SDOI2017 Round2 详细题解
这套题实在是太神仙了。。做了我好久。。。好多题都是去搜题解才会的 TAT。
剩的那道题先咕着,如果省选没有退役就来填吧。
「SDOI2017」龙与地下城
题意
丢 \(Y\) 次骰子,骰子有 \(X\) 面,每一面的概率均等,取值为 \([0, X)\) ,问最后取值在 \([a, b]\) 之间的概率。
一个浮点数,绝对误差不超过 \(0.013579\) 为正确。
数据范围
每组数据有 \(10\) 次询问。
\(100\%\) 的数据,\(T \leq 10\),\(2 \leq X \leq 20\),\(1 \leq Y \leq 200000\),\(0 \leq A \leq B \leq (X − 1)Y\) ,保证满足 \(Y > 800\) 的数据不超过 2 组。
题解
一开始不难想到一个暴力做法,设 \(P(x)\) 为丢一次骰子的概率生成函数,也就是 \(\displaystyle P(x) = \sum_{i = 0}^{X - 1} \frac{1}{X} x^i\) ,我们其实就是求 \(P^Y(x)\) 的 \(x^a \sim x^b\) 项的系数之和。
我们考虑一开始用 \(FFT\) 求出 \(2^k \ge (X - 1) \times Y\) 个单位根的点值。
那么多项式乘法就可以变为点值的乘法,也就是说每个点值对应变成它的 \(Y\) 次方,就可以在 \(\mathcal O(XY \log XY)\) 的时间内处理出这个多项式的 \(Y\) 次方的答案啦。
这样在考场应该只有 \(60 \sim 70pts\) 但是由于 \(LOJ\) 机子神速,可以直接过。。。代码在这里。
至于正解,与这个前面提到那个暴力解法是完全没有关系的。。
如果你足够聪明,看懂了出题人的提示,那就会做啦。
需要知道一个 中心极限定理。
以下内容来自维基百科:
中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于 正态分布 。
设随机变量 \(X_1, X_2, \dots, X_n\) 独立同分布,并且具有有限的 数学期望 和 方差 : \(E(X_i)=μ, D(X_i)=\sigma^2 \not = 0(i=1,2,\dots, n)\)。
记 \(\displaystyle \bar{X} = \frac{1}{n} \sum_{i = 1}^{n} X_i, \zeta_n = \frac{\bar{x} - \mu}{\sigma / \sqrt n}\) ,则 \(\displaystyle \lim_{n \to \infty} P(\zeta_n \le z) = \Phi (z)\) 。
其中 \(\Phi (z)\) 是标准正态分布函数。
如果你回去上过文化课,学过统计中的正态分布应该就会啦。
说人话??好吧。。
\(n\) 个独立同分布,且具有有限的数学期望 \(\mu\) 和方差 \(\sigma ^2\) 的随机变量,他们的平均值的分布函数在 \(n \to \infty\) 时近似为位置参数为 \(\mu\) 尺度参数为 \(\sigma\) 的正态分布。
至于标准正态分布函数其实就是:
\]
也就是最后答案在 \([a, b]\) 的概率为 \(\displaystyle P(a \le X \le b) = \int_{a}^b \Phi(x) \mathrm{d}x\) 。
至于这个积分是个初等函数,并且极其光滑,那么我们利用辛普森就可以积出来了。
但是有很多点值都趋近于 \(0\) ,会被卡。
此时利用高中学的 \(3\sigma\) 原则 (2017全国一卷理科数学) ,可知, \(P(\mu - 3 \sigma < x \le \mu + 3 \sigma) \approx 0.9974\) 。
落在剩下区间的概率不足 \(0.3 \%\) 根据题目要求的精度基本可以忽略。
那么得到了最后的解法,在 \(Y\) 较小用 \(FFT\) 或者暴力卷积实现,在 \(Y\) 比较大的时候用辛普森求积分就好啦。
总结
独立同分布变量可以利用正态分布函数求积分快速计算估计值。
代码
#include <bits/stdc++.h>
#define For(i, l, r) for (register int i = (l), i##end = (int)(r); i <= i##end; ++i)
#define Fordown(i, r, l) for (register int i = (r), i##end = (int)(l); i >= i##end; --i)
#define Rep(i, r) for (register int i = (0), i##end = (int)(r); i < i##end; ++i)
#define Set(a, v) memset(a, v, sizeof(a))
#define Cpy(a, b) memcpy(a, b, sizeof(a))
#define debug(x) cout << #x << ": " << (x) << endl
