels[0] * self._init_conv_size * self._init_conv_size)
conv0 = tf.reshape(fc, [-1, self._init_conv_size, self._init_conv_size, self._channels[0]])
bn0 = tf.layers.batch_normalization(conv0, training=training)
relu0 = tf.nn.relu(bn0) deconv_inputs = relu0
# deconvolutions * 4
for i in range(1, len(self._channels)):
with_bn_relu = (i != len(self._channels) - 1)
deconv_inputs = conv2d_transpose(deconv_inputs,
self._channels[i],
'deconv-%d' % i,
training,
with_bn_relu)
img_inputs = deconv_inputs
with tf.variable_scope('generate_imgs'):
# imgs value scope: [-1, 1]
imgs = tf.tanh(img_inputs, name='imgaes')
self._reuse=True
self.variables = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='generator')
return imgs
class Discriminator(object):
"""判别器"""
def __init__(self, channels):
self._channels = channels
self._reuse = False def __call__(self, inputs, training):
inputs = tf.convert_to_tensor(inputs, dtype=tf.float32) conv_inputs = inputs
with tf.variable_scope('discriminator', reuse = self._reuse):
for i in range(len(self._channels)):
conv_inputs = conv2d(conv_inputs,
self._channels[i],
'deconv-%d' % i,
training)
fc_inputs = conv_inputs
with tf.variable_scope('fc'):
flatten = tf.layers.flatten(fc_inputs)
logits = tf.layers.dense(flatten, 2, name="logits")
self._reuse = True
self.variables = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='discriminator')
return logits
4.3设定损失函数
论文中的解释如下:

由于tensorflow只能做minimize,loss function可以写成如下:
D_loss = -tf.reduce_mean(tf.log(D_real) + tf.log(1. - D_fake))
G_loss = -tf.reduce_mean(tf.log(D_fake))
另外一种写法是利用tensorflow自带的tf.nn.sigmoid_cross_entropy_with_logits 函数:
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=D_logit_real, labels=tf.ones_like(D_logit_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=D_logit_fake, labels=tf.zeros_like(D_logit_fake)))
D_loss = D_loss_real + D_loss_fake
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=D_logit_fake, labels=tf.ones_like(D_logit_fake)))
4.4建立模型
class DCGAN(object):
"""建立DCGAN模型"""
def __init__(self, hps):
g_channels = hps.g_channels
d_channels = hps.d_channels self._batch_size = hps.batch_size
