DFS和BFS
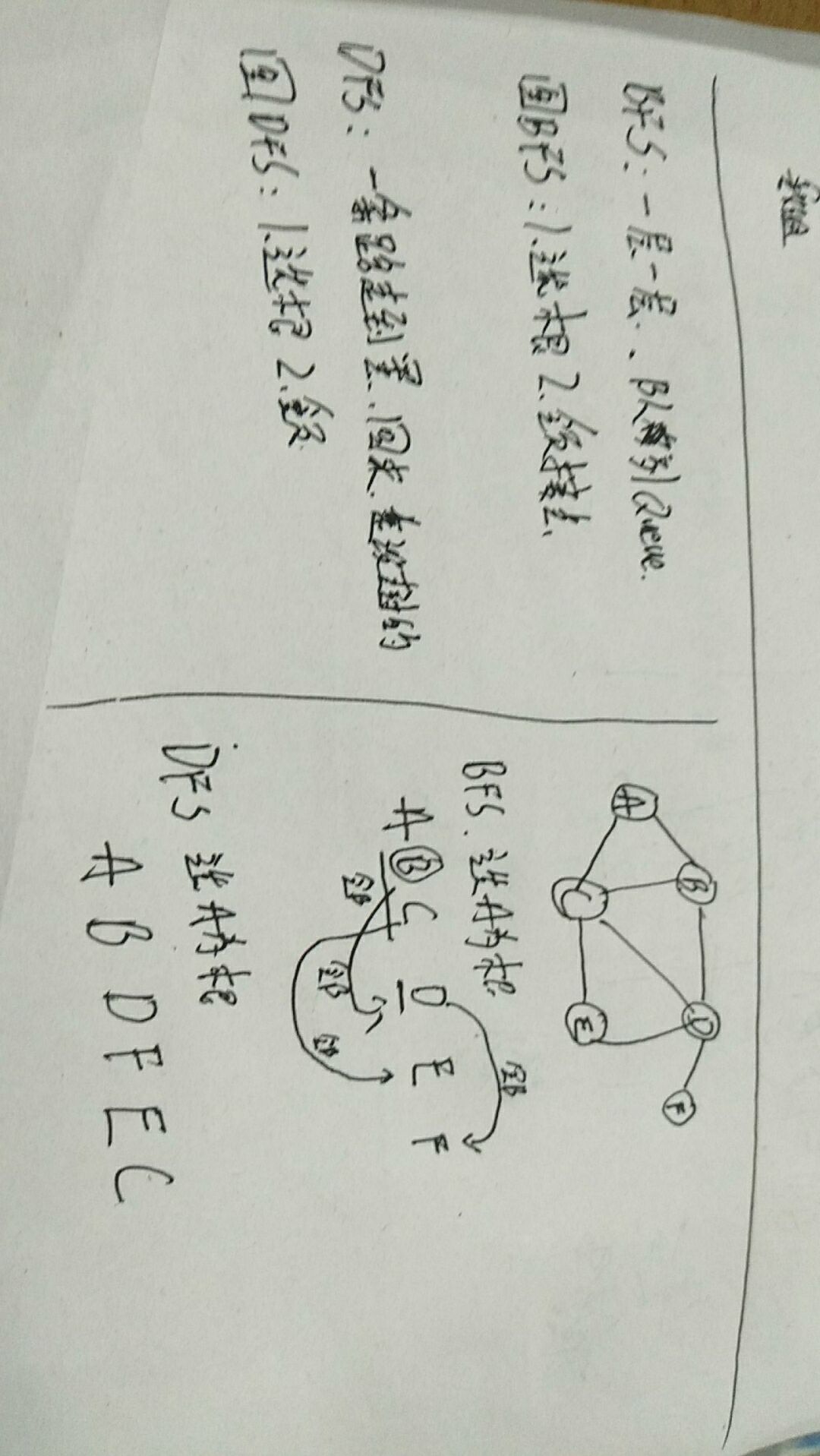
BFS
代码步骤:
1、写出每个点和每个点的邻接点的对应关系
2、方法参数:传一个对应关系和起始点
3、创建一个队列,然后每次都移除第一个,然后把移除的邻接点添加进去,打印取出的第一个,然后循环,一直到队列没有元素
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class BFS {
public static void main(String[] args) {
List list = new ArrayList();//A的邻接点
list.add("B");
list.add("C"); List list2 = new ArrayList();//B的邻接点
list2.add("A");
list2.add("C");
list2.add("D"); List list3 = new ArrayList();//C的邻接点
list3.add("A");
list3.add("B");
list3.add("D");
list3.add("E"); List list4 = new ArrayList();//D的邻接点
list4.add("B");
list4.add("C");
list4.add("E");
list4.add("F"); List list5 = new ArrayList();//E的邻接点
list5.add("C");
list5.add("D"); List list6 = new ArrayList();//F的邻接点
list6.add("D"); Map<String,List> map = new HashMap<>();//使得邻接点和该值对应上
map.put("A", list);
map.put("B", list2);
map.put("C", list3);
map.put("D", list4);
map.put("E", list5);
map.put("F", list6); BFS(map,"E"); }
/**
* 利用对列的方式
* @param map 字典
* @param s 根节点
*/
public static void BFS(Map map,String s){
List<String> queue = new ArrayList();//队列
queue.add(s);
ArrayList seen = new ArrayList();//用来放已经访问过的元素
seen.add(s);
while(queue.size()>0) {//队列没有元素位置
String vertex = (String) queue.remove(0);//每次取队列第一个元素
List<String> nodes = (List) map.get(vertex);//把vertex所有临近点
for(String w:nodes) {//遍历所有邻接点,没有包含的进入队列
if(!seen.contains(w)) {
queue.add(w);
seen.add(w);
}
}
System.out.println(vertex);
}
} }
BFS的最短路径
就是添加一个键值对,键就是该字母,值就是他的前一个字母
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class BFS最短路径 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("B");
list.add("C"); List list2 = new ArrayList();
list2.add("A");
list2.add("C");
list2.add("D"); List list3 = new ArrayList();
list3.add("A");
list3.add("B");
list3.add("D");
list3.add("E"); List list4 = new ArrayList();
list4.add("B");
list4.add("C");
list4.add("E");
list4.add("F"); List list5 = new ArrayList();
list5.add("C");
list5.add("D"); List list6 = new ArrayList();
list6.add("D"); Map<String,List> map = new HashMap<>();
map.put("A", list);
map.put("B", list2);
map.put("C", list3);
map.put("D", list4);
map.put("E", list5);