using namespace std;
using vd = vector<double>;
template<typename T> inline bool chkmin(T &a, T b) { return b < a ? a = b, 1 : 0; }
template<typename T> inline bool chkmax(T &a, T b) { return b > a ? a = b, 1 : 0; }
inline int read() {
int x(0), sgn(1); char ch(getchar());
for (; !isdigit(ch); ch = getchar()) if (ch == '-') sgn = -1;
for (; isdigit(ch); ch = getchar()) x = (x * 10) + (ch ^ 48);
return x * sgn;
}
void File() {
#ifdef zjp_shadow
freopen ("2267.in", "r", stdin);
freopen ("2267.out", "w", stdout);
#endif
}
const int N = 1610;
struct Complex {
double re, im;
inline Complex friend operator + (const Complex &lhs, const Complex &rhs) {
return (Complex) {lhs.re + rhs.re, lhs.im + rhs.im};
}
inline Complex friend operator - (const Complex &lhs, const Complex &rhs) {
return (Complex) {lhs.re - rhs.re, lhs.im - rhs.im};
}
inline Complex friend operator * (const Complex &lhs, const Complex &rhs) {
return (Complex) {lhs.re * rhs.re - lhs.im * rhs.im, lhs.re * rhs.im + lhs.im * rhs.re};
}
};
const double Pi = acos(-1.0), eps = 1e-15;
namespace poly {
const int Maxn = 1 << 24;
int len, rev[Maxn];
void FFT(Complex *P, int opt) {
Rep (i, len) if (i < rev[i]) swap(P[i], P[rev[i]]);
for (int i = 2, p = 1; i <= len; p = i, i <<= 1) {
Complex Wi = (Complex) {cos(2 * Pi / i), opt * sin(2 * Pi / i)};
for (int j = 0; j < len; j += i) {
Complex x = (Complex) {1, 0};
for (int k = 0; k < p; ++ k, x = x * Wi) {
Complex u = P[j + k], v = x * P[j + k + p];
P[j + k] = u + v; P[j + k + p] = u - v;
}
}
}
if (!~opt) Rep (i, len) P[i].re /= len;
}
Complex A[Maxn], B[Maxn], C[Maxn];
inline vd operator * (const vd &a, const vd &b) {
int na = a.size() - 1, nb = b.size() - 1, nc = na + nb, cnt = 0;
for (len = 1; len <= nc; len <<= 1) ++ cnt;
Rep (i, len) rev[i] = (rev[i >> 1] >> 1) | ((i & 1) << (cnt - 1));
Rep (i, len) A[i] = (Complex) {i <= na ? a[i] : 0, 0};
Rep (i, len) B[i] = (Complex) {i <= nb ? b[i] : 0, 0};
FFT(A, 1); FFT(B, 1);
Rep (i, len) C[i] = A[i] * B[i];
FFT(C, -1);
vd res(nc + 1);
For (i, 0, nc) res[i] = C[i].re;
return res;
}
}
template<typename T>
inline T fpm(T x, int power) {
T res = x; -- power;
for (; power; power >>= 1, x = x * x)