self._init_conv_size = hps.init_conv_size
self._batch_size = hps.batch_size
self._z_dim = hps.z_dim self._img_size = hps.img_size self._generator = Generator(g_channels, self._init_conv_size)
self._discriminator = Discriminator(d_channels) def build(self):
self._z_placholder = tf.placeholder(tf.float32, (self._batch_size, self._z_dim))
self._img_placeholder = tf.placeholder(tf.float32,
(self._batch_size, self._img_size, self._img_size, 1)) generated_imgs = self._generator(self._z_placholder, training = True)
fake_img_logits = self._discriminator(generated_imgs, training = True)
real_img_logits = self._discriminator(self._img_placeholder, training = True) loss_on_fake_to_real = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels = tf.ones([self._batch_size], dtype = tf.int64),
logits = fake_img_logits))
loss_on_fake_to_fake = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels = tf.zeros([self._batch_size], dtype = tf.int64),
logits = fake_img_logits))
loss_on_real_to_real = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels = tf.ones([self._batch_size], dtype = tf.int64),
logits = real_img_logits)) tf.add_to_collection('g_losses', loss_on_fake_to_real)
tf.add_to_collection('d_losses', loss_on_fake_to_fake)
tf.add_to_collection('d_losses', loss_on_real_to_real) loss = {
'g': tf.add_n(tf.get_collection('g_losses'), name = 'total_g_loss'),
'd': tf.add_n(tf.get_collection('d_losses'), name = 'total_d_loss')
} return (self._z_placholder, self._img_placeholder, generated_imgs, loss) def build_train(self, losses, learning_rate, beta1):
g_opt = tf.train.AdamOptimizer(learning_rate = learning_rate, beta1 = beta1)
d_opt = tf.train.AdamOptimizer(learning_rate = learning_rate, beta1 = beta1)
g_opt_op = g_opt.minimize(losses['g'], var_list = self._generator.variables)
d_opt_op = d_opt.minimize(losses['d'], var_list = self._discriminator.variables)
with tf.control_dependencies([g_opt_op, d_opt_op]):
return tf.no_op(name = 'train') dcgan = DCGAN(hps)
z_placeholder, img_placeholder, generated_imgs, losses = dcgan.build()
train_op = dcgan.build_train(losses, hps.learning_rate, hps.beta1)
4.5训练模型
#开始训练
init_op = tf.global_variables_initializer()
