高可用Redis(七):Redis持久化
1.什么是持久化
持久化就是将数据从掉电易失的内存同步到能够永久存储的设备上的过程
2.Redis为什么需要持久化
redis将数据保存在内存中,一旦Redis服务器被关闭,或者运行Redis服务的主机本身被关闭的话,储存在内存里面的数据就会丢失
如果仅仅将redis用作缓存的话,那么这种数据丢失带来的问题并不是非常大,只需要重启机器,然后再次将数据同步到缓存中就可以了
但如果将redis用作数据库的话,那么因为一些原因导致数据丢失的情况就不能接受
Redis的持久化就是将储存在内存里面的数据以文件形式保存硬盘里面,这样即使Redis服务端被关闭,已经同步到硬盘里面的数据也不会丢失
除此之外,持久化也可以使Redis服务器重启时,通过载入同步的持久文件来还原之前的数据,或者使用持久化文件来进行数据备份和数据迁移等工作
3.Redis持久化方式
3.1 RDB(Redis DB)方式
RDB持久化功能可以将Redis中所有数据生成快照并以二进行文件的形式保存到硬盘里,文件名为.RDB文件
在Redis启动时载入RDB文件,Redis读取RDB文件内容,还原服务器原有的数据库数据
过程如下图所示:
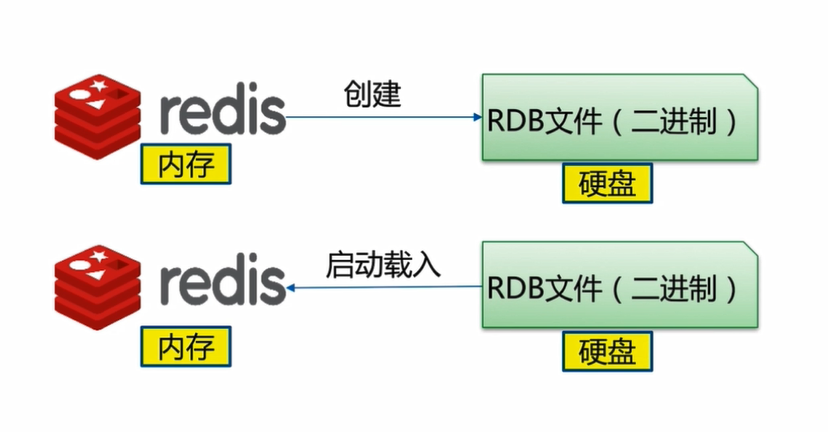
Redis服务端创建RDB文件,有三种方式
3.1.1 使用SAVE命令手动同步创建RDB文件
客户端向Redis服务端发送SAVE命令,服务端把当前所有的数据同步保存为一个RDB文件
通过向服务器发送SAVE命令,Redis会创建一个新的RDB文件
在执行SAVE命令的过程中(也就是即时创建RDB文件的过程中),Redis服务端将被阻塞,无法处理客户端发送的其他命令请求
只有在SAVE命令执行完毕之后(也就时RDB文件创建完成之后),服务器才会重新开始处理客户端发送的命令请求
如果已经存在RDB文件,那么服务器将自动使用新的RDB文件去代替旧的RDB文件
例子:
1.修改Redis的配置文件/etc/redis.conf,把下面三行注释掉
#save 900 1
#save 300 10
#save 60 10000
2.执行下面三条命令
127.0.0.1:6379> flushall # 清空Redis中所有的键值对
OK
127.0.0.1:6379> dbsize # 查看Redis中键值对数量
(integer) 0
127.0.0.1:6379> info memory # 查看Redis占用的内存数为834.26K
# Memory
used_memory:854280
used_memory_human:834.26K
used_memory_rss:5931008
used_memory_rss_human:5.66M
used_memory_peak:854280
used_memory_peak_human:834.26K
total_system_memory:2080903168
total_system_memory_human:1.94G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:6.94
mem_allocator:jemalloc-3.6.0
3.从Redis的配置文件可以知道,Redis的RDB文件保存在/var/lib/redis/目录中
[root@mysql redis]# pwd
/var/lib/redis
[root@mysql redis]# ll # 查看Redis的RDB目录下的文件
total 0
4.执行python脚本,向Redis中插入500万条数据
import redis
client = redis.StrictRedis(host='192.168.81.101',port=6379)
for i in range(5000000):
client.sadd('key' + str(i),'value'+ str(i))
5.向Redis中写入500万条数据完成后,执行SAVE命令
127.0.0.1:6379> save # 执行SAVE命令,花费5.72秒
OK
(5.72s)
6.切换另一个Redis-cli窗口执行命令
127.0.0.1:6379> spop key1 # 执行spop命令弹出'key1'的值,因为SAVE命令在执行的原因,spop命令会阻塞直到save命令执行完成,执行spop命令共花费4.36秒
"value1"
(4.36s)
7.查看Redis占用的内存数
127.0.0.1:6379> info memory # 向Redis中写入500万条数据后,Redis占用1.26G内存容量
# Memory
used_memory:1347976664
used_memory_human:1.26G
used_memory_rss:1381294080
used_memory_rss_human:1.29G
used_memory_peak:1347976664
used_memory_peak_human:1.26G
total_system_memory:2080903168
total_system_memory_human:1.94G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.02
mem_allocator:jemalloc-3.6.0
127.0.0.1:6379> dbsize # 查看Redis中数据总数
(integer) 4999999
8.在系统命令提示符中查看生成的RDB文件
[root@mysql redis]# ls -lah # Redis的RDB文件经过压缩后的大小为122MB
total 122M
drwxr-x--- 2 redis redis 22 Oct 13 15:31 .