if (power & 1) res = res * x;
return res;
}
double mu, sigma;
#define sqr(x) ((x) * (x))
double f(double x) {
return exp(- sqr(x - mu) / (2 * sqr(sigma))) / (sqrt(2 * Pi) * sigma);
}
double Asr(double l, double r) {
return (r - l) * (f(l) + 4 * f((l + r) / 2) + f(r)) / 6;
}
double Simpson(double l, double r, double area) {
double mid = (l + r) / 2, la = Asr(l, mid), ra = Asr(mid, r);
if (fabs(area - la - ra) < eps) return la + ra;
return Simpson(l, mid, la) + Simpson(mid, r, ra);
}
int main () {
File();
int cases = read();
while (cases --) {
int x = read(), y = read();
using namespace poly;
if (y <= 2000) {
int nc = (x - 1) * y, cnt = 0;
for (len = 1; len <= nc; len <<= 1) ++ cnt;
Rep (i, len) rev[i] = (rev[i >> 1] >> 1) | ((i & 1) << (cnt - 1));
Rep (i, len) A[i] = (Complex) {i < x ? 1.0 / x : 0, 0};
FFT(A, 1);
Rep (i, len) A[i] = fpm(A[i], y);
FFT(A, -1);
vd ans(nc + 1);
Rep (i, ans.size()) {
ans[i] = A[i].re;
if (i) ans[i] += ans[i - 1];
}
For (i, 1, 10) {
int l = read(), r = read();
printf ("%.6lf\n", ans[r] - (l ? ans[l - 1] : 0));
}
} else {
mu = (x - 1) / 2.0 * y;
sigma = sqrt(y * (1.0 * x * x - 1) / 12.0);
For (i, 1, 10) {
double l = max((double)read(), mu - 3 * sigma);
double r = min((double)read(), mu + 3 * sigma);
double ans = l <= r ? Simpson(l, r, Asr(l, r)) : 0;
printf ("%.6lf\n", ans);
}
}
}
return 0;
}
「SDOI2017」苹果树
题意
有 \(n\) 个点的一颗树,每个点有 \(a_i\) 个物品,权值为 \(v_i\) ,可以取走 \(t\) 个物品,取一个物品的时候它的父亲至少也要取一个物品。
假设取了物品的节点最大深度为 \(h\) 要求 \(t - h \le k\) 。
最大化最后取物品的权值和。
数据范围
\(Q\) 为数据组数。
\(1 \leq Q \leq 5\),\(1 \leq n \leq 20\,000\),\(1 \leq k \leq 500\,000\),\(1 \leq nk \leq 25\,000\,000\),\(1 \leq a_i \leq 10^8\),\(1 \leq v_i \le 100\)
题解
首先忽略 \(t\) 的要求,就是 树上依赖多重背包 。
这个怎么做呢?树上依赖背包其实就是你考虑按树的后序遍历(先儿子后根)标号。
令 \(f_{i, j}\) 为后序遍历前 \(i\) 个节点,背包大小为 \(j\) 的时候的最大权值。
然后依次转移每个点,如果这个点要选的话,那么它可以直接从 \(f_{i - 1, j - v} + w\) 转移过来,否则它不选就只能从 \(f_{i - sz, j}\) 转移过来(也就是子树内一个都不能选)。
然后由于是多重背包,二进制分组被卡了,只能单调队列优化,物品大小为 \(1\) 的话就不需要按模数分类了。具体来说,对于 \(f_{i - 1, j - kv} + kw (v = 1)\) 可以拆成 \((f_{i - 1, j - k} - (j - k) w) + jw\) 的形式。前者只与 \(j - k\) 有关,然后是要求 \([j - c, j]\) 这个的最大值,这很显然是可以用单调队列的。
最后考虑 \(t - h \le k\) 的限制是什么意思,其实就是根到一个节点路径上每个点都可以免费拿一个,剩下的拿 \(k\) 个。显然我们是选一个叶子节点是最优的,但注意不是选最深的那个叶子!
