python web1(解析url)
环境:pycharm
尝试对地址进行切片 去掉头 http 或 https
a.遇到了一些问题
- url = 'https://www.cnblogs.com/derezzed/articles/8119592.html'
- #检查协议
- protocl = "http"
- if url[:7] =="http://":
- u = url.split('://')[1]
- elif url[:8] == "https://":
- protocl = "https"
- u = url.split("://")
- else:
- u = url
- print(u)

发现无任何输出
- url = 'https://www.cnblogs.com/derezzed/articles/8119592.html'
- #检查协议
- protocl = "http"
- if url[:7] =="http://":
- u = url.split('://')[1]
- print(u)
- elif url[:8] == "https://":
- protocl = "https"
- u = url.split("://")
- print(u)
- else:
- u = url
- print(u)

修改后看到了结果 至于为何 暂不知道原因
b.按着教程 边理解 边写出的解析url程序 (此程序有问题)
- #url = 'http://movie.douban.com/top250'
#解析url 返回一个tuple 包含 protocol host path port- def parsed_url(url):
#检查协议- protocol = 'http'
if url[:7] == 'http://':
a = url.split('://')[1]- elif url[:8] == 'https://':
a = url.split('https://')[1]
protocol = 'https'- #检查默认path
i = a.find('/')
if(i == -1):
path = '/'
host = a
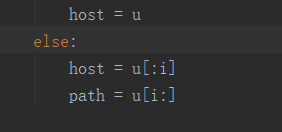
else:
host = a[:16]
path = a[6:]- #检查端口
port_dict = {
'http': 80,
'https' : 443,
}
#默认端口
port = port_dict[protocol]
if ':' in host:
h = host.split(':')
host = h[0]
port = int (h[1])- return protocol, host, port, path
写完后发现编译器一直报错 对着源程序反复确认还是找不到问题所在 一直报错
“python illegal target for variable annotation”
最后发现是缩进问题 详情查看我的 python learn 或者搜索python的缩进要求
而后加入测试程序
- def test_parsed_url():
- """
- parsed_url 函数很容易出错, 所以我们写测试函数来运行看检测是否正确运行
- """
- http = 'http'
- https = 'https'
- host = 'g.cn'
- path = '/'
- test_items = [
- ('http://g.cn', (http, host, 80, path)),
- ('http://g.cn/', (http, host, 80, path)),
- ('http://g.cn:90', (http, host, 90, path)),
- ('http://g.cn:90/', (http, host, 90, path)),
- #
- ('https://g.cn', (https, host, 443, path)),
- ('https://g.cn:233/', (https, host, 233, path)),
- ]
- for t in test_items:
- url, expected = t
- u = parsed_url(url)
- # assert 是一个语句, 名字叫 断言
- # 如果断言成功, 条件成立, 则通过测试, 否则为测试失败, 中断程序报错
- e = "parsed_url ERROR, ({}) ({}) ({})".format(url, u, expected)
- assert u == expected, e
发现还是不对 虽然报错很明显 但依然不知道错在哪里 冷静下来观察错误

这里看到 错误已经很明显 给出了来源 自己写的(其实是仿着写的qwq)所以没有意识到自己写的expected函数连正确答案都显示出来了 (汗)
最终 马上意识到 host path是有问题的 将 i 替换成了具体数字 修改后错误消失