drwxr-xr-x. 64 root root 4.0K Oct 13 13:38 ..
-rw-r--r-- 1 redis redis 122M Oct 13 15:31 dump.rdb
SAVE命令的时间复杂度为O(N)
3.1.2 使用BGSAVE命令异步创建RDB文件
执行BGSAVE命令也会创建一个新的RDB文件
BGSAVE不会造成redis服务器阻塞:在执行BGSAVE命令的过程中,Redis服务端仍然可以正常的处理其他的命令请求
BGSAVE命令执行步骤:
1.Redis服务端接受到BGSAVE命令
2.Redis服务端通过fork()来生成一个名叫redis-rdb-bgsave的进程,由redis-rdb-bgsave子进程来创建RDB文件,而Redis主进程则继续处理客户端的命令请求
3.当redis-rdb-bgsave子进程创建完成RDB文件,会向Redis主进程发送一个信号,告知Redis主进程RDB文件已经创建完毕,然后redis-rdb-bgsave子进程退出
4.Redis服务器(父进程)接手子进程创建的RDB文件,BGSAVE命令执行完毕
BGSAVE命令执行过程如下图所示
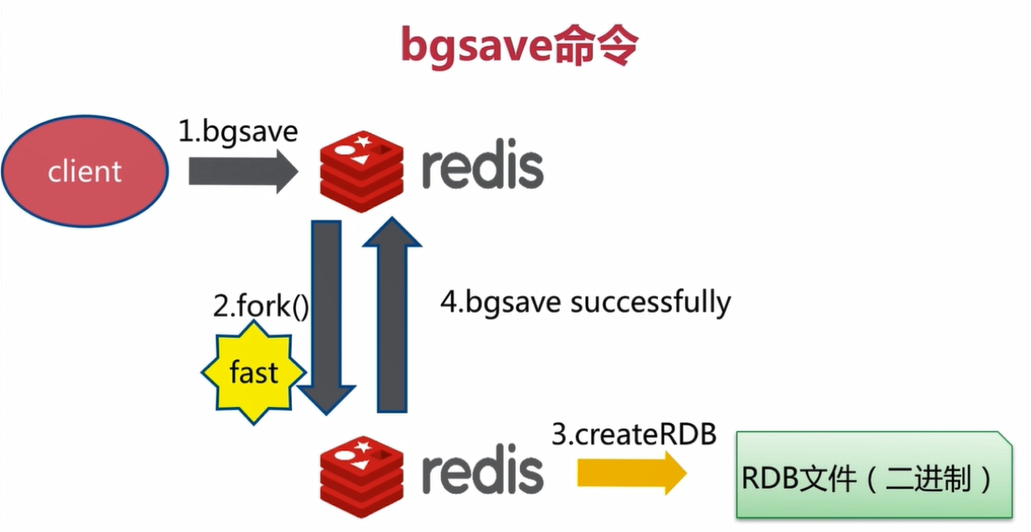
Redis主进程因为创建子进程,会消耗额外的内存
需要注意的是:如果在Redis主进程fork子进程的过程中花费的时间过多,Redis仍然可能会阻塞
BGSAVE是一个异步命令,Redis客户端向Redis服务端发送BGSAVE命令后会立即得到回复,而实际的操作在Redis服务端回复之后才开始
例子:
现在Redis中已经有500万条数据
1.删除Redis的RDB文件
[root@mysql redis]# rm -rf *.rdb # 删除Redis的旧的RDB文件
[root@mysql redis]# ll
total 0
2.在redis-cli中执行BGSAVE命令
127.0.0.1:6379> bgsave # 执行BGSAVE命令后会立即得到响应
Background saving started
3.在另一个redis-cli中执行命令
127.0.0.1:6379> spop key2 # 从Redis的集合中弹出'key2'的值
"value2"
127.0.0.1:6379> dbsize # 查看Redis中所有数据的总数
(integer) 4999998
127.0.0.1:6379> info memory # 查看Redis占用的内存数
# Memory
used_memory:1347973736
used_memory_human:1.26G # Redis占用了1.2G内存
used_memory_rss:1383464960
used_memory_rss_human:1.29G
used_memory_peak:1348224368
used_memory_peak_human:1.26G
total_system_memory:2080903168
total_system_memory_human:1.94G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.03
mem_allocator:jemalloc-3.6.0
4.在系统命令提示符中执行命令
[root@mysql redis]# ps aux | grep redis | grep -v 'redis-cli'
redis 856 3.1 66.3 1486404 1348920 ? Ssl 13:38 3:39 /usr/bin/redis-server 0.0.0.0:6379 # Redis的主进程
root 3015 0.0 0.0 112664 968 pts/3 R+ 15:36 0:00 grep --color=auto redis
[root@mysql redis]# ps aux | grep redis | grep -v 'redis-cli'
redis 856 3.0 66.3 1486404 1348956 ? Ssl 13:38 3:39 /usr/bin/redis-server 0.0.0.0:6379 # Redis的主进程
redis 3026 87.1 66.3 1486408 1348032 ? R 15:36 0:05 redis-rdb-bgsave 0.0.0.0:6379 # Redis主进程fork的子进程
root 3028 0.0 0.0 112664 968 pts/3 R+ 15:37 0:00 grep --color=auto redis
[root@mysql redis]# pwd
/var/lib/redis
[root@mysql redis]# ls -lah # 查看BGSAVE命令运行后得到的RDB文件
total 122M
drwxr-x--- 2 redis redis 22 Oct 13 15:37 .