然后我们只需要考虑,这条路上都少一个容量的答案如何快速算,考虑拆点,把 \(i\) 号点拆个容量为 \(a_i - 1\) 价值为 \(v_i\) 的节点 \(i'\) 出来,把 \(i \to i'\) 连一条边。
此时原来树上每个点的容量就恰好是 \(1\) 了,新加的我们可以在外面算。
然后不难发现除了这条链的子树就是对应着后序遍历上的两段区间,我们正反各做一遍 \(dp\) 就能求出来了。
最后复杂度是 \(\mathcal O(nk)\) 的。
总结
经典背包还是要多记一下。图论还是要多想下拆点,有可能就好做许多。
代码
#include <bits/stdc++.h>
#define For(i, l, r) for (register int i = (l), i##end = (int)(r); i <= i##end; ++i)
#define Fordown(i, r, l) for (register int i = (r), i##end = (int)(l); i >= i##end; --i)
#define Rep(i, r) for (register int i = (0), i##end = (int)(r); i < i##end; ++i)
#define Set(a, v) memset(a, v, sizeof(a))
#define Cpy(a, b) memcpy(a, b, sizeof(a))
#define debug(x) cout << #x << ": " << (x) << endl
using namespace std;
template<typename T> inline bool chkmin(T &a, T b) { return b < a ? a = b, 1 : 0; }
template<typename T> inline bool chkmax(T &a, T b) { return b > a ? a = b, 1 : 0; }
inline int read() {
int x(0), sgn(1); char ch(getchar());
for (; !isdigit(ch); ch = getchar()) if (ch == '-') sgn = -1;
for (; isdigit(ch); ch = getchar()) x = (x * 10) + (ch ^ 48);
return x * sgn;
}
void File() {
#ifdef zjp_shadow
freopen ("2268.in", "r", stdin);
freopen ("2268.out", "w", stdout);
#endif
}
const int N = 40100, K = 500100, M = 5.5e7 + 10;
int n, m;
int dfn[2][N], lis[2][N], sz[N], clk;
vector<int> G[N];
int w[N], c[N], sum[N];
void Dfs_Init(int u, int id) {
sz[u] = 1; sum[u] += w[u];
for (int v : G[u])
sum[v] = sum[u], Dfs_Init(v, id), sz[u] += sz[v];
lis[id][dfn[id][u] = ++ clk] = u;
}
#define dp(id, x, y) dp[id][(x) * (m + 1) + (y)]
int dp[2][M], val[K], que[K], fr, tl;
void Dp(int id) {
For (i, 1, clk) {
int u = lis[id][i];
For (j, 0, m)
dp(id, i, j) = dp(id, i - sz[u], j);
fr = 1; tl = 0;
For (j, 0, m) {
while (fr <= tl && j - que[fr] > c[u]) ++ fr;
if (fr <= tl)
chkmax(dp(id, i, j), val[que[fr]] + j * w[u]);
val[j] = dp(id, i - 1, j) - j * w[u];
while (fr <= tl && val[que[tl]] <= val[j]) -- tl;
que[++ tl] = j;
}
}
}
bool leaf[N]; int tot;
void Init() {
Set(leaf, true);
For (i, 1, n) G[i].clear();
}
int main () {
File();
int cases = read();
while (cases --) {
Init();
tot = n = read(), m = read();
int rt = 0;
For (i, 1, n) {
int fa = read();
if (fa) {
leaf[fa] = false;
G[fa].push_back(i);
} else rt = i;
int ai = read(), vi = read(); w[i] = vi; c[i] = 1;
