Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】所谓爬虫,就是通过编程的方式自动从网络上获取自己所需的资源,比如文章、图片、音乐、视频等多媒体资源。通过一定的方式获取到html的内容,再通过各种手段分析得到自己所需的内容,比如通过BeautifulSoup对网页内容进行解析提取。
本文通过==selenium==的==webdriver==模拟浏览器来浏览网页,通过==lxml==库解析得到咱所需的内容。下面开始我们的爬虫工作。
首先,安装好我们爬网所需的开发环境,我的开发环境如下:
- win7 x64中文版
- Visual Studio Code 1.27.2(用于作为Python的编辑器,通过插件可以支持多种语言的开发)
- Anaconda3.5.2-64bit(选择Python3版本)
- 本系列演示过程所用到的python环境以及第三方库:
- python 3.6.5 ==Anaconda预安装==
- selenium 3.14.0 ==Anaconda手动安装==
- lxml 4.2.1 ==Anaconda预安装的不包含etree,需要卸载重装,见文末方法==
- pip 10.0.1 ==Anaconda预安装==
- PyExecJS ==Anaconda没有,需要cmd执行pip安装==
这里为了方便管理Python里面的各种插件的依赖关系,我选择的是Py集成管理工具Anaconda,就像我们其它语言开发使用Maven、Gradle作为依赖库版本管理工具一样,节省自己的时间减少出错的几率。(当然你很强,也可以自己单独安装Python以及本文所用到的各种依赖包,只要不出错就好)
安装步骤:
win7系统就不用说了,大家都懂的
Visuan Studio Code(本系列后续文章内统一简称vs code)的安装也是很easy,下载后一路下一步完成就行
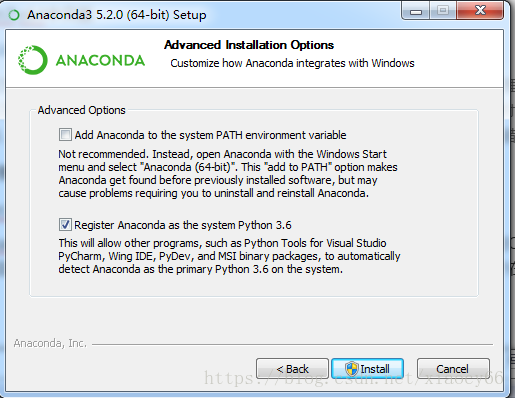
- Anaconda3.5也是从官网下来安装包双击执行一路下一步,我是默认安装在C:\ProgramData\Anaconda3,并且在安装过程中勾选了把这个安装目录作为系统Python的安装目录,
但是查了系统环境变量Path,并没有发现这个在里面,所以安装完成后我们在cmd里面输入python以及pip,是提示命令找不到的。所以不管了,干就完了,咱自己手动把以下路径添加到系统环境变量Path的值里面:
- C:\ProgramData\Anaconda3\Scripts
- C:\ProgramData\Anaconda3
- 不懂配置环境变量操作的自行du一下~
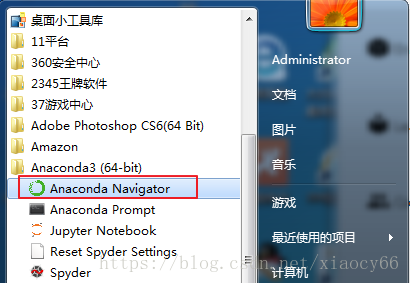
- 启动Anaconda:
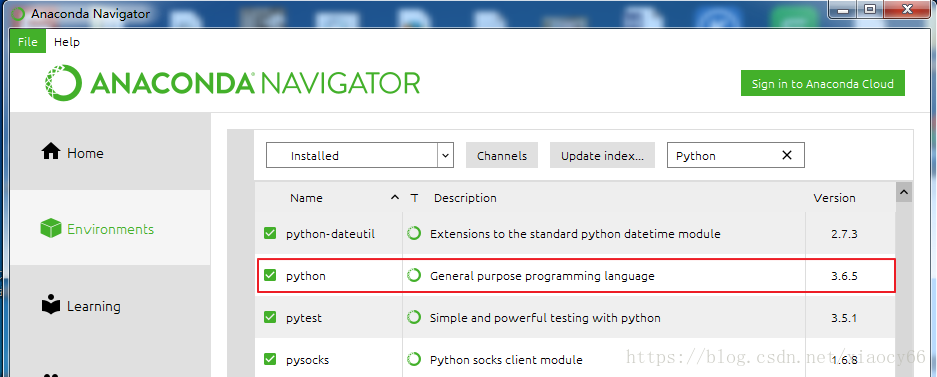
可以看到Anaconda里面已经自动帮我们安装好了Python3.6.5
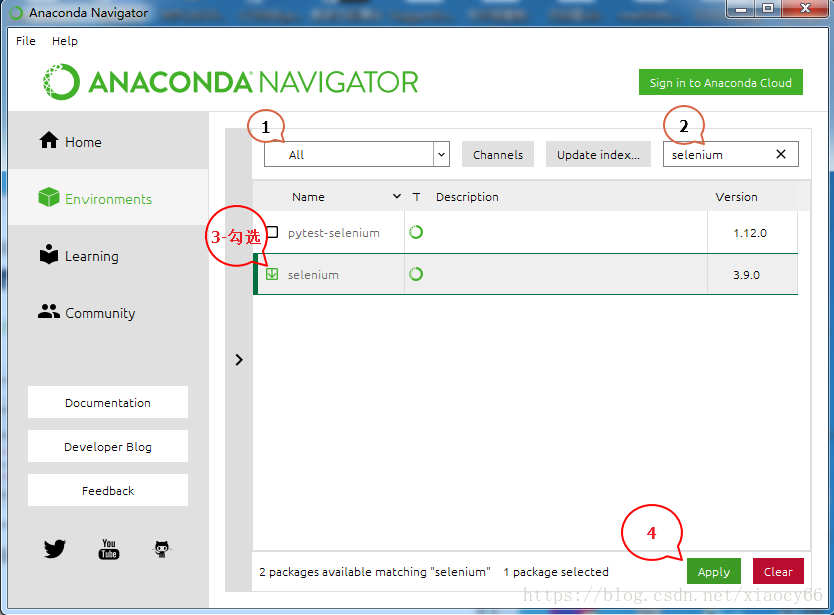
我们在这里通过anaconda继续安装后续爬网所需的selenuim框架(用这个管理工具安装的好处就是其它必须的相关依赖都会自动安装,省得自己一个一个去折腾,当然除非这个工具本身找不到你要的插件)
继续安装用户在py脚本中执行js脚本的插件:PyExecJS
打开vs code,然后按键:Ctrl + ~ 打开cmd终端
- 输入pip install PyExecJS 安装
最后,卸载Anaconda预安装的lxml,手动安装带etree的版本,否则执行代码会提示etree导入出错,有些lxml不包含etree,导致找不到指定模块,我们需要手动安装一下。
方法有很多,这里只是其中一种:在网站https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml找到符合当前python3.7版本的64位的whl文件到本机,然后cmd命令窗口cd到这个whl文件所在的目录,执行安装(先卸载之前预安装的lxml版本再安装下载的这个):
pip uninstall lxml
pip install lxml-4.2.5-cp37-cp37m-win_amd64.whl==如果你的网速较慢,点这里快速下载 lxml-4.2.5-cp37-cp37m-win_amd64.whl==
安装火狐浏览器驱动:下载地址