drwxr-xr-x. 64 root root 4.0K Oct 13 13:38 ..
-rw-r--r-- 1 redis redis 122M Oct 13 15:37 dump.rdb
BGSAVE命令的时间复杂度为O(N)
SAVE命令与BGSAVE命令的区别

RDB持久化方式的总结
SAVE创建RDB文件的速度会比BGSAVE快,SAVE可以集中资源来创建RDB文件
如果数据库正在上线当中,就要使用BGSAVE
如果数据库需要维护,可以使用SAVE命令
3.1.3 自动创建RDB文件
打开Redis的配置文件/etc/redis.conf
save 900 1
save 300 10
save 60 10000
自动持久化配置解释:
save 900 1表示:如果距离上一次创建RDB文件已经过去的900秒时间内,Redis中的数据发生了1次改动,则自动执行BGSAVE命令
save 300 10表示:如果距离上一次创建RDB文件已经过去的300秒时间内,Redis中的数据发生了10次改动,则自动执行BGSAVE命令
save 60 10000表示:如果距离上一次创建RDB文件已经过去了60秒时间内,Redis中的数据发生了10000次改动,则自动执行BGSAVE命令
当三个条件中的任意一个条件被满足时,Redis就会自动执行BGSAVE命令
需要注意的是:每次执行BGSAVE命令创建RDB文件之后,服务器为实现自动持久化而设置的时间计数器和次数计数器就会被清零,并重新开始计数,所以多个保存条件的效果是不会叠加
用户也可以通过设置多个SAVE选项来设置自动保存条件,
Redis关于自动持久化的配置
rdbcompression yes 创建RDB文件时,是否启用压缩
stop-writes-on-bgsave-error yes 执行BGSAVE命令时发生错误是否停止写入
rdbchecksum yes 是否对生成RDB文件进行检验
dbfilename dump.rdb 持久化生成的备份文件的名字
dir /var/lib/redis/6379 RDB文件保存的目录
例子:
1.修改Redis配置文件/etc/redis.conf
save 900 1
save 300 10
save 60 5
2.重启Redis,删除已经创建的RDB文件
[root@mysql redis]# systemctl restart redis
[root@mysql redis]# rm -rf dump.rdb
[root@mysql redis]# pwd
/var/lib/redis
[root@mysql redis]# ls
[root@mysql redis]#
3.打开redis-cli,向Redis中设置5个value
127.0.0.1:6379> flushall # 清空Redis中已有的所有数据
OK
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> set c d
OK
127.0.0.1:6379> set e f
OK
127.0.0.1:6379> set g i
OK
4.查看Redis的日志记录
[root@mysql ~]# tail /var/log/redis/redis.log # 查看Redis日志的最后10行
3325:M 13 Oct 15:53:44.323 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
3325:M 13 Oct 15:53:44.323 # Server started, Redis version 3.2.10
3325:M 13 Oct 15:53:44.323 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
3325:M 13 Oct 15:53:44.323 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
3325:M 13 Oct 15:53:44.323 * The server is now ready to accept connections on port 6379
3325:M 13 Oct 15:55:17.431 * 5 changes in 60 seconds. Saving...
3325:M 13 Oct 15:55:17.432 * Background saving started by pid 3349
3349:C 13 Oct 15:55:17.434 * DB saved on disk
3349:C 13 Oct 15:55:17.435 * RDB: 2 MB of memory used by copy-on-write
3325:M 13 Oct 15:55:17.534 * Background saving terminated with success
5.查看Redis的持久化文件
[root@mysql redis]# pwd
/var/lib/redis
[root@mysql redis]# ls -lah
total 8.0K
drwxr-x--- 2 redis redis 22 Oct 13 15:55 .
drwxr-xr-x. 64 root root 4.0K Oct 13 13:38 ..