if (ai > 1) {
int id = ++ tot;
w[id] = vi; c[id] = ai - 1; G[i].push_back(id);
}
}
Rep (id, 2) {
sum[rt] = clk = 0, Dfs_Init(rt, id), Dp(id);
For (i, 1, n) reverse(G[i].begin(), G[i].end());
For (i, 1, n) For (j, 1, m)
chkmax(dp(id, i, j), dp(id, i, j - 1));
}
int ans = 0;
For (i, 1, n) if (leaf[i]) {
For (j, 0, m)
chkmax(ans, dp(0, dfn[0][i] - 1, j) + dp(1, dfn[1][i] - sz[i], m - j) + sum[i]);
}
For (i, 1, tot) For (j, 0, m)
dp(0, i, j) = dp(1, i, j) = 0;
printf ("%d\n", ans);
}
return 0;
}
「SDOI2017」切树游戏
题意
一棵有 \(n\) 个点的树 \(T\) ,节点带权,两种操作:
\(\text{Change x y}\) : 将编号为 \(x\) 的结点的权值修改为 \(y\) 。
\(\text{Query k}\) : 询问有多少棵 \(T\) 的非空连通子树,满足其中所有点权值的异或和恰好为 \(k\) 。
数据范围
\(n, q \le 3 \times 10^4, m \le 128\) 修改操作不超过 \(10^4\) 。
题解
动态 \(dp\) 经典题目,参考了 dy0607 的博客 orz dy。
先考虑暴力怎么做,设 \(f [ i ] [ j ]\) 表示包含 \(i\) 的连通块( \(i\) 为连通块中深度最小的节点),异或和为 \(j\) 的方案数,从下往上DP即可。
注意到在合并子树信息时实际上是在做异或卷积,可以用 \(FWT\) 优化,注意 \(FWT\) 不存在循环卷积的性质十分优秀,加减乘除全都可以在点值上做。那么可以全程用 \(FWT\) 之后的点值计算,算答案时再 \(IFWT\) 回去,此时的复杂度为 \(\mathcal O (nqm + qm \log m)\) 。
为了动态修改,我们利用重链剖分变成序列问题,设 \(i\) 重儿子为 \(j\) ,轻儿子集合为 \(child(i)\) 。
利用集合幂级数的形式来定义 \(dp\) 转移:
\]
注意 \(z_0\) 对应着转移时候的空树,统计答案的时候应该去掉。我们用另外一个幂级数 \(G\) 统计答案:
\]
我们假设把轻儿子的幂级数设为常数,即:
Gl_i(z) &= \sum_{c \in child(i)} G_c(z)\\
Fl_i(z) &= z^{v_i} \times \prod_{c \in child(i)} F_c(z)
\end{aligned}
\]
那么对于 \((F_j, G_j, 1) \to (F_i, G_i, 1)\) 是一个线性变换可以写成:
F_j & G_j & 1
\end{pmatrix}
\times
\begin{pmatrix}
Fl_i & Fl_i& 0\\
0 & 1 & 0 \\
1 & Gl_i & 1
\end{pmatrix}
=
\begin{pmatrix}
F_i & G_i & 1
\end{pmatrix} %]]>
\]
注意此处的 \(1\) 对应的就是集合幂级数的单位元 \(z_0\) 。
我们考虑用一个线段树维护矩阵的乘积,那么我们就可以动态算出重链顶端的 \(F, G\) 了。
那么每次修改的时候我们只需要考虑那些常数要怎么改了。
对于 \(Gl_i(z)\) 比较好改,假设当前修改的是 \(c \in child(i)\) 。那么只需要减掉之前的 \(G(c)\) 加上后来的 \(G'(c)\) 。
但是对于 \(Fl_i(z)\) 就不好改了,需要变换的其实就是 \(F_c(z)\) 这个先要除掉,除的时候可能会除 \(0\) ,看到网上有神仙做法是维护 \(0\) 的个数,我不太会。。
其实可以对于每个点在线段树上维护它轻儿子的 \(F_c(z)\) 的值,那么我们可以直接在线段树上修改然后求出 \(Fl_i(z)\) 的值。
其中有一个常数优化是,矩阵上 \(0\) 的跳过去,这个优化十分显著。
其实只需要维护 \(4\) 个值 \(a, b, c, d\) ,如下图。
\]
复杂度是 \(\mathcal O(qm(\log^2 n + \log m))\) 。
总结
\(ddp\) 主要就是考虑轻儿子如何贡献的,把这个当做常数递推的系数。每次修改的时候只需要修改轻儿子的贡献上来的矩阵就行了。
代码
#include <bits/stdc++.h>
#define For(i, l, r) for (register int i = (l), i##end = (int)(r); i <= i##end; ++i)
