temporal credit assignment in reinforcement learning 【强化学习 经典论文】
Sutton 出版论文的主页:
http://incompleteideas.net/publications.html
Phd 论文: temporal credit assignment in reinforcement learning
http://incompleteideas.net/publications.html#PhDthesis
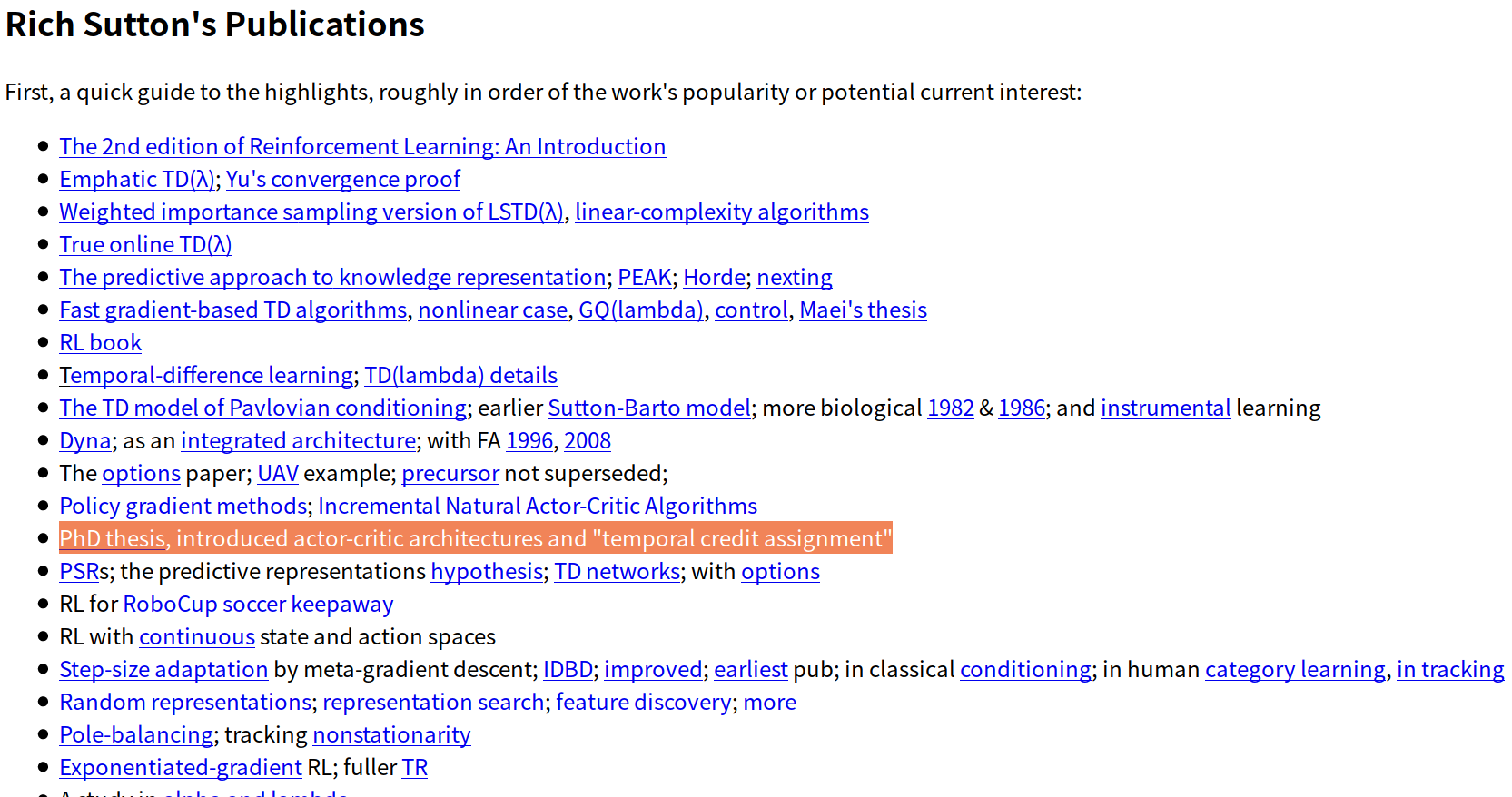
最近在做强化学习方面的课题, 发现在强化学习方面被称作强化学习之父的 Sutton 确实很厉害, TD算法和策略梯度策略算法都是他所提出的, 虽然Reinforcement learning 的现在框架是从 Q-learning 开始确定的,但是强化学习做的最早的人之一,对强化学习中经典思想的贡献最多的人估计就是Sutton了,Sutton本硕都是在MIT读的心理学,博士阶段才读的计算机,看来确实是很强的。作为强化学习最经典的论文,也是Sutton的博士毕业论文,很是值得读一读的,寻找该篇论文许久,发现可能是由于该篇论文发表的时间过久,所以所有的数据库都没有收录,唯一收入的应该是Sutton的博士授予的大学 Massachusetts 马萨诸塞州大学,但是由于该文章只向本校学生开发,所以找了几天都没有找到,今天灵机一动,为什么不到作者的个人主页上找一找呢,这一弄还果然发现了它的存在,特此mark一下。

----------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------
附:(Sutton主页 Publication部分内容)
Rich Sutton's Publications
First, a quick guide to the highlights, roughly in order of the work's popularity or potential current interest:
- The
2nd edition of Reinforcement Learning: An Introduction - Emphatic TD(λ); Yu's convergence proof
- Weighted importance sampling
version of LSTD(λ), linear-complexity algorithms - True online TD(λ)
- The predictive
approach to knowledge representation; PEAK; Horde; nexting - Fast gradient-based TD algorithms, nonlinear case, GQ(lambda),
control, Maei's thesis - RL book
- Temporal-difference learning; TD(lambda) details
- The
TD model of Pavlovian conditioning; earlier Sutton-Barto
model; more biological 1982
& 1986;
and instrumental
learning - Dyna; as an integrated
architecture; with
FA 1996, 2008 - The options paper; UAV example; precursor
not superseded; - Policy gradient methods; Incremental Natural
Actor-Critic Algorithms - PhD thesis, introduced actor-critic
architectures and "temporal credit assignment" - PSRs; the
predictive
representations hypothesis; TD networks;
with options - RL for RoboCup soccer keepaway
- RL with continuous state and action
spaces - Step-size
adaptation by meta-gradient descent; IDBD; improved; earliest pub; in classical conditioning; in human category
learning, in
tracking - Random representations; representation search; feature discovery; more
- Pole-balancing;
tracking nonstationarity - Exponentiated-gradient RL; fuller TR
- A study in alpha and lambda
- Two problems with backprop
Also, some RL pubs that aren't mine, available for researchers:
- Chris Watkins's thesis
- Boyan's LSTD(lambda),
1999 - Barto and Bradtke LSTD, 1996
- Williams, 1992
- Lin, 1992
- Ross, 1983, chapter 2
- Minsky, 1960, Steps to AI
- Good, 1965, Speculations
concerning the first ultraintelligent machine - Selfridge, 1958, Pandemonium
- Samuel, 1959
- Dayan, 1992
- Tesauro, 1992, TD-Gammon
- Watkins and Dayan, 1992