-rw-r--r-- 1 redis redis 115 Oct 13 15:55 dump.rdb
RDB现存问题
1.耗时耗性能
Redis把内存中的数据dump到硬盘中生成RDB文件,首先要把所有的数据都进行持久化,所需要的时间复杂度为O(N),同时把数据dump到文件中,也需要消耗CPU资源,
由于BGSAVE命令有一个fork子进程的过程,虽然不是完整的内存拷贝,而是基于copy-on-write的策略,但是如果Redis中的数据非常多,占用的内存页也会非常大,fork子进程时消耗的内存资源也会很多
磁盘IO性能的消耗,生成RDB文件本来就是把内存中的数据保存到硬盘当中,如果生成的RDB文件非常大,保存到硬盘的过程中消耗非常多的硬盘IO2.不可控,丢失数据
自动创建RDB文件的过程中,在上一次创建RDB文件以后,又向Redis中写入多条数据,如果此时Redis服务停止,则从上一次创建RDB文件到Redis服务挂机这个时间段内的数据就丢失了
3.2 AOF(AppendOnlyFile)方式
3.2.1 AOF原理
AOF创建
当向Redis中写入一条数据时,就向AOF文件中添加一条写记录
如下图所示

AOF恢复
Redis发生宕机重启后,读取AOF文件对Redis中的数据进行完整的恢复,而且使用AOF文件来恢复Redis中的数据是实时的
如下图所示
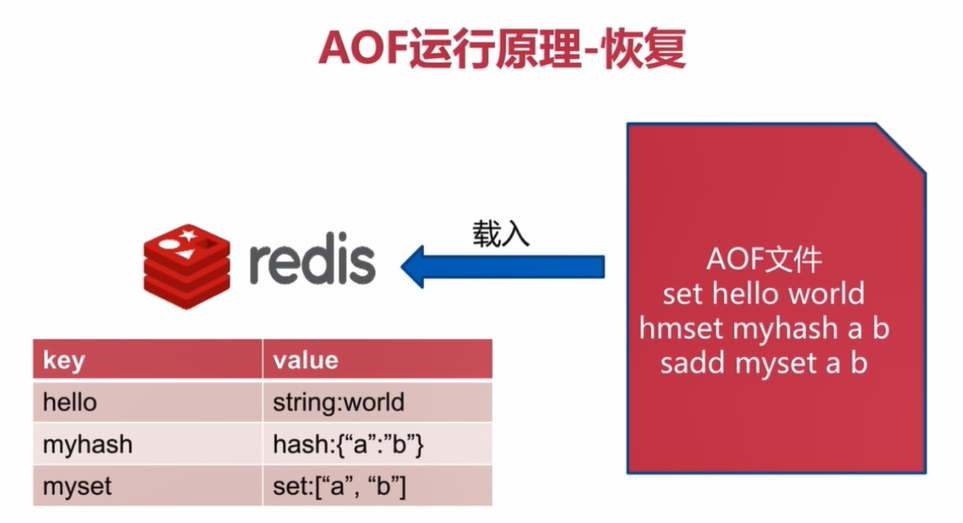
3.2.2 AOF
AOF持久化保存数据库的方法是:每当有修改的数据库的命令被执行时,服务器就会将执行的命令写入到AOF文件的末尾。
因为AOF文件里面储存了服务器执行过的所有数据库修改的命令,所以Redis只要重新执行一遍AOF文件里面保存的命令,就可以达到还原数据库的目的
3.2.3 AOF安全性问题
虽然服务器执行一次修改数据库的命令,执行的命令就会被写入到AOF文件,但这并不意味着AOF持久化方式不会丢失任何数据
在linux系统中,系统调用write函数,将一些数据保存到某文件时,为了提高效率,系统通常不会直接将内容写入硬盘里面,而是先把数据保存到硬盘的缓冲区之中。
等到缓冲区被填满,或者用户执行fsync调用和fdatasync调用时,操作系统才会将储存在缓冲区里的内容真正的写入到硬盘里
对于AOF持久化来说,当一条命令真正的被写入到硬盘时,这条命令才不会因为停机而意外丢失
因此,AOF持久化在遭遇停机时丢失命令的数量,取决于命令被写入硬盘的时间
越早将命令写入到硬盘,发生意外停机时丢失的数据就越少,而越迟将命令写入硬盘,发生意外停机时丢失的数据就越多
3.2.4 AOF三种策略
为了控制Redis服务器在遇到意外停机时丢失的数据量,Redis为AOF持久化提供了appendfsync选项,这个选项的值可以是always,everysec或者no
Always
Redis每写入一个命令,always会把每条命令都刷新到硬盘的缓冲区当中然后将缓冲区里的数据写入到硬盘里。
这种模式下,Redis即使用遭遇意外停机,也不会丢失任何自己已经成功执行的数据
Everysec
Redis每一秒调用一次fdatasync,将缓冲区里的命令写入到硬盘里,
这种模式下,当Redis的数据交换很多的时候可以保护硬盘
即使Redis遭遇意外停机时,最多只丢失一秒钟内的执行的数据
No
服务器不主动调用fdatasync,由操作系统决定任何将缓冲区里面的命令写入到硬盘里,这种模式下,服务器遭遇意外停机时,丢失的命令的数量是不确定的
3.2.5 AOF三种方式比较
运行速度:always的速度慢,everysec和no都很快
always不丢失数据,但是硬盘IO开销很多,一般的SATA硬盘一秒种只能写入几百次数据
everysec每秒同步一次数据,如果Redis发生故障,可能会丢失1秒钟的数据
no则系统控制,不可控,不知道会丢失多少数据
3.2.6 AOF重写功能简介
随着服务器的不断运行,为了记录Redis中数据的变化,Redis会将越来越多的命令写入到AOF文件中,使得AOF文件的体积来断增大
为了让AOF文件的大小控制在合理的范围,redis提供了AOF重写功能,通过这个功能,服务器可以产生一个新的AOF文件:
新的AOF文件记录的数据库数据和原有AOF文件记录的数据库数据完全一样
新的AOF文件会使用尽可能少的命令来记录数据库数据,因此新的AOF文件的体积通常会比原有AOF文件的体积要小得多
AOF重写期间,服务器不会被阻塞,可以正常处理客户端发送的命令请求

AOF重写功能就是把Redis中过期的,不再使用的,重复的以及一些可以优化的命令进行优化,重新生成一个新的AOF文件,从而达到减少硬盘占用量和加速Redis恢复速度的目的
3.2 7 AOF重写触发方式
1.向Redis发送BGREWRITEAOF命令
类似于BGSAVE命令,Redis主进程会fork一个子进程,由子进程去完成AOF重写

这里的AOF重写是将Redis内存中的数据进行一次回溯,得到一个AOF文件,而不是将已有的AOF文件重写成一个新的AOF文件
2.通过配置选项自动执行BGREWRITEAOF命令
auto-aof-rewrite-min-size
触发AOF重写所需的最小体积:只要在AOF文件的大小超过设定的size时,Redis会进行AOF重写,这个选项用于避免对体积过小的AOF文件进行重写
auto-aof-rewrite-percentage
指定触发重写所需的AOF文件体积百分比:当AOF文件的体积大于auto-aof-rewrite-min-size指定的体积,并且超过上一次重写之后的AOF文件体积的percent%时,就会触发AOF重写,如果服务器刚启动不久,还没有进行过AOF重写,那么使用服务器启动时载入的AOF文件的体积来作为基准值。
将这个值设置为0表示关闭自动AOF重写功能
只有当上面两个条件同时满足时才会触发Redis的AOF重写功能
3.2.8 AOF重写的流程
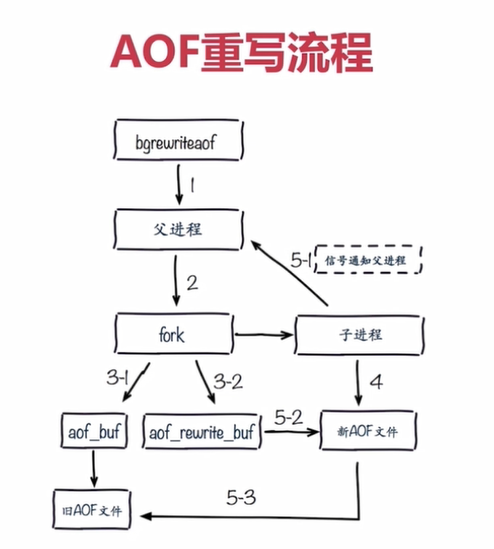
如上图所示:
1.无论是执行bgrewriteaof命令还是自动进行AOF重写,实际上都是执行BGREWRITEAOF命令
2.执行bgrewriteaof命令,Redis会fork一个子进程,
3.子进程对内存中的Redis数据进行回溯,生成新的AOF文件
4.Redis主进程会处理正常的命令操作
5.同时Redis把会新的命令写入到aof_rewrite_buf当中,当bgrewriteaof命令执行完成,新的AOF文件生成完毕,Redis主进程会把aof_rewrite_buf中的命令追加到新的AOF文件中
6.用新生成的AOF文件替换旧的AOF文件
3.2.9 配置文件中AOF相关选项
appendonly no # 改为yes,开启AOF功能
appendfilename "appendonly.aof" # 生成的AOF的文件名
appendfsync everysec # AOF同步的策略
no-appendfsync-on-rewrite no # AOF重写时,是否做append的操作
AOF重写非常消耗服务器的性能,子进程要将内存中的数据刷到硬盘中,肯定会消耗硬盘的IO
而正常的AOF也要将内存中的数据写入到硬盘当中,此时会有一定的冲突
因为rewrite的过程在数据量比较大的时候,会占用大量的硬盘的IO
在AOF重写后,生成的新的AOF文件是完整且安全的数据
如果AOF重写失败,如果设置为no则正常的AOF文件中会丢失一部分数据
生产环境中会在yes和no之间进行一定的权衡,通过优先从性能方面进行考虑,设置为yes
auto-aof-rewrite-percentage 100 # 触发重写所需的AOF文件体积增长率
auto-aof-rewrite-min-size 64mb # 触发重写所需的AOF文件大小
3.2.10 Redis的AOF功能示例
1.打开一个Redis客户端
[root@mysql ~]# redis-cli
127.0.0.1:6379> config get appendonly # 查看appendonly配置项结果
1) "appendonly"
2) "no"
127.0.0.1:6379> config set appendonly yes # 设置appendonly选项为yes
OK
127.0.0.1:6379> config rewrite # 把配置写入到文件中
OK
127.0.0.1:6379> config get appendonly # 再次查看appendonly选项结果,看修改是否写入到配置文件中
1) "appendonly"
2) "yes"
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set hello php
OK
127.0.0.1:6379> set hello python
OK
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> incr counter
(integer) 2