#define Fordown(i, r, l) for (register int i = (r), i##end = (int)(l); i >= i##end; --i)
#define Rep(i, r) for (register int i = (0), i##end = (int)(r); i < i##end; ++i)
#define Set(a, v) memset(a, v, sizeof(a))
#define Cpy(a, b) memcpy(a, b, sizeof(a))
#define debug(x) cout << #x << ": " << (x) << endl
#define plus Plus
using namespace std;
template<typename T> inline bool chkmin(T &a, T b) { return b < a ? a = b, 1 : 0; }
template<typename T> inline bool chkmax(T &a, T b) { return b > a ? a = b, 1 : 0; }
inline int read() {
int x(0), sgn(1); char ch(getchar());
for (; !isdigit(ch); ch = getchar()) if (ch == '-') sgn = -1;
for (; isdigit(ch); ch = getchar()) x = (x * 10) + (ch ^ 48);
return x * sgn;
}
void File() {
#ifdef zjp_shadow
freopen ("2269.in", "r", stdin);
freopen ("2269.out", "w", stdout);
#endif
}
const int N = 30100, M = 128, Mod = 10007, inv2 = (Mod + 1) / 2;
namespace Computation {
inline void add(int &a, int b) {
if ((a += b) >= Mod) a -= Mod;
}
inline int plus(int a, int b) {
return (a += b) >= Mod ? a - Mod : a;
}
inline int dec(int a, int b) {
return (a -= b) < 0 ? a + Mod : a;
}
inline int mul(int a, int b) {
return 1ll * a * b % Mod;
}
}
using namespace Computation;
int n, m, q, v[N];
struct Poly {
int x[M];
inline void clear() { Set(x, 0); }
Poly(int id = 0) {
clear(); if (id == 1) Rep (i, m) x[i] = 1;
}
inline Poly operator = (const Poly &rhs) {
Rep (i, m) x[i] = rhs.x[i]; return *this;
}
inline Poly friend operator + (const Poly &lhs, const Poly &rhs) {
Poly res;
Rep (i, m) res.x[i] = plus(lhs.x[i], rhs.x[i]);
return res;
}
inline Poly friend operator - (const Poly &lhs, const Poly &rhs) {
Poly res;
Rep (i, m) res.x[i] = dec(lhs.x[i], rhs.x[i]);
return res;
}
inline Poly friend operator * (const Poly &lhs, const Poly &rhs) {
Poly res;
Rep (i, m) res.x[i] = mul(lhs.x[i], rhs.x[i]);
return res;
}
void FWT(int opt) {
for (int i = 2, p = 1; i <= m; p = i, i <<= 1)
for (int j = 0; j < m; j += i) Rep (k, p) {
int u = x[j + k], v = x[j + k + p];
x[j + k] = mul(plus(u, v), opt == 1 ? 1 : inv2);
x[j + k + p] = mul(dec(u, v), opt == 1 ? 1 : inv2);
}
}
inline void Out() {
this -> FWT(-1);
Rep (i, m)
printf ("%d%c", x[i], i == m - 1 ? '\n' : ' ');
this -> FWT(1);
}
};
struct Info {
Poly a, b, c, d;
inline Info friend operator * (const Info &lhs, const Info &rhs) {