train_steps = 10000 with tf.Session() as sess:
sess.run(init_op)
for step in range(train_steps):
batch_img, batch_z = mnist_data.next_batch(hps.batch_size) fetches = [train_op, losses['g'], losses['d']]
should_sample = (step + 1) % 50 == 0
if should_sample:
fetches += [generated_imgs]
out_values = sess.run(fetches,
feed_dict = {
z_placeholder: batch_z,
img_placeholder: batch_img
})
_, g_loss_val, d_loss_val = out_values[0:3]
logging.info('step: %d, g_loss: %4.3f, d_loss: %4.3f' % (step, g_loss_val, d_loss_val))
if should_sample:
gen_imgs_val = out_values[3] gen_img_path = os.path.join(output_dir, '%05d-gen.jpg' % (step + 1))
gt_img_path = os.path.join(output_dir, '%05d-gt.jpg' % (step + 1)) gen_img = combine_and_show_imgs(gen_imgs_val, hps.img_size)
gt_img = combine_and_show_imgs(batch_img, hps.img_size) print(gen_img_path)
print(gt_img_path)
gen_img.save(gen_img_path)
gt_img.save(gt_img_path)
4.6显示保存的图片
def combine_and_show_imgs(batch_imgs, img_size, rows=8, cols=16):
"""连接图片,组成一个网格图片"""
# batch_imgs: [batch_size, img_size, img_size, 1]
result_big_img = []
for i in range(rows):
row_imgs = []
for j in range(cols):
img = batch_imgs[cols * i + j]
img = img.reshape((img_size, img_size))
img = (img + 1) * 127.5
row_imgs.append(img)
row_imgs = np.hstack(row_imgs)
result_big_img.append(row_imgs)
result_big_img = np.vstack(result_big_img)
result_big_img = np.asarray(result_big_img, np.uint8)
result_big_img = Image.fromarray(result_big_img)
return result_big_img
下面是分别经过10000次训练后生成的结果:
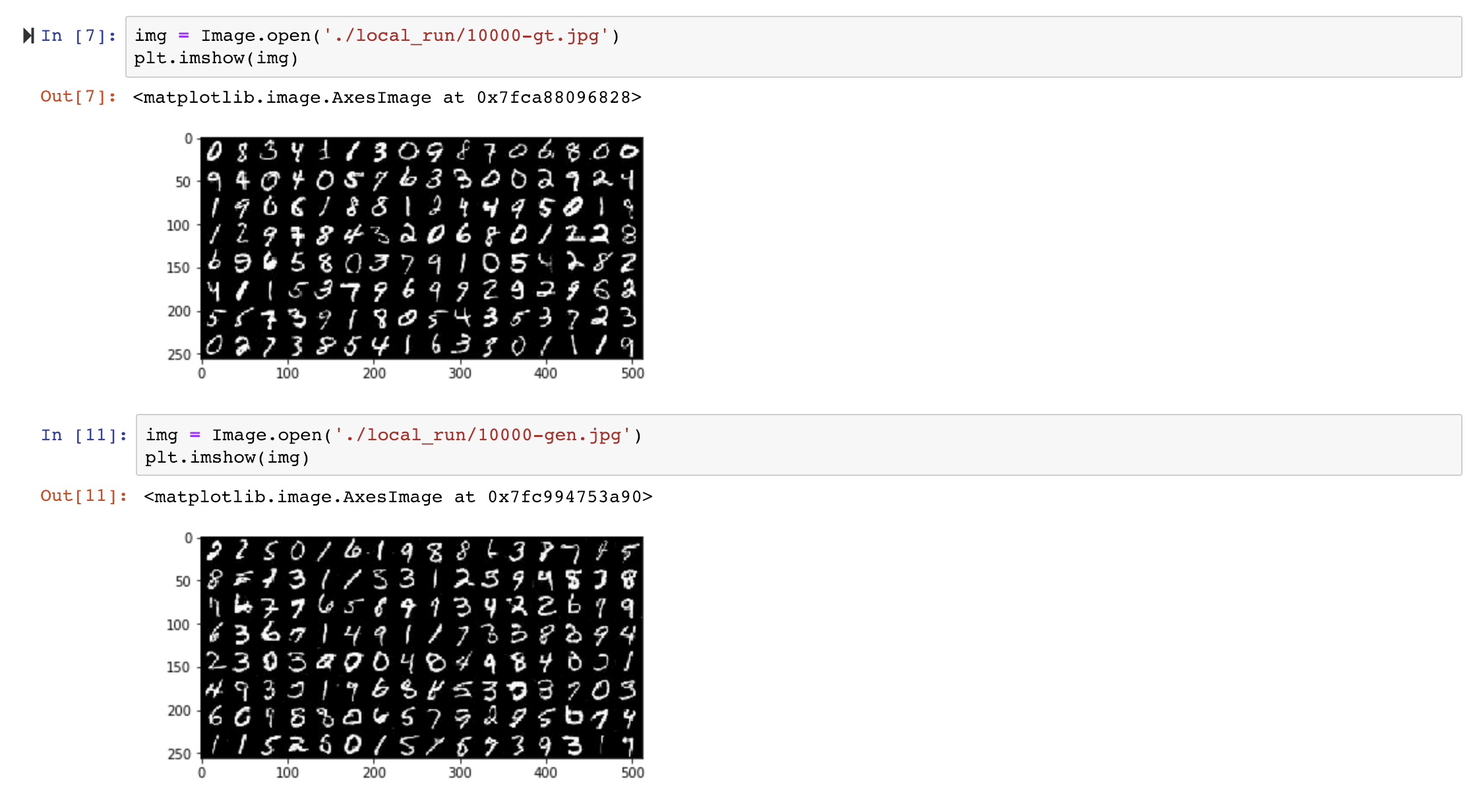
5.Summary
训练GAN本质上是生成器网络G(z)和判别起网络D(z)相互竞争并达到最优,生成器和判别器最终达到了一个如果对方不改变就无法进一步提升的状态。理想情况下,我们希望两个网络以同样的速率同时进行改善。判别器最理想的损失接近于0.5,在这个情况下对于判别器来说其无法从真实图像中区分出生成的图像。
为了克服训练GAN模型中的问题,下面使一些常用的方法:
- 特征匹配
- Mini-batch
- 滑动平均
- 单侧标签平滑
- 输入规范化
- 批规范化
- 利用Relu和MaxPool避免稀疏梯度
- 优化器和噪声
- 不要仅根据统计信息平衡损失
以上为学习GAN的记录和总结
reference:
[1] GAN实战生成对抗网络 [美] Kuntal Ganguly著
[2] imooc 深度学习实战CNN RNN GAN
[3] https://blog.csdn.net/u012223913/article/details/75051516
用Tensorflow实现DCGAN的更多相关文章
- 『TensorFlow』DCGAN生成动漫人物头像_下
『TensorFlow』以GAN为例的神经网络类范式 『cs231n』通过代码理解gan网络&tensorflow共享变量机制_上 『TensorFlow』通过代码理解gan网络_中 一.计算 ...