127.0.0.1:6379> rpush list a
(integer) 1
127.0.0.1:6379> rpush list b
(integer) 2
127.0.0.1:6379> rpush list c
(integer) 3
127.0.0.1:6379> dbsize # 查看Redis中数据量
(integer) 3
2.在系统命令提示符中查看AOF文件的大小
[root@mysql redis]# ll -h # 正常的AOF文件大小为278B
total 8.0K
-rw-r--r-- 1 redis redis 278 Oct 13 18:32 appendonly.aof
-rw-r--r-- 1 redis redis 135 Oct 13 18:32 dump.rdb
3.在Redis客户端执行AOF重写命令
127.0.0.1:6379> bgrewriteaof # 在Redis客户端中执行AOF重写命令
Background append only file rewriting started
4.再次在系统命令提示符中查看新的AOF文件大小
[root@mysql redis]# ll -h
total 8.0K
-rw-r--r-- 1 redis redis 138 Oct 13 18:33 appendonly.aof # AOF重写后文件大小为138B
-rw-r--r-- 1 redis redis 135 Oct 13 18:32 dump.rdb
[root@mysql redis]#
3.3 RDB和AOF的选择
3.3.1 RDB和AOF的比较
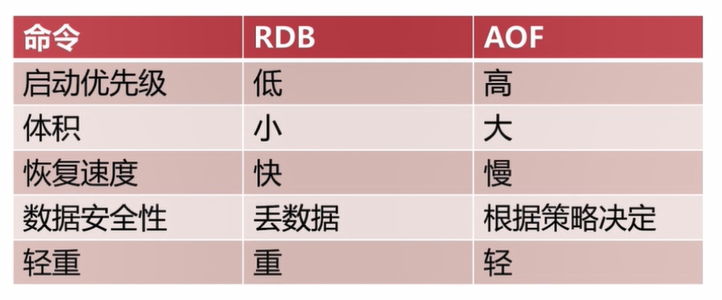
3.3.2 RDB最佳策略
- RDB是一个重操作
- Redis主从复制中的全量复制是需要主节点执行一次BGSAVE命令,然后把RDB文件同 步给从Redis从节点来实现复制的效果
- 如果对Redis按小时或者按天这种比较大的量级进行备份,使用RDB是一个不错的选择,集中备份管理比较方便
- 在Redis主从架构中,可以在Redis从节点开启RDB,可以在本机保存RDB的历史文件,但是生成RDB文件的周期不要太频繁
- Redis的单机多部署模式对服务器的CPU,内存,硬盘有较大开销,实际生产环境根据需要进行设定
3.3.3 AOF最佳策略
- 建议把appendfsync选项设定为everysec,进行持久化,这种情况下Redis宕机最多只会丢失一秒钟的数据
- 如果使用Redis做为缓存时,即使数据丢失也不会造成任何影响,只需要在下次加载时重新从数据源加载就可以了
- Redis单机多部署模式下,AOF集中操作时会fork大量的子进程,可能会出现内存爆满或者导致操作系统使用SWAP分区的情况
- 一般分配服务器60%到70%的内存给Redis使用,剩余的内存分留给类似fork的操作
3.3.4 RDB和AOF的最佳使用策略
- 使用
max_memory对Redis进行规划,例如Redis使用单机多部署模式时,每个Redis可用内存设置为4G,这样无论是使用RDB模式还是AOF模式进行持久化,fork子进程操作都只需要较小的开销 - Redis分布式时,小分片会产生更多的进程,可能会对CPU的消耗更大
- 根据缓存或者存储不同架构使用不同策略
- 使用监控软件对服务器的硬盘,内存,负载,网络进行监控,以对服务器各硬盘有更全面的了解,方便发生故障时进行定位
- 不要占用100%的内存
上面的策略,无论使用RDB还是使用AOF,都可以做为参考
4. Redis持久化开发运维问题
4.1 Redis的fork操作
Redis的fork操作是同步操作
执行BGSAVE和BGAOF命令时,实际上都是先执行fork操作,fork操作只是内存页的拷贝,而不是完全对内存的拷贝
fork操作在大部分情况下是非常快的,但是如果fork操作被阻塞,也会阻塞Redis主线程的运行
fork与内存量息息相关:Redis中数据占用的内存越大,耗时越长(与机器类型有关),可以通过info memory命令查看上次fork操作消耗的微秒数:latest_fork_usec:0
fork操作优化:
1.优先使用物理机或者高效支持fork操作的虚拟化技术
2.控制Redis实例最大可用内存:maxmemory
3.合理配置linux内存分配策略:vm.overcommit_memory = 1
4.降低fork频率,例如放宽AOF重写自动触发机制,不必要的全量复制
4.2 进程外开销
4.2.1 CPU开销
RDB和AOF文件的生成操作都属于CPU密集型
通常子进程的开销会占用90%以上的CPU,文件写入是非常密集的过程
CPU开销优化
- 1.不做CPU绑定,不要把Redis进程绑定在一颗CPU上,这样Redis fork子进程时,会分散消耗的CPU资源,不会对Redis主进程造成影响
- 2.不和CPU密集型应用在一台服务器上部署,这样不会产生CPU资源的过度竞争
- 3.在使用单机部署Redis时,不要发生大量的RDB,BGSAVE,AOF的过程,保证可以节省一定的CPU资源
4.2.2 内存开销
fork子进程会产生一定内存开销,理论上fork子进程操作占用的内存是等于父进程占用的内存
在linux系统中,有一种显式复制的机制:copy-on-write,父子进程会共享相同的物理内存页,当父进程有写请求的时候,会创建一个父本,此时才会消耗一定的内存。在这个过程中,子进程会共享fork时,父进程的内存的快照
Redis在做BGSAVE或者AOF操作fork产生子进程的过程中,如果父进程的内存页有大量的写入操作时子进程的内存开销会非常大,因为子进程会做一个父本
如果父进程没有多少写入操作时,fork操作不会占用过多的内存资源,可以在Redis的日志中看到
内存开销优化:
1.在单机部署Redis时,不要产生大量的重写,这样内存开销也会比较小
2.尽量主进程写入量比较小时,执行BGSAVE或者AOF操作
3.linux系统优化:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
4.2.3 硬盘开销
AOF和RDB文件的写入,会占用硬盘的IO及容量,可以使用iostat命令和iotop命令查看分析
硬盘开销优化:
1.不要和硬盘高负载服务部署在一起,如存储服务,消息队列等
2.修改Redis配置文件:在AOF重写期间不要执行AOF操作,以减少内存开销
no-appendfsync-on-rewrite = yes
3.根据硬盘写入量决定磁盘类型:例如使用SSD
4.单机多部署模式持久化时,文件目录可以考虑分盘。即对不同的Redis实例以端口来进行区分,持久化文件也以端口来区分
4.3 AOF追加阻塞
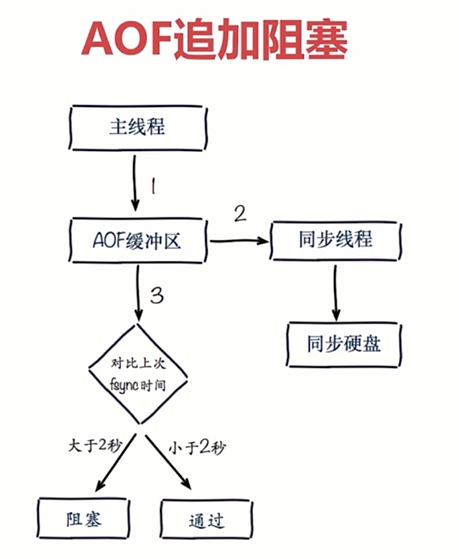
AOF一般都是一秒中执行一次
AOF追加阻塞流程
1.主线程负责写入AOF缓冲区
2.AOF同步线程每秒钟执行一次同步硬盘操作,同时还会记录一次最近一次的同步时间
3.主线程会对比上次AOF同步时间,如果距离上次同步时间在2秒之内,则返回主线程
4.如果距离上次AOF同步时间超过2秒,则主线程会阻塞,直到同步完成
AOF追加阻塞是保证AOF文件安全性的一种策略
为了达到每秒刷盘的效果,主线程会阻塞直到同步完成
这样就会产生两个问题:
因为主线程是在负责Redis日常命令的处理,所以Redis主线程不能阻塞,而此时Redis的主线程被阻塞
如果AOF追加被阻塞,每秒刷盘的策略并不会每秒都执行,可能会丢失2秒的数据
AOF阻塞定位:
如果AOF追加被阻塞,可以通过命令查看:
127.0.0.1:6379> info persistence
# Persistence
loading:0
rdb_changes_since_last_save:1
rdb_bgsave_in_progress:0
rdb_last_save_time:1539409132
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:-1
rdb_current_bgsave_time_sec:-1
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_delayed_fsync:100 # AOF被阻塞的历史次数,无法看到某次AOF被阻塞的时间点
单机多实例部署中持久化的优化可以参考硬盘开销的优化策略
5.Redis持久化总结
RDB是Redis内存数据到硬盘的快照,用于持久化
save通常会阻塞Redis
BGSAVE不会阻塞Redis,但是fork新进程会阻塞Redis
SAVE自动配置满足任一条件就会被执行高可用Redis(七):Redis持久化的更多相关文章
- Redis高可用详解:持久化技术及方案选择
文章摘自:https://www.cnblogs.com/kismetv/p/9137897.html 前言 在上一篇文章中,介绍了Redis的内存模型,从这篇文章开始,将依次介绍Redis高可用相关 ...
- Redis高可用详解:持久化技术及方案选择 (推荐)--转载自编程迷思博客www.cnblogs.com/kismetv/p/8654978.html
一.Redis高可用概述 在介绍Redis高可用之前,先说明一下在Redis的语境中高可用的含义. 我们知道,在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常 ...
- reids高可用(灾难备份-持久化)
java缓存存放到内存之中,当服务器重启以后,内存的数据将丢失,而reids作为缓存,重启reids以后 数据是不是也会丢失,redis服务器重启以后数据也不会丢失,这个是redis提供了持久化的功能 ...
- 消息中间件-ActiveMQ高可用集群和持久化机制
1.修改active.mq的xml文件 2.延时.调度消息 package com.study.mq.b1_message; import org.apache.activemq.ActiveMQCo ...
- Redis入门到高可用(十七)—— 持久化开发运维常见问题
1.fork操作 2.子进程开销和优化 3.AOF阻塞
- Redis入门到高可用(七)——Hash
一.结构 Mapmap结构: filed 不能相同,value可以相同. 二.重要指令 ♦️ HSET ♦️ HGET ♦️ HDEL ♦️ Hlen ♦️ HEXISTS ♦️HGETALL ...
- Redis的高并发、持久化、高可用架构设计
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 我这里会选用我之前讲解 ...
- Redis 高可用之"持久化"
Redis高可用概述 在Redis中,实现高可用的技术主要包括:持久化.复制(读写分离).哨兵.集群. 持久化: 持久化是最简单的高可用方法(有时甚至不被归为高可用手段),主要作用是数据备份,即将数据 ...
- Redis高可用(持久化、主从复制、哨兵、集群)
Redis高可用(持久化.主从复制.哨兵.集群) 目录 Redis高可用(持久化.主从复制.哨兵.集群) 一.Redis高可用 1. Redis高可用概述 2. Redis高可用策略 二.Redis持 ...
- 关于Redis的几件小事 | 高并发和高可用
如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了. redis高并发:主从架构,一主多从,一般 ...
随机推荐
- C++编程音视频库ffmpeg的pts时间换算方法
ffmpeg中的pts,dts,duration时间记录都是基于timebase换算,我们主要分析下pts的时间怎么换算,其它的是一样的换算.ffmpeg的时间换算对许多新接触同学算是一个大坑,很多刚 ...
- document对象获取例子
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- Codeforces Round #520 (Div. 2) B. Math 唯一分解定理+贪心
题意:给出一个x 可以做两种操作 ①sqrt(x) 注意必须是完全平方数 ② x*=k (k为任意数) 问能达到的最小的x是多少 思路: 由题意以及 操作 应该联想到唯一分解定理 经过 ...
- html-webpack-plugin不输出script标签的方法
那就是修改源码 约550行: if (!this.options.disableScript) { if (this.options.inject === 'head') { head = head. ...
- 洛谷P3268 [JLOI2016]圆的异或并(扫描线)
扫描线还不是很熟啊--不管是从想的方面还是代码实现的方面-- 关于这题,考虑一条平行于\(y\)轴的扫描线从左到右扫描每一个圆,因为只有相离和内含两种关系,只用在切线处扫描即可 我们设上半圆为1,下半 ...
- My Todo-List
有些事情要明着写出来才会去干. 这里是一个不断更新的Todo-List,大致按照重要度和列出时间排序. 主要着眼短期计划,其中的大部分事务应该在一周内解决,争取不做一只鸽子. 填好模板库的坑. 学习树 ...
- jforum(2)--中文乱码的解决方式
安装好jforum后可能出现如下乱码页面: 解决方式 1.在建数据库时要用如下语句: CREATE DATABASE JForum DEFAULT CHARACTER SET utf8 COLLATE ...
- C语言博客05--指针
C语言博客05--指针 1.本章学习总结 1.1 思维导图 1.2 本章学习体会及代码量学习体会 1.2.1 学习体会 在本周的学习过程中,我们学习了指针的用法.说实话,指针的用法有点绕,之前一直没搞 ...
- 解决:Using where; Using join buffer (Block Nested Loop)
问题:left join 时候触发了全表查询导致很慢 解决:Using where; Using join buffer (Block Nested Loop) 总结:其实就是把left join 改 ...
- Python——built-in module Help: math
Help on built-in module math: NAME math DESCRIPTION This module is always available. It provides acc ...