return (Info) {
lhs.a * rhs.a,
lhs.a * rhs.b + lhs.b,
rhs.a * lhs.c + rhs.c,
rhs.b * lhs.c + lhs.d + rhs.d};
}
inline void Out() {
puts("-----------");
a.Out(); b.Out(); c.Out(); d.Out();
puts("-----------");
}
};
#define mid ((l + r) >> 1)
#define lson o << 1, l, mid
#define rson o << 1 | 1, mid + 1, r
template<typename T, int maxn>
struct Segment_Tree {
T mulv[maxn];
void build(int o, int l, int r, T *tmp) {
if (l == r) {
mulv[o] = tmp[mid]; return;
}
build(lson, tmp);
build(rson, tmp);
mulv[o] = mulv[o << 1 | 1] * mulv[o << 1];
}
void update(int o, int l, int r, int up, T uv) {
if (l == r) {
mulv[o] = uv; return;
}
up <= mid ? update(lson, up, uv) : update(rson, up, uv);
mulv[o] = mulv[o << 1 | 1] * mulv[o << 1];
}
T query(int o, int l, int r, int ql, int qr) {
if (ql <= l && r <= qr) return mulv[o];
if (qr <= mid) return query(lson, ql, qr);
if (ql > mid) return query(rson, ql, qr);
return query(rson, ql, qr) * query(lson, ql, qr);
}
};
Segment_Tree<Info, N << 2> mat;
Segment_Tree<Poly, N << 2> FL;
#define root 1, 1, n
vector<int> E[N]; int son[N], sz[N], fa[N];
void Dfs_Init(int u) {
sz[u] = 1;
for (int v : E[u]) if (v != fa[u]) {
fa[v] = u, Dfs_Init(v);
sz[u] += sz[v]; if (sz[v] > sz[son[u]]) son[u] = v;
}
}
int top[N], dfn[N], id[N], enl[N];
void Dfs_Part(int u) {
static int clk = 0;
id[dfn[u] = ++ clk] = enl[u] = u;
top[u] = son[fa[u]] == u ? top[fa[u]] : u;
if (son[u]) Dfs_Part(son[u]), enl[u] = enl[son[u]];
for (int v : E[u])
if (v != son[u] && v != fa[u]) Dfs_Part(v);
}
Poly F[N], G[N], Gl[N], Fl[N], base[N];
int Beg[N], End[N], fid[N], tot = 0;
void Dp(int u) {
F[u] = base[v[u]];
G[u].clear();
for (int v : E[u])
if (v != fa[u] && v != son[u]) {
Dp(v);
F[u] = F[u] * F[v];
G[u] = G[u] + G[v];
}
Gl[u] = G[u]; Fl[u] = F[u];
if (son[u]) {
Dp(son[u]);
F[u] = F[u] * F[son[u]];
G[u] = G[u] + G[son[u]];
}
G[u] = G[u] + F[u]; F[u] = F[u] + 1;
for (int v : E[u]) if (v != son[u] && v != fa[u])
if (!fid[v]) {
End[u] = fid[v] = ++ tot;
if (!Beg[u]) Beg[u] = fid[v];
}
}
void ask(int o) {
Info cur = mat.query(root, dfn[o], dfn[enl[o]]);
F[o] = (Fl[enl[o]] + 1) * cur.a + cur.c;
G[o] = (Fl[enl[o]] + 1) * cur.b + base[v[enl[o]]] + cur.d;
}
void get_mat(int o) {
Fl[o] = Beg[o] ? FL.query(root, Beg[o], End[o]) * base[v[o]] : base[v[o]];