下载后解压放到python.exe所在目录,本文中是C:\ProgramData\Anaconda3
至此,我们把本系列操作所需的软件环境都搞定了,接下来开始我们的爬虫之旅~
全文完结,后续实现用其它框架来爬虫新闻资源。敬请期待~
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
参考资料:
[1]: X1Path语法参考
[2]: 廖雪峰老师的Python3 在线学习手册
[3]: Python3官方文档
[4]: 菜鸟学堂-Python3在线学习
[5]: 其他所有分享过python学习填坑网友的经验
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】的更多相关文章
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- 使用python-aiohttp爬取今日头条
http://blog.csdn.net/u011475134/article/details/70198533 原出处 在上一篇文章<使用python-aiohttp爬取网易云音乐>中, ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
随机推荐
- 20155324《网络对抗》Exp2 后门原理与实践
20155324<网络对抗>Exp2 后门原理与实践 20155324<网络对抗>Exp2 后门原理与实践 常用后门工具实践 Windows获得Linux Shell 在Win ...
- mac 配置jdk,maven环境变量
Java和maven环境变量配置: 1.打开终端:输入命令:vi ~/.bash_profile 2.再输入 i 进入编辑模式 输入以下: export JAVA_HOME=/Library/Java ...
- golang range遍历是新创建对象还是创建对象的引用
golang range遍历是新创建对象还是创建对象的引用,通俗的讲就是range对range出来的对象的修改会不会同步到被遍历的那个数组.先看如下代码: package main import ( ...
- 关于JS数组的栈和队列操作
1.js支持重载吗? 虽然js 本身并没有函数重载,但是可以用arguments来模拟重载,函数名相同,参数不同,arguments的length属性,获取参数个数,索引属性获取参数值 2.什么是作用 ...
- selenium定位方式-获取标签元素:find_element_by_xxx
定位方式取舍# 唯一定位方式.多属性定位.层级+角标定位(离目标元素越近,相对定位越好) # 推荐用css selector(很少用递进层次的定位)# 什么时候用xpath呢? 当你定位元素时,必须要 ...
- mock.js使用总结
基本使用: 1 引入mock.js 2 var data = Mock.mock({ // 属性 list 的值是一个数组,其中含有 1 到 10 个元素 'list|1-10': [{ // 属性 ...
- 2018-2019-2 网络对抗技术 20165221 Exp3 免杀原理与实践
2018-2019-2 网络对抗技术 20165221 Exp3 免杀原理与实践 基础问题回答 杀软是如何检测出恶意代码的? 主要依托三种恶意软件检测机制. 基于特征码的检测:一段特征码就是一段或者多 ...
- c++ Qt向PHP接口POST文件流
Qt调用PHP写的接口,向其传递图片文件,并保存在服务器. 二进制文件无法直接传递,Qt采用Base64进行编码发送,PHP解码保存为文件. 注意:PHP收到数据之后会将POST过来的数据中的加号(+ ...
- 解决sqlite 删除记录后数据库文件大小不变
最的做的项目中要有到sqlite数据存储,写了测试程序进行测试,存入300万条记录,占用flash大小为 86.1M,当把表中的记录全部删除后发后数据库文件大小依然是 86.1M: 原因是:sqlit ...
- JUC--闭锁 CountDownLatch
CountDownLatch是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,允许一个或者多个线程一直等待. 闭锁可以延迟线程的进度直到其到达终止状态,可以确保某些活动知道其他活动都完成才继续 ...