map.put("F", list6); BFS(map,"A"); }
/**
* 利用对列的方式
* @param map
* @param s
*/
public static void BFS(Map map,String s){
List<String> queue = new ArrayList();//队列
queue.add(s);
ArrayList seen = new ArrayList();//用来放已经访问过的元素
seen.add(s); Map parent = new HashMap();
parent.put(s, null);
while(queue.size()>0) {
String vertex = (String) queue.remove(0);//那队列第一个元素
List<String> nodes = (List) map.get(vertex);//把vertex所有临近点 for(String w:nodes) {//遍历所有邻接点,没有包含的进入队列
if(!seen.contains(w)) {
queue.add(w);
seen.add(w);
parent.put(w, vertex);//添加字符前一个字符
}
}
//System.out.println(vertex); }
//输出最短路径
String end = "E";
while(end!=null) {
System.out.println(end);
end = (String) parent.get(end);
} } }
DFS
就是把BFS的队列换成栈,根本区别就是变成移除最后一个了
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class DFS {
public static void main(String[] args) {
List list = new ArrayList();
list.add("B");
list.add("C"); List list2 = new ArrayList();
list2.add("A");
list2.add("C");
list2.add("D"); List list3 = new ArrayList();
list3.add("A");
list3.add("B");
list3.add("D");
list3.add("E"); List list4 = new ArrayList();
list4.add("B");
list4.add("C");
list4.add("E");
list4.add("F"); List list5 = new ArrayList();
list5.add("C");
list5.add("D"); List list6 = new ArrayList();
list6.add("D"); Map<String,List> map = new HashMap<>();
map.put("A", list);
map.put("B", list2);
map.put("C", list3);
map.put("D", list4);
map.put("E", list5);
map.put("F", list6); DFS(map,"E"); }
/**
* 利用对列的方式
* @param map
* @param s
*/
public static void DFS(Map map,String s){
List<String> stack = new ArrayList();//栈
stack.add(s);
ArrayList seen = new ArrayList();//用来放已经访问过的元素
seen.add(s);
while(stack.size()>0) {
String vertex = (String) stack.remove(stack.size()-1);//拿队列最后一个元素
List<String> nodes = (List) map.get(vertex);//把vertex所有临近点
for(String w:nodes) {//遍历所有邻接点,没有包含的进入队列
if(!seen.contains(w)) {
stack.add(w);
seen.add(w);
}
}
System.out.println(vertex);
}
} }
DFS和BFS的更多相关文章
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- 数据结构(12) -- 图的邻接矩阵的DFS和BFS
//////////////////////////////////////////////////////// //图的邻接矩阵的DFS和BFS ////////////////////////// ...