error 0 了 啊太棒了 !!! 加油~~~
python web1(解析url)的更多相关文章
- Python 的 urllib.parse 库解析 URL
Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url urlparse() 函数可以将 URL 解析成 ParseResult 对象.对象中包含了六 ...
- Python - Django - 命名 URL 和反向解析 URL
命名 URL: test.html: <!DOCTYPE html> <html lang="en"> <head> <meta char ...
- Python 文本解析器
Python 文本解析器 一.课程介绍 本课程讲解一个使用 Python 来解析纯文本生成一个 HTML 页面的小程序. 二.相关技术 Python:一种面向对象.解释型计算机程序设计语言,用它可以做 ...
- Python XML解析之ElementTree
参考网址: http://www.runoob.com/python/python-xml.html https://docs.python.org/2/library/xml.etree.eleme ...
- python dpkt解析ssl流
用法:python extract_tls_flow.py -vr white_pcap/11/2018-01-10_13-05-09_2.pcap -o pcap_ssl_flow.txt & ...
- urlparse模块(专门用来解析URL格式)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #urlparse模块(专门用来解析URL格式) #URL格式: #protocol ://hostname[ ...
- 关于Python json解析过程遇到的TypeError: expected string or buffer
关于Python json解析过程遇到的问题:(爬取天气json数据所遇到的问题http://tianqi.2345.com/) part.1 url——http://tianqi.2345.com/ ...
- Django---路由系统,URLconf的配置,正则表达式的说明(位置参数),分组命名(捕获关键字参数),传递额外的参数给视图,命名url和url的反向解析,url名称空间
Django---路由系统,URLconf的配置,正则表达式的说明(位置参数),分组命名(捕获关键字参数),传递额外的参数给视图,命名url和url的反向解析,url名称空间 一丶URLconf配置 ...
- python抽取指定url页面的title方法
python抽取指定url页面的title方法 今天简单使用了一下python的re模块和lxml模块,分别利用的它们提供的正则表达式和xpath来解析页面源码从中提取所需的title,xpath在完 ...
随机推荐
- C#WFM关于PICBOX 再DIP界面放大125%后,图片显示不完整
外观哪里选中Zoom,就好
- Anaconda安装出现Failed to create Anaconda menus错误及其解决
我在自己的电脑上安装Anaconda3.6没有出现这个错误(win7系统),在公司的电脑(win10系统)上安装则出现了这个错误,且之前都已经安装了python3.6.需要使用如下方法解决: 安装时选 ...
- Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen 东方电气采购的页面看似很友好,实际上并不好爬取 在观察网页的审查元素之后发现,1处的网页响应只是单纯的一 ...
- op 和 oo 的区别
本是之前一位前辈留下的问题,因为我不是程序出身,略懂一些代码,后又查了很多人的博客,问了周围搞开发的朋友,得出以下结论: 有人这么形容OP和OO的不同:用面向过程的方法写出来的程序是一份蛋炒饭,而用面 ...
- fiddler 抓包工具(新猿旺学习总结)
安装抓包工具 Fiddler 直接安装 fiddler下载连接:https://www.lanzous.com/i30k09c 设置 fiddler 因为 r fiddler 是抓取 P HTTP 和 ...
- Html5 Page Creator,简易h5页面场景制作
- c++的虚继承
今天去面试了一家公司,真是套路深啊,套路深,原谅我是后知后觉,所以人吧总的长大,出差正常情况下都是有补贴的,为啥这部分也要算我工资一部分,名其名曰工资高,哈哈哈,自古套路方得人心 今天学习了一下c++ ...
- 【BZOJ5194】Snow Boots
[原题题面]传送门 [简化题意] 给定一个长度为n的序列. 有m次询问,每次询问给定两个数si,di.你一开始站在0,每次你可以走不超过di,但你到达的位置的数不能超过si.问能否走到n+1. n,m ...
- 如何改变vim中的光标形状 : 在插入状态下显示为 beam?而在 其他 状态下 为 block?
分成两种情况来说明: 如果是在 shell 即: gnome-termial终端中, 来启动或 使用 vim的话, 你是 无法 实现这种需求的: 改变vim中的光标形状 : 在插入状态下显示为 bea ...
- 纸小墨ink简洁主题story爱上你的故事
主题介绍 为纸小墨写的一款主题,该主题移植自Yumoe github地址:ink-theme-story Demo ink-theme-story 主题的一些食用说明 菜单 标题旁边有一个 · 字符, ...