sklearn pipeline
sklearn.pipeline
pipeline的目的将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
优点:
1.直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测
2.可以结合grid search对参数进行选择。
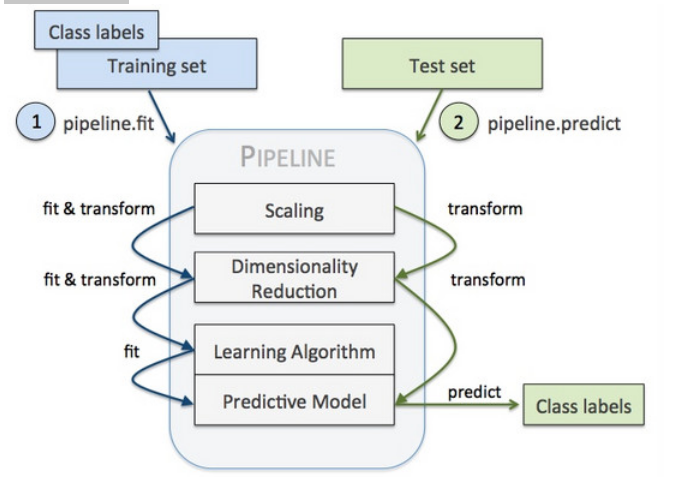
1.DictVectorizer、DecisionTreeClassifier——>pipeline模型
import pandas as pd
import numpy as np
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
titanic.head()
titanic.info()
X = titanic[['pclass','age','sex']]
y = titanic['survived']
X['age'].fillna(X['age'].mean(),inplace=True)
X.info()
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
X_train = X_train.to_dict(orient='record')
X_test = X_test.to_dict(orient='record')
#将非数值型数据转换为数值型数据
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.pipeline import Pipeline
'''
vec = DictVectorizer()
vec.fit_transform(data)
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X_train,y_train)
clf.predict(X_test)
'''
clf = Pipeline([('vecd',DictVectorizer(sparse=False)),('dtc',DecisionTreeClassifier())])
vec = DictVectorizer(sparse=False)
clf.fit(X_train,y_train)
y_predict = clf.predict(X_test)
from sklearn.metrics import classification_report
print (clf.score(X_test,y_test))
print(classification_report(y_predict,y_test,target_names=['died','survivied']))
2.结合GridSearch进行参数调优
from sklearn.datasets import fetch_20newsgroups
import numpy as np
news = fetch_20newsgroups(subset='all')
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33)
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
X_count_train = vec.fit_transform(X_train)
X_count_test = vec.transform(X_test)
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
#使用pipeline简化系统搭建流程,将文本抽取与分类器模型串联起来
clf = Pipeline([
('vect',TfidfVectorizer(stop_words='english')),('svc',SVC())
])
# 注意,这里经pipeline进行特征处理、SVC模型训练之后,得到的直接就是训练好的分类器clf
parameters = {
'svc__gamma':np.logspace(-2,1,4),
'svc__C':np.logspace(-1,1,3),
'vect__analyzer':['word']
}
#n_jobs=-1代表使用计算机的全部CPU
from sklearn.grid_search import GridSearchCV
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1)
%time _=gs.fit(X_train,y_train)
print (gs.best_params_,gs.best_score_)
print (gs.score(X_test,y_test))
parameters变量里面的key都有一个前缀,不难发现,这个前缀其实就是在Pipeline中定义的操作名。二者相结合,是我们的代码变得十分简洁。
sklearn pipeline的更多相关文章
- sklearn Model-selection + Pipeline
1 GridSearch import numpy as np from sklearn.datasets import load_digits from sklearn.ensemble impor ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- sklearn 中的 Pipeline 机制 和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- sklearn 中的 Pipeline 机制
转载自:https://blog.csdn.net/lanchunhui/article/details/50521648 from sklearn.pipeline import Pipeline ...
- 利用sklearn的Pipeline简化建模过程
很多框架都会提供一种Pipeline的机制,通过封装一系列操作的流程,调用时按计划执行即可.比如netty中有ChannelPipeline,TensorFlow的计算图也是如此. 下面简要介绍skl ...
- sklearn中pipeline的用法和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 使用sklearn优雅地进行数据挖掘【转】
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
随机推荐
- crt证书iis 中引用 程序目录提示 System.UnauthorizedAccessException:拒绝访问
在站点根目录添加 Authenticated Users 权限
- 根据关键字获取高德地图poi信息
根据关键字获取高德地图poi信息 百度地图和高德地图都提供了根据关键字获取相应的poi信息的api,不过它们提供给普通开发者使用的次数有限无法满足要求.其次百度地图返回的poi中位置信息不是经纬度,而 ...
- Python随笔--代理ip
- sticky
最近有点忘了position几个取值的内容,在这里简单总结一下. position的含义是指定位类型,取值类型可以有:static.relative.absolute.fixed.inherit和st ...
- s5p6818开发板uboot网络开通
手上的开发板网络默认是不通的,但是通过阅读uboot源码,发现uboot源码中,是有对这个网络的初始化的实现的函数的,只不过是没有调用而已,所以,要手动调用这个函数,把板子的网络调通: 首先是遇到了这 ...
- 初读"Thinking in Java"读书笔记之第七章 --- 复用类
组合语法 将对象引用置于新类中,即形成类的组合. 引用初始化方法 在定义处初始化. 在类的构造器中初始化. 在使用这些对象之前,进行"惰性初始化". 使用实例初始化. 继承语法 J ...
- Sql Server 2012 集群配置
基于Windows Server 2008 R2的WSFC实现SQL Server 2012高可用性组(AlwaysOn Group) 2012年5月 微软新一代数据库产品SQL Server 201 ...
- win 10 安装 maven安装包
学习jenkins 的时候,需要用到maven,第一次搞maven,记录下 一.准备工作,下载 jdk7.0以上版本 win10操作系统 maven安装包 下载地址 如下图 二.解压安装包 我的安 ...
- 使用IdentityServer4,在一个ASPNetCore项目中,配置oidc和api的AccessToken两种认证授权
1.配置两种认证方式 JwtSecurityTokenHandler.DefaultInboundClaimTypeMap.Clear(); services.AddAuthentication(op ...
- css中关于单位的一些问题
Css中关于单位的一些问题 相对字体长度: Em:Em 是一个相对单位.起初排版度量时是基于当前字体大写字母”M”的尺寸的.当改变font-family时,它的尺寸不会发生改变,但在改变font-si ...