mat.update(root, dfn[o], son[o] ? (Info) {Fl[o], Fl[o], 1, Gl[o]} : (Info) {1, 0, 0, 0});
}
Info I[N]; Poly P[N];
int main () {
File();
n = read(); m = read();
For (i, 1, n) v[i] = read();
For (i, 1, n - 1) {
int u = read(), v = read();
E[u].push_back(v); E[v].push_back(u);
}
Rep (i, m)
base[i].x[i] = 1, base[i].FWT(1);
Dfs_Init(1); Dfs_Part(1); Dp(1);
For (u, 1, n) {
I[dfn[u]] = son[u] ? (Info) {Fl[u], Fl[u], 1, Gl[u]} : (Info) {1, 0, 0, 0};
if (fid[u]) P[fid[u]] = F[u];
}
mat.build(root, I);
FL.build(root, P);
q = read();
while (q --) {
static char str[10];
scanf ("%s", str + 1);
if (str[1] == 'C') {
int x = read(), y = read();
v[x] = y;
for (; x; x = fa[x]) {
if (fa[top[x]])
Gl[fa[top[x]]] = Gl[fa[top[x]]] - G[top[x]];
get_mat(x);
if (x == 1) break;
x = top[x];
ask(x = top[x]);
if (fid[x]) FL.update(root, fid[x], F[x]);
Gl[fa[x]] = Gl[fa[x]] + G[x];
}
} else {
ask(1); Poly ans = G[1]; ans.FWT(-1);
printf ("%d\n", ans.x[read()]);
}
}
return 0;
}
「SDOI2017」天才黑客
题意
这道题题意看了我好久。。。
给你一个 \(n\) 个点 \(m\) 条边的有向图,同时给你一个 \(k\) 个节点的字典树。
对于每条边有两个属性,一个是它的边权 \(c_i\) 另外一个是这条边会对应到字典树上一个节点 \(d_i\) 。
然后你从 \(1\) 开始走,一开始手上有个字符串 \(S\) 为空串,每次走一条边 \(i\) 需要花费的代价是 \(c_i\) 加上 \(d_i\) 对应的字符串与 \(S\) 的 \(LCP\) 长度,然后 \(S\) 变成 \(d_i\) 对应的字符串。
问从 \(1\) 号店开始到 \(2 \sim n\) 所有点的最短路的长度。
数据范围
对于 \(100\%\) 的数据,\(T \leq 10\),\(2 \leq n \leq 50000\),\(1 \leq m \leq 50000\),\(1 \leq k \leq 20000\),保证满足 \(n > 5000\) 或 \(m > 5000\) 的数据不超过 \(2\) 组。
题解
显然暴力考虑的话,我们肯定要记过来的前一条边是什么,那么就是 \(\mathcal O(m^2)\) 的,不够优秀。
发现从点到点时的代价是不确定的,而从边到边的代价是一定的,所以将边转化为点,点权 \(v_i\) 为原图中的边权 \(c_i\) ,然后以 \(1\) 为起点的边距离 \(dis_i = v_i\) 然后跑完最短路后的每个点 \(x\) 的距离,其实就是所有指向 \(x\) 的边的 \(\min_{b_i = x} {dis_i}\) 。
接下来我们只需要考虑考虑如何建边,新图中点 \(x\) 到点 \(y\) 的举例其实就是 \(d_x\) 与 \(d_y\) 在字典树上 \(lca\) 的深度。
那对原图中每个点考虑它相邻的所有边可以一起考虑建边,把这些边按 \(d_i\) 在字典树上的 \(dfs\) 序从小到大排序。
设 \(len_x = lcp(d_x, d_{x + 1})\) 那么有 \(\displaystyle lcp(d_x, d_y) = \min_{i = x}^{y - 1} len_i\) 。这个可以考虑这些节点在字典树上的虚树,两个节点对应的 \(lca\) 就是被夹在其中的相邻点对最浅的那个 \(lca\) 。
我们就可以考虑枚举分界点 \(x\) ,对于所有标号 \(\le x\) 的点与所有标号 \(\ge x\) 的点的距离不会超过 \(len\) ,那么我们建前缀和后缀辅助点就行了。
但是注意入边和出边不能同时连一个前缀或者后缀,不然会直接“短路”。我们可以考虑搞两个前缀和后缀,一个入边连前缀出边连后缀,另外一个出边连前缀入边连后缀。
为什么要这样呢?因为入边和出边的 \(dfs\) 序的大小关系有两种,要分开讨论。
说的好像有点玄乎,挂张图。如下是样例关于点 \(2\) 建出来的图:
