SQL优化方法:
1、查看连接对象
- 1 USE master
- 2 GO
- 3 --如果要指定数据库就把注释去掉
- 4 SELECT * FROM sys.[sysprocesses] WHERE [spid]>50 --AND DB_NAME([dbid])='gposdb'
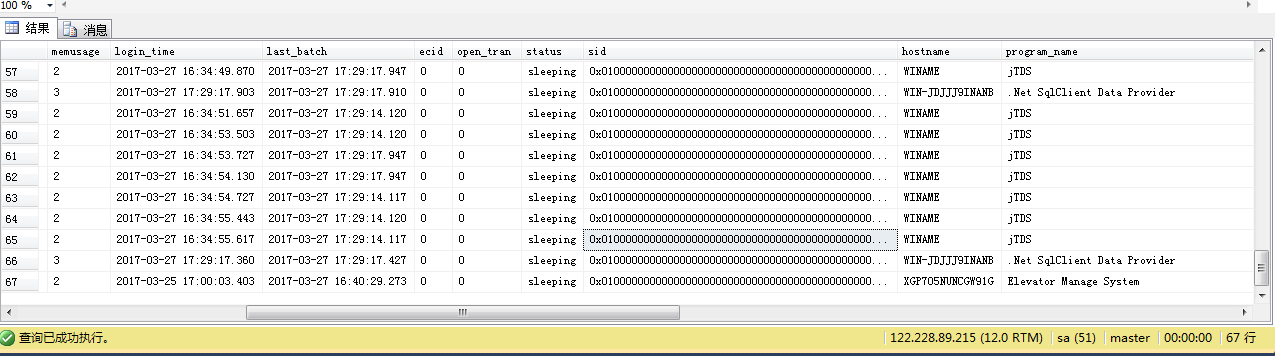
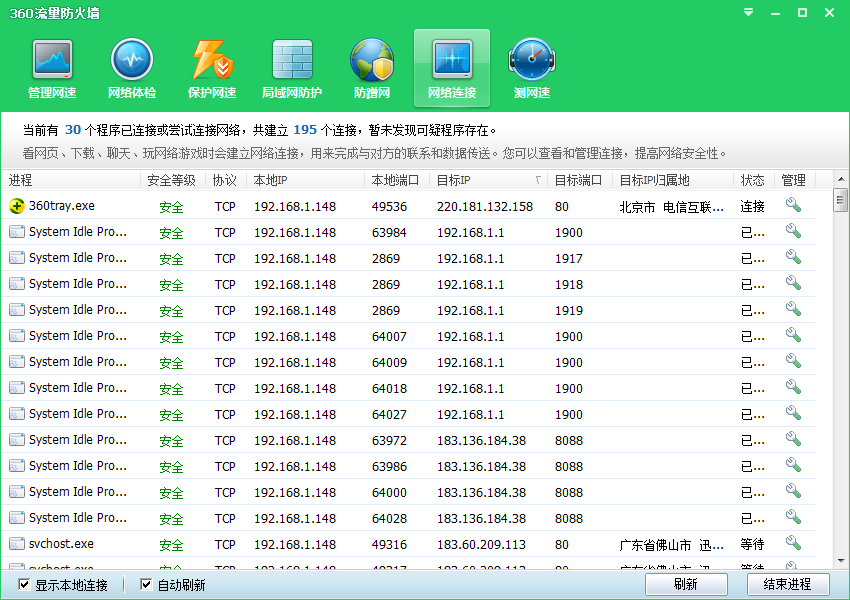
当前连接对象有67个其中‘WINAME’的主机名,‘jTDS’的进程名不属于已知常用软件,找到这台主机并解决连接问题。在360流量防火墙中查看有哪个软件连接了服务器IP,除之。
2、然后使用下面语句看一下各项指标是否正常,是否有阻塞,正常情况下搜索结果应该为空。

- 1 SELECT TOP 10
- 2 [session_id],
- 3 [request_id],
- 4 [start_time] AS '开始时间',
- 5 [status] AS '状态',
- 6 [command] AS '命令',
- 7 dest.[text] AS 'sql语句',
- 8 DB_NAME([database_id]) AS '数据库名',
- 9 [blocking_session_id] AS '正在阻塞其他会话的会话ID',
- 10 [wait_type] AS '等待资源类型',
- 11 [wait_time] AS '等待时间',
- 12 [wait_resource] AS '等待的资源',
- 13 [reads] AS '物理读次数',
- 14 [writes] AS '写次数',
- 15 [logical_reads] AS '逻辑读次数',
- 16 [row_count] AS '返回结果行数'
- 17 FROM sys.[dm_exec_requests] AS der
- 18 CROSS APPLY
- 19 sys.[dm_exec_sql_text](der.[sql_handle]) AS dest
- 20 WHERE [session_id]>50 AND DB_NAME(der.[database_id])='gposdb'
- 21 ORDER BY [cpu_time] DESC
查看是哪些SQL语句占用较大可以使用下面代码
- 1 --在SSMS里选择以文本格式显示结果
- 2 SELECT TOP 10
- 3 dest.[text] AS 'sql语句'
- 4 FROM sys.[dm_exec_requests] AS der
- 5 CROSS APPLY
- 6 sys.[dm_exec_sql_text](der.[sql_handle]) AS dest
- 7 WHERE [session_id]>50
- 8 ORDER BY [cpu_time] DESC
3、如果SQLSERVER存在要等待的资源,那么执行下面语句就会显示出会话中有多少个worker在等待
- 1 SELECT TOP 10
- 2 [session_id],
- 3 [request_id],
- 4 [start_time] AS '开始时间',
- 5 [status] AS '状态',
- 6 [command] AS '命令',
- 7 dest.[text] AS 'sql语句',
- 8 DB_NAME([database_id]) AS '数据库名',
- 9 [blocking_session_id] AS '正在阻塞其他会话的会话ID',
- 10 der.[wait_type] AS '等待资源类型',
- 11 [wait_time] AS '等待时间',
- 12 [wait_resource] AS '等待的资源',
- 13 [dows].[waiting_tasks_count] AS '当前正在进行等待的任务数',
- 14 [reads] AS '物理读次数',