- Hamid Maei's PhD thesis,
2011 - Masoud Shahamiri's MSc
thesis, 2008 - Janey Yu's proof of
convergence of Emphatic TD(λ) - Adam
White's PhD thesis - David
Silver's PhD thesis - Brian Tanner's MSc thesis
- Kavosh Asadi's MSc thesis
- Travis Dick's MSc thesis
- Eddie Rafols MSc thesis
- Anna Koop's MSc thesis
- Leah Hackman's MSc thesis
- Mike Delp's MSc thesis
- MahdiehSadat Mirian HosseinAbadi's
MSc thesis - Gurvitz, Lin, and
Hanson, 1995 - Rupam Mahmood's PhD thesis, 2017
- An, Miller, and Parks
(1991) - Intro to Andreae (2017)
and Andreae (2017)
For any broken links, please send email to
rich@richsutton.com.
temporal credit assignment in reinforcement learning 【强化学习 经典论文】的更多相关文章
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- Reinforcement Learning 强化学习入门
https://www.zhihu.com/question/277325426 https://github.com/jinglescode/reinforcement-learning-tic-t ...
- The categories of Reinforcement Learning 强化学习分类
RL分为三大类: (1)通过行为的价值来选取特定行为的方法,具体 包括使用表格学习的 q learning, sarsa, 使用神经网络学习的 deep q network: (2)直接输出行为的 p ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- <Machine Learning - 李宏毅> 学习笔记
<Machine Learning - 李宏毅> 学习笔记 b站视频地址:李宏毅2019国语 第一章 机器学习介绍 Hand crafted rules Machine learning ...
- 【强化学习】MOVE37-Introduction(导论)/马尔科夫链/马尔科夫决策过程
写在前面的话:从今日起,我会边跟着硅谷大牛Siraj的MOVE 37系列课程学习Reinforcement Learning(强化学习算法),边更新这个系列.课程包含视频和文字,课堂笔记会按视频为单位 ...
- DQN(Deep Q-learning)入门教程(一)之强化学习介绍
什么是强化学习? 强化学习(Reinforcement learning,简称RL)是和监督学习,非监督学习并列的第三种机器学习方法,如下图示: 首先让我们举一个小时候的例子: 你现在在家,有两个动作 ...
随机推荐
- react - next.js 设置body style
因为next.js可以用pages文件夹中的js文件进行route,所以不需要public文件夹和html,因此没有body tag. body自带8px的maigin,我想要给整个页面设置背景颜色, ...
- flex布局设置width无效
子元素设置 : flex: 0 0 85px; 参数: flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto.后两个属性可选. 该属性有 ...
- MVC,MVP和MVVM三种开发模式
MVC: mvc模式:意思是软件可分为三部分: 视图(View):用户页面 控制器(Controller):控制器 模型(Model):模型 通讯方式: 1.View 传送指令到Controller ...
- mock js使用方法简单记录
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 《深入分析Java web技术内幕》读书笔记(一)
1.什么时网站 网站就是利用Html工具制作用于展示特定内容的网页集合,网站也是一种软件. 网站的开发过程需要考虑其完整性.目的性.扩展性和安全性. 2.C/S架构跟B/S架构 C/S架构:客户端和服 ...
- Thread 详解
转自:http://www.mamicode.com/info-detail-517008.html 目录(?)[-] 一扩展javalangThread类 二实现javalangRunnable接口 ...
- Java 使用 Redis存储系统
redis是一个key-value存储系统.它支持存储的value类型很多,包括string(字符串).list(链表).set(集合).zset(sorted set --有序集合)和hash(哈希 ...
- sorry
登录的时候密码忘了 重置了之后才登录上 这是有多久没登录了 好囧呀 近段时间学习Python也断断续续的 马上春节要到了 随后的20多天里 应该更没有时间学习了 想想都很忧伤 明明想很努力来着 但是总 ...
- python笔记18-高阶函数
高阶函数: 如果一个函数的入参是一个函数名的话,那这个函数就是一个高阶函数 函数即变量 # def hello(name):# print(name)# new_hello = hello#hello ...
- Linux下挂载iso文件和配置yum本地源
Linux的版本: [root@pbn ~]# head -n 1 /etc/issueRed Hat Enterprise Linux Server release 6.1 (Santiago) 1 ...