- DCGAN in Tensorflow生成动漫人物
引自:GAN学习指南:从原理入门到制作生成Demo 生成式对抗网络(GAN)是近年来大热的深度学习模型.最近正好有空看了这方面的一些论文,跑了一个GAN的代码,于是写了这篇文章来介绍一下GAN. 本文 ...
- 史上最全TensorFlow学习资源汇总
来源 | 悦动智能(公众号ID:aibbtcom) 本篇文章将为大家总结TensorFlow纯干货学习资源,非常适合新手学习,建议大家收藏. ▌一 .TensorFlow教程资源 1)适合初学者的Te ...
- 【干货】史上最全的Tensorflow学习资源汇总
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 作者:AI小昕 在之前的Tensorflow系列文章中,我们教大家 ...
- GAN 转
生成式对抗网络(GAN)是近年来大热的深度学习模型.最近正好有空看了这方面的一些论文,跑了一个GAN的代码,于是写了这篇文章来介绍一下GAN. 本文主要分为三个部分: 介绍原始的GAN的原理 同样非常 ...
- (zhuan) 深度学习全网最全学习资料汇总之模型介绍篇
This blog from : http://weibo.com/ttarticle/p/show?id=2309351000224077630868614681&u=5070353058& ...
- 生成对抗式网络 GAN的理解
转自:https://zhuanlan.zhihu.com/p/24767059,感谢分享 生成式对抗网络(GAN)是近年来大热的深度学习模型.最近正好有空看了这方面的一些论文,跑了一个GAN的代码, ...
- 生成对抗网络(GAN)相关链接汇总
1.基础知识 创始人的介绍: “GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上) “GAN之父”Goodfellow与网友互动:关于GAN的11个问题(附视频) 进一 ...
- GAN学习指南:从原理入门到制作生成Demo,总共分几步?
来源:https://www.leiphone.com/news/201701/yZvIqK8VbxoYejLl.html?viewType=weixin 导语:本文介绍下GAN和DCGAN的原理,以 ...
随机推荐
- Vue.js中集成summernote
首先引用summernote样式及js: <!--summernote css --> <link href="${ctxPath}/static/css/summerno ...
- js DateTime函数
---恢复内容开始--- 一.js获取当前日期时间var myDate = new Date();myDate.getYear(); //获取当前年份(2位)myDate.getFull ...
- 【托业】【跨栏】TEST05
22 23 21. 22 23 24 25 REVIEW TEST05
- 基于Promise封装uni-app的request方法,实现类似axios形式的请求
https://my.oschina.net/u/2428630/blog/3004860 uni-app框架中 安装(项目根目录下运行) npm install uni-request --save ...
- 2019.04.23 Scrapy框架
1.环境搭建 2.选择需要的.whl文件下载,一般选择最后的,感觉意思是最近更新的包,以下是.whl文件下载链接地址: http://www.lfd.uci.edu/~gohlke/pythonlib ...
- [LeetCode] 55. Jump Game_ Medium tag: Dynamic Programming
Given an array of non-negative integers, you are initially positioned at the first index of the arra ...
- test request&&response 代码实现
使用工具 IDEA 创建一个登录页面和后方数据库连接 1.编写login.html文件 导入到web文件夹下 设置配置文件 druid.properties 导入jar包 放置到web文件夹下 ...
- VS2008生成解决方案卡顿、龟速
1.工具-选项-项目和解决方案-MS BUILD 项目生成输出详细信息中选择“诊断” 2.进入.NET环境的安装位置:C:\WINDOWS\Microsoft.NET\Framework\v3.5 , ...
- VC6中函数点go to definition报告the symbol XXX is undefined
删除Debug中的bsc文件,再重建所有文件即可,在该函数处点击go to definition会提示重建.bsc文件,如果不行,多操作几次.
- RSA 汇总
最近工作中遇到了RSA,这个,以前只是粗略的看了一下,结果,实际使用的时候,各种眼花缭乱啊.现在整理一下RSA有哪些相关知识. 1. RSA算法本身.算法本身的内容实际上是在pkcs#1的标准里面说明 ...