Libvmi实现分析
LibVMI是一个专注于读写虚拟机内存的自省库,它能够监视虚拟机底层的运行细节并将其还原。LibVMI支持对Xen及KVM虚拟化平台上的运行虚拟机进行自省操作,针对KVM虚拟化平台,LibVMI对QEMU进行修改以提供虚拟机物理内存的读写接口,基于LibVMI的自省程序通过本地Unix socket与QEMU进行通信,实现对特定物理地址内容的读写。本篇文章针对Libvmi读取虚拟机特定地址内容的原理进行分析。
(一)总体设计
Libvmi的总体设计如下图所示:

图中VMI Application基于LibVMI提供的相关函数进行虚拟机自省操作,如读取目标虚拟机某个虚拟地址的内容,或者获取目标虚拟机中的进程链表等。以读取目标虚拟机某个GPA(Guest Physical Address,客户机物理地址)的内容为例,简述在KVM虚拟化平台下使用LibVMI进行自省操作的流程:
第一步:VMI Application创建一个VMI实例,并给出需要读取的目标虚拟机名称及对应的GPA,交由LibVMI处理;
第二步:LibVMI基于当前所处的虚拟化平台初始化VMI实例及相关驱动函数,然后使用QMP(Qemu Monitor Protocol,qemu虚拟机协议)向qemu-kvm-patch发送创建Unix socket的命令,用于和目标虚拟机所在的qemu进程进行通信;
第三步:qemu-kvm-patch接收到QMP命令后,创建一个unix socket,作为服务器端监听来自LibVMI的请求;
第四步:LibVMI向socket server端发出连接请求,并按照相关格式发送内存读写请求,如发送读取某GPA的请求;
第五步:qemu-kvm-patch接收来自LibVMI的连接请求,并解析请求格式,调用qemu中的相关函数进行自省操作,读取目标虚拟机中对应GPA的内容,返回给Libvmi;
第六步:LibVMI接收qemu-kvm-patch返回的数据结果,将其返回至VMI Application,此次自省操作结束。
具体地,qemu-kvm-patch中使用qemu源码中提供的cpu_physical_memory_map()及cpu_physical_memory_unmap()函数进行目标虚拟机中特定地址内容的获取。上述函数通过qemu中维护的管理目标虚拟机内存的相关结构体,完成虚拟机GPA到HVA(Host Virtual Address,宿主机虚拟地址)的转换,进而读取HVA对应的内容,返回给LibVMI。对于目标虚拟机特定进程GVA(Guest Virtual Address,客户机虚拟地址)内容的获取,需首先获取该进程页表的页目录基地址,进行页表的逐级遍历,遍历过程中涉及的各级页表的GPA读取同之前所述过程,逐级遍历得到GVA对应的最终GPA并读取内容返回。可知libvmi与qemu之间的通信主要是通过qmp及本地socket实现。需注意的是不同于大多数文章描述的libvmi通过EPT页表实现地址翻译,实际上libvmi实现的地址翻译过程为:首先使用虚拟机进程的页表完成gva到gpa的转换,随后通过qemu中的函数实现gpa到hva的转换,之后直接读取该hva处的内容。(这里插一句,与qemu中对应的,kvm中的系列函数kvm_read_guest_virt,之前也一直以为是通过ept页表,实际上原理类似,也是先通过虚拟机进程页表完成gva到gpa的转换,之后根据kvm中的kvm_memslot完成gpa到hva的转换,之后读取内容,至少从源码实现上来看是这样)
(二)Libvmi读取虚拟机特定地址内容原理
(1)地址转换原理及相关函数