- 15 [writes] AS '写次数',
- 16 [logical_reads] AS '逻辑读次数',
- 17 [row_count] AS '返回结果行数'
- 18 FROM sys.[dm_exec_requests] AS der
- 19 INNER JOIN [sys].[dm_os_wait_stats] AS dows
- 20 ON der.[wait_type]=[dows].[wait_type]
- 21 CROSS APPLY
- 22 sys.[dm_exec_sql_text](der.[sql_handle]) AS dest
- 23 WHERE [session_id]>50
- 24 ORDER BY [cpu_time] DESC
4、查询CPU占用最高的SQL语句
- 1 SELECT TOP 10
- 2 total_worker_time/execution_count AS avg_cpu_cost, plan_handle,
- 3 execution_count,
- 4 (SELECT SUBSTRING(text, statement_start_offset/2 + 1,
- 5 (CASE WHEN statement_end_offset = -1
- 6 THEN LEN(CONVERT(nvarchar(max), text)) * 2
- 7 ELSE statement_end_offset
- 8 END - statement_start_offset)/2)
- 9 FROM sys.dm_exec_sql_text(sql_handle)) AS query_text
- 10 FROM sys.dm_exec_query_stats
- 11 ORDER BY [avg_cpu_cost] DESC
5、索引缺失查询
- 1 SELECT
- 2 DatabaseName = DB_NAME(database_id)
- 3 ,[Number Indexes Missing] = count(*)
- 4 FROM sys.dm_db_missing_index_details
- 5 GROUP BY DB_NAME(database_id)
- 6 ORDER BY 2 DESC;
- 7 SELECT TOP 10
- 8 [Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0)
- 9 , avg_user_impact
- 10 , TableName = statement
- 11 , [EqualityUsage] = equality_columns
- 12 , [InequalityUsage] = inequality_columns
- 13 , [Include Cloumns] = included_columns
- 14 FROM sys.dm_db_missing_index_groups g
- 15 INNER JOIN sys.dm_db_missing_index_group_stats s
- 16 ON s.group_handle = g.index_group_handle
- 17 INNER JOIN sys.dm_db_missing_index_details d
- 18 ON d.index_handle = g.index_handle
- 19 ORDER BY [Total Cost] DESC;
找到索引缺失的表,根据查询结果中的关键次逐一建立索引。
SQL优化方法:的更多相关文章
- DB-SQL-MySQL-杂项-调优:Mysql千万以上数据优化、SQL优化方法
ylbtech-DB-SQL-MySQL-杂项-调优:Mysql千万以上数据优化.SQL优化方法 1.返回顶部 1. 1,单库表别太多,一般保持在200以下为宜 2,尽量避免SQL中出现运算,例如se ...