- 数据结构(11) -- 邻接表存储图的DFS和BFS
/////////////////////////////////////////////////////////////// //图的邻接表表示法以及DFS和BFS //////////////// ...
- 在DFS和BFS中一般情况可以不用vis[][]数组标记
开始学dfs 与bfs 时一直喜欢用vis[][]来标记有没有访问过, 现在我觉得没有必要用vis[][]标记了 看代码 用'#'表示墙,'.'表示道路 if(所有情况都满足){ map[i][j]= ...
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 数据结构基础(21) --DFS与BFS
DFS 从图中某个顶点V0 出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到(使用堆栈). //使用邻接矩阵存储的无向图的深度 ...
- dfs和bfs的区别
详见转载博客:https://www.cnblogs.com/wzl19981116/p/9397203.html 1.dfs(深度优先搜索)是两个搜索中先理解并使用的,其实就是暴力把所有的路径都搜索 ...
- 邻接矩阵实现图的存储,DFS,BFS遍历
图的遍历一般由两者方式:深度优先搜索(DFS),广度优先搜索(BFS),深度优先就是先访问完最深层次的数据元素,而BFS其实就是层次遍历,每一层每一层的遍历. 1.深度优先搜索(DFS) 我一贯习惯有 ...
- 判断图连通的三种方法——dfs,bfs,并查集
Description 如果无向图G每对顶点v和w都有从v到w的路径,那么称无向图G是连通的.现在给定一张无向图,判断它是否是连通的. Input 第一行有2个整数n和m(0 < n,m < ...
随机推荐
- java非阻塞NIO和阻塞IO
1 非阻塞NIO和阻塞IO 1.1 定义 阻塞IO:线程被阻塞,去处理一个读取和写入,中间如果有等待时间,则线程被占用,也不能处理其他任务: 非阻塞IO(new I ...
- printf打印输出
int PrintVal = 9; /*按整型输出,默认右对齐*/ printf("%d\n",PrintVal); /*按整型输出,补齐4位的宽度,补齐位为空格 ...
- 倍增法求LCA(最近公共最先)
对于有根树T的两个结点u.v,最近公共祖先x=LCA(u,v)表示一个结点x,满足x是u.v的祖先且x的深度尽可能大. 如图,根据定义可以看出14和15的最近公共祖先是10, 15和16的最近公共 ...
- Django的form表单
html的form表单 django中,前端如果要提交一些数据到views里面去,需要用到 html里面的form表单. 例如: # form2/urls.py from django.contrib ...
- VSCode中使用vue项目ESlint验证配置
如果在一个大型项目中会有多个人一起去开发,为了使每个人写的代码格式都保持一致,就需要借助软件去帮我们保存文件的时候,自己格式化代码 解决办法:vscode软件下载一个ESLint,在到设置里面找到se ...
- gulp打开gbk编码的html文件乱码
先上图,好忧伤:
- 用tar压缩xz格式出错
解决办法 安装xz软件包 yum install xz -y
- 继续mysql8navicat12连接登录的异常
今天登录使用navicat登录连接本地mysql,一直提示Navicat Premium 12连接MySQL数据库出现Authentication plugin 'caching_sha2_passw ...
- zzw原创_cmd下带jar包运行提示 “错误: 找不到或无法加载主类 ”
在windows下编译java,由于是临时测试一下文件,不想改classpath,就在命令行中用 -cp 或classpath引入jar包,用javac编译成功,便使用java带-cp 或classp ...
- web plugins
<build> <resources> <resource> <directory>src/main/java</directory> &l ...