qemu中GPA到HVA的转换过程:为了在虚拟机退出时,能够顺利根据物理地址找到对应的HVA地址,qemu会有一个AddressSpaceDispatch结构,用来在AddressSpace中进行位置的找寻,AddressSpaceDispatch结构中有一个PhysPageMap,保存了一个GPA->HVA的一个映射,通过多层页表实现,其最后一级页表指向一个MemoryRegionSection,根据MemoryRegionSection可得到其所属的MR,然后获得实体MR指向的RAMBlock,由此得到对应的hva。当kvm exit退到qemu之后,通过AddressSpace->AddressSpaceDispatch-> map查找对应的MemoryRegionSection,继而找到对应的主机HVA。
获取进程页表
libvmi实现了虚拟机GVA到GPA的转换,GPA到HVA的转换由qemu完成,然后读取hva处的内容。在libvmi中实现gva到gpa转换时,首先根据pid确定使用的进程页表,为0时表示使用内核页表,若不为0则根据mm offset及pgd offset得到进程对应页表基地址,具体实现在linux_pid_to_pgd()中:首先通过内核符号表得到内核页表的虚拟地址(32位内核符号为swapper_pg_dir,64位为init_level4_pgt),然后通过startup_32(内核镜像入口点,地址在内核链接时生成)和phys_startup_32的差值得到内核一致映射区物理地址与虚拟地址的offset,64位则通过startup_64和phys_startup_64得到:一般而言32位下偏移为0xc0000000,64位下偏移为0xffffffff80000000:

得到内核页表的虚拟地址及page_offset之后,就可以减去page_offset得到内核页表的物理地址。如果无法直接得到page_offset,也可以先假设几个偏移(如libvmi中猜测为0xC0000000,0x80000000,0x40000000),那么页表物理地址= 页表虚拟地址 – 假设偏移。以页表物理地址作为内核页表基址,遍历页表得到页表虚拟地址对应的物理地址记为true_phys,如果true_phys与减去偏移得到的物理地址一致,说明猜测的偏移正确,否则错误并尝试下一个偏移。内核页表中也存储了内核一致映射区的相关表项,对于一致映射区,直接使用_pa(),也就是减去偏移page_offset的方式也可以得到对应的物理地址,但是页表是用于硬件寻址的,而__pa()则用于软件计算得到物理地址,因此页表中有必要存储一致映射区对应的表项。以32位为例,内核页表swapper_pg_dir在初始化的时候会把页目录的前768项空出来(768的原因:以32位10-10-12分页为例,则一共有1024个页目录项,一个页目录项指向1024个页表项,故一个页目录项表示的大小为4M,那么768项则表示3G,因此为768项),也就是只初始化了3G以上的空间,一致映射区域中虚拟地址到物理地址的映射也就会放到768项以后的页目录中。进程页表的768项之后的内容和swapper_pg_dir相同,因为内核空间是共享的。在操作3G+896M以上的虚拟内存时,只会更改swapper_pg_dir的映射信息,当别的进程访问到这些页面的时候会发生缺页,在缺页处理中会与swapper_pg_dir同步。
得到虚拟机内核页表的物理地址gpa后,就可以通过qemu将其转换为hva并读取对应的内容,也就可以遍历虚拟机的内核页表。init_task进程的虚拟地址由内核符号表得到,通过内核页表将其转换为gpa,然后根据task offset及pid offset遍历进程链表(进程描述符task_struct是存放在内核空间的,因此遍历进程链表的对应地址转换都可以通过内核页表实现),得到指定pid的进程描述符,然后根据mm_offset得到进程对应的mm_struct结构体之后根据pgd_offset得到mm. pgd的虚拟地址,然后将其转换成GPA,该转换过程由函数vmi_translate_kv2p实现,该函数中依然使用的是内核页表,说明mm_struct结构体是存放在内核空间的。
遍历虚拟机进程页表得到gpa
得到指定进程对应的页基址后,由函数vmi_pagetable_lookup_cache()完成gva到gpa的转换,该函数中如果v2p存在于建立的缓存中,则直接读取,否则根据模式调用相关函数,如v2p_pae或v2p_ia32等,该函数中进行虚拟机各级页表的转换,如函数get_pdpi()函数中,根据页表基地址加上偏移,读取该gpa处的内容。对于gva到gpa的转换,具体地,对每一级页表,首先根据gva获取其在gfn处的偏移,读取该GPA处的内容,得到下一级页表的页框号,然后根据gva得到下一级页表的offset,同样读取gpa的内容得到下一级页表的页框号,如此进行到最后一级页表。因此由一个gva得到最终的gpa的过程中需要多次读取gpa,即涉及到多次GPA到hva的转换。
读取gpa处的内容
对gpa内容的读取调用函数vmi_read_64_pa() ->vmi_read_pa() ->vmi_read() ->vmi_read_page()->drive_read_page()->kvm_read_page()->memory_cache_insert()->get_memory_data()->vmi->get_data_callback(),该回调函数设置为get_data,在kvm_setup_live_mode函数中调用函数memory_cache_init()函数将get_data初始化为kvm_get_memory_patch(),因此最终调用的是kvm_get_memory_patch()(gdb方式下为kvm_get_memory_native())kvm_get_memory_patch函数与qemu patch中的connection_handle()关联,当req.type为1时,读取对应地址的内容,调用函数connection_read_memory() -> cpu_physical_memory_map() ->address_space_map() -> address_space_translate-> address_space_translate_internal函数完成gpa到hva的转换,然后读取hva处的内容,由此得到gpa处的内容,一级级读取得到最终的gpa及其对应的内容。可知对于读取不同进程的虚拟地址,由于根据pid可以得到不同进程的页表,只要对应的gpa到hva有映射,hva有映射(无映射也会通过缺页中断将其映射到物理内存吧),就可以读取对应的内容。
(2)qemu patch的作用
简单地说,就是为了qemu进程和vmi进程能够通信:图源
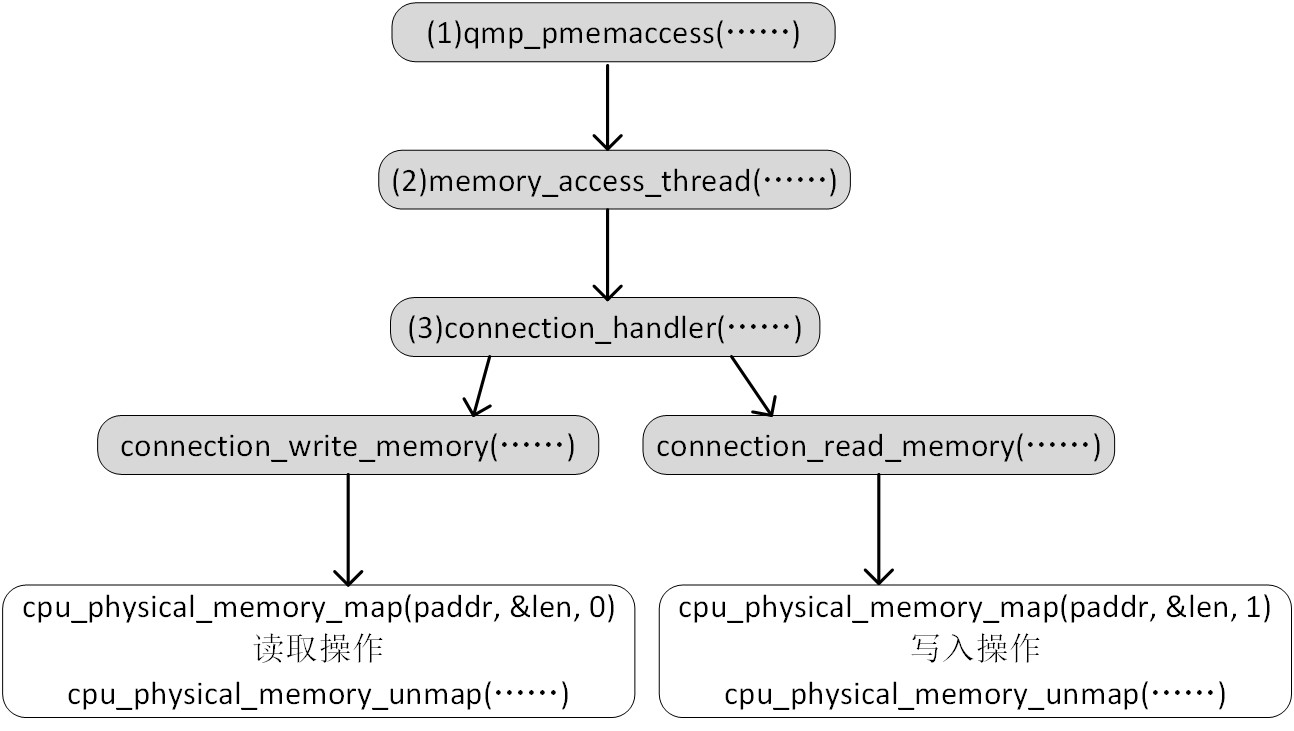
vmi实例在初始化时:vmi_init_complete() ->vmi_init() ->driver_init() ->driver_kvm_setup() -> vmi->driver.init_ptr() 实质为kvm_init(),通过libvirt连接到了本地qemu虚拟机监控程序,完成了相关函数指针的赋值。根据平台初始化驱动相关函数之后,通过驱动中定义的函数初始化vmi实例:vmi_init_complete() ->vmi_init() ->driver_init_vmi() ->kvm_init_vmi() ->kvm_setup_live_mode(),该函数进行本地通信socket的相关创建:
函数kvm_setup_live_mode() ->exec_memory_access() 向qemu虚拟机发送qmp命令建立一个本地socket,用于libvmi用户程序与qemu进程之间的通信。QMP是一种基于JSON格式的传输协议,可使用QMP与一个QEMU虚拟机实例进行交互,还可以通过修改qemu添加自定义的qmp命令用于交互,libvmi中则使用了这种方式。 Libvmi发送pmemaccess的命令,参数为对应本地socket的文件路径,qemu-patch中则添加了该命令的处理函数,即qmp_pmemaccess(),该函数根据传递的文件路径创建一个本地服务器端socket,然后监听客户端的请求。
服务端socket创建成功后,libvmi调用函数kvm_setup_live_mode() -> memory_cache_init,该函数将vmi->get_data_callback初始化为kvm_get_memory_patch,此后 vmi实例则使用该函数获取虚拟机内容,然后函数kvm_setup_live_mode()调用init_domain_socket创建客户端socket并连接到qemu的服务器端,将客户端的socket描述符保存在kvm_instance_t结构体中。服务端创建线程接受连接请求,线程执行的函数为memory_access_thread,该函数中会接受客户端的连接请求,然后调用函数connection_handler()对具体的读写请求进行处理,接收到关闭请求就关闭服务端对应的socket描述符。
当vmi实例需要读取虚拟机对应gpa的内容时,使用函数kvm_get_memory_patch()通过read/write向kvm_instance_t实例中保存的客户端socket描述符写入请求,请求包括读内存/写内存,指定gpa及读/写长度。Qemu服务端处理函数connection_handler()中为一个while(1)循环,通过连接描述符读取请求并解析,如果是读内存操作则调用connection_read_memory()进行读取,并将读取的内容写入连接描述符对应的buffer中,如果是写请求则调用connection_write_memory()对内存写,返回是否写入成功,如果是退出请求则返回并关闭服务端socket描述符。之后函数kvm_get_memory_patch()从客户端描述符对应的缓冲中读取服务端写入的数据,得到对应gpa的内容,完成一次通信。退出请求的发送:vmi_destroy() ->driver_destroy() ->kvm_destroy() ->destroy_domain_socket()发送退出请求,然后服务端客户端断开连接。每次服务端通过一个线程来处理一个客户端的连接请求及数据发送,所以可以同时运行多个vmi进程,实验对同一个虚拟机同时运行获取进程链表和模块链表的实例是可行的。
(3)偏移量的获取
对于上述过程中涉及的相关偏移量,如mm_offset等。Libvmi将自省过程需要的偏移量从虚拟机中加载内核模块得到,然后写入配置文件中,vmi_get_config函数使用lex/yacc或者flex/bison对配置文件进行解析,然后将结果返回到一个哈希表中,初始化vmi实例的时候将哈希表中的内容赋值给结构体linux_instance_t:
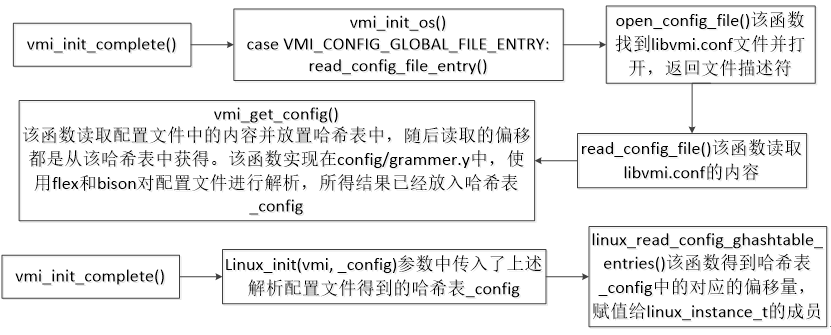
VMI应用程序中通过函数vmi_get_offset得到结构体linux_instance_t中存储的偏移量。

关于lex/yacc: https://segmentfault.com/a/1190000000396608
以上则为Libvmi读取虚拟机特定地址内容的设计及实现。
参考:Libvmi源码,qemu源码
Libvmi实现分析的更多相关文章
- alias导致virtualenv异常的分析和解法
title: alias导致virtualenv异常的分析和解法 toc: true comments: true date: 2016-06-27 23:40:56 tags: [OS X, ZSH ...
- 火焰图分析openresty性能瓶颈
注:本文操作基于CentOS 系统 准备工作 用wget从https://sourceware.org/systemtap/ftp/releases/下载最新版的systemtap.tar.gz压缩包 ...
- 一起来玩echarts系列(一)------箱线图的分析与绘制
一.箱线图 Box-plot 箱线图一般被用作显示数据分散情况.具体是计算一组数据的中位数.25%分位数.75%分位数.上边界.下边界,来将数据从大到小排列,直观展示数据整体的分布情况. 大部分正常数 ...
- 应用工具 .NET Portability Analyzer 分析迁移dotnet core
大多数开发人员更喜欢一次性编写好业务逻辑代码,以后再重用这些代码.与构建不同的应用以面向多个平台相比,这种方法更加容易.如果您创建与 .NET Core 兼容的.NET 标准库,那么现在比以往任何时候 ...
- UWP中新加的数据绑定方式x:Bind分析总结
UWP中新加的数据绑定方式x:Bind分析总结 0x00 UWP中的x:Bind 由之前有过WPF开发经验,所以在学习UWP的时候直接省略了XAML.数据绑定等几个看着十分眼熟的主题.学习过程中倒是也 ...
- 查看w3wp进程占用的内存及.NET内存泄露,死锁分析
一 基础知识 在分析之前,先上一张图: 从上面可以看到,这个w3wp进程占用了376M内存,启动了54个线程. 在使用windbg查看之前,看到的进程含有 *32 字样,意思是在64位机器上已32位方 ...
- ZIP压缩算法详细分析及解压实例解释
最近自己实现了一个ZIP压缩数据的解压程序,觉得有必要把ZIP压缩格式进行一下详细总结,数据压缩是一门通信原理和计算机科学都会涉及到的学科,在通信原理中,一般称为信源编码,在计算机科学里,一般称为数据 ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
随机推荐
- Linux -- Xshell ,Xftp远程连接中文乱码怎么解决?
### 这几天开始捣鼓lnmp的环境搭建,很多东西还是得自己去经历,才会印象深刻,有所体会,有所收获与成长! 但是,偶尔会遇到一些意想不到问题! Xshell ,Xftp 远程连接的时候出现中文乱码的 ...
- Mac 桌面软件开发基础问答
1> Mac OS X平台下的桌面软件是由什么编程语言处理 答: 由Objective-C, swift编程语言处理 2> Mac OS X平台下的桌面软件是由什么框架构建 答: 由Coc ...
- C# 在遍历中修改或者移除元素
; i >= ; i--) { var l = imgList[i].Trim(); if (!l.ToLower().Contains(".jpg") && ...
- SSL通信-忽略证书认证错误
.NET的SSL通信过程中,使用的证书可能存在各种问题,某种情况下可以忽略证书的错误继续访问.可以用下面的方式跳过服务器证书验证,完成正常通信. 1.设置回调属性ServicePointManager ...
- Redis数据结构之intset
本文及后续文章,Redis版本均是v3.2.8 上篇文章<Redis数据结构之robj>,我们说到redis object数据结构,其有5中数据类型:OBJ_STRING,OBJ_LIST ...
- java实验-3
实验内容 1.XP基础 2.XP核心实践 3.相关工具 实验内容 一.在IDEA中使用工具(Code->Reformate Code)把下面代码重新格式化,再研究一下Code菜单,找出一项让自己 ...
- Burnside引理与Polya定理 学习笔记
原文链接www.cnblogs.com/zhouzhendong/p/Burnside-Polya.html 问题模型 有一个长度为 $n$ 的序列,序列中的每一个元素有 $m$ 种取值. 如果两个序 ...
- IdentityServer4 记录
IdentityServer4 文档 https://www.cnblogs.com/edisonchou/p/identityserver4_foundation_and_quickstart_01 ...
- zabbix环境安装搭建
一.Zabbix简介 zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案.zabbix由zabbix server与可选组件zabbix agent两部分组成. ...
- RAID 0 ~ RAID 7
一.RAID解析1.RAID 0(1)将几块磁盘并行组合,横向写数据(2)并发IO,写数据最快缺点:不提供数据冗余,如果其中一块磁盘废掉,则数据全毁详细:条带深度大时,一次IO只能从一块磁盘上读取,无 ...