- sql优化方法学习和总结
首先要问自己几个问题: 哪些类型的sql会散发出坏味道? sql优化的基本原理是什么,为什么有的sql快有的慢? sql优化和底层的存储引擎关系大么? 怎么看执行过程? 优化建议 1. 缓存查询,sq ...
- 常见SQL优化方法
SQL优化的一些方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否 ...
- mysql索引sql优化方法、步骤和经验
MySQL索引原理及慢查询优化 http://blog.jobbole.com/86594/ 细说mysql索引 https://www.cnblogs.com/chenshishuo/p/50300 ...
- sql优化方法
1. SELECT子句中避免使用 “*” 当你想在SELECT子句中列出所有的COLUMN时,使用动态SQL列引用‘*’是一个方便的方法.不幸的是,这是一个非常低效的方法. 实际上,ORACLE在解析 ...
- 【数据库】SQL优化方法汇总
最近在研究SQL语句的优化问题. 下面是从网上搜集的,有的地方有点老了,可是还是有很多可以借鉴的地方的. 如何加快查询速度? 1.升级硬件. 2.根据查询条件,建立索引,优化索引.优化访问方式,限制结 ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
- EXPLAIN sql优化方法(2) Using temporary ; Using filesort
优化GROUP BY语句 默认情况下,MySQL对所有GROUP BY col1,col2...的字段进行排序.这与在查询中指定ORDER BY col1,col2...类似.因此,如果显式包括一 ...
- EXPLAIN sql优化方法(1) 添加索引
添加索引优化器更高效率地执行语句 假设我们有两个数据表t1和t2,每个有1000行,包含的值从1到1000.下面的查询查找出两个表中值相同的数据行: mysql> SELECT t1.i1, t ...
随机推荐
- VUE 父组件与子组件交互
1. 概述 1.1 说明 在项目过程中,会有很多重复功能在多个页面中处理,此时则需要把这些重复的功能进行单独拎出,编写公用组件(控件)进行引用.在VUE中,组件是可复用的VUE实例,此时组件中的dat ...
- Maven Install报错:Perhaps you are running on a JRE rather than a JDK?
我用的是idea,解决办法是:安装jdk,配置环境变量
- java 数组排序 插入排序法
插入排序法思想:将n个数字分为前面几个是有序数字集合,后面几个为无序集合.当然尚未排序之前,可以将n0 看为有序数集合,N1-Nn-1 看为等待排序的无序集合.从N1开始将无序数一个一个插入到有序数集 ...
- Beautiful用法总结
一.安装 通过命令:pip3 install Beautifulsoup4: 安装后运行:from bs4 import BeautifulSoup,没有报错,说明安装正常: 二.解析库 Beauti ...
- 1、阿里云ECS内部机器端口被100.117.90段的ip疯狂扫描导致业务异常
故障现象: 解决方案: 1.临时解决 iptables -I INPUT -s 100.117.0.0/12 -j DROP 2.后续解决 提交工单,寻找阿里服务. 后续定位是以前配置过的SLB在搞鬼 ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- MockPlus原型设计介绍
MockPlus原型设计介绍 在第八周的课堂上,王文娟老师在校园系统上发布了对于自行选择的原型设计软件进行资料查找以及自学的任务.因为之前的课程学习需要,我们已经大概掌握了原型设计软件Axure的使用 ...
- lsblk
linux磁盘命令-lsblk显现磁盘阵列分组 lsblk(list block devices)能列出系统上所有的磁盘. lsblk [-dfimpt] [device] 选项与参数: -d :仅列 ...
- (转)Jquery获取上级、下级或者同级的元素
下面介绍JQUERY的父,子,兄弟节点查找方法 jQuery.parent(expr) 找父亲节点,可以传入expr进行过滤,比如$("span").parent()或者$(&qu ...
- 关于JQ中,新生成的节点on绑定事件失效的解决
老旧的JQ库在做新生成DIV的click事件绑定,需要先绑定其现有的父元素,在追踪到需要事件绑定的子节点上 如以下这段代码$(".t_in").on("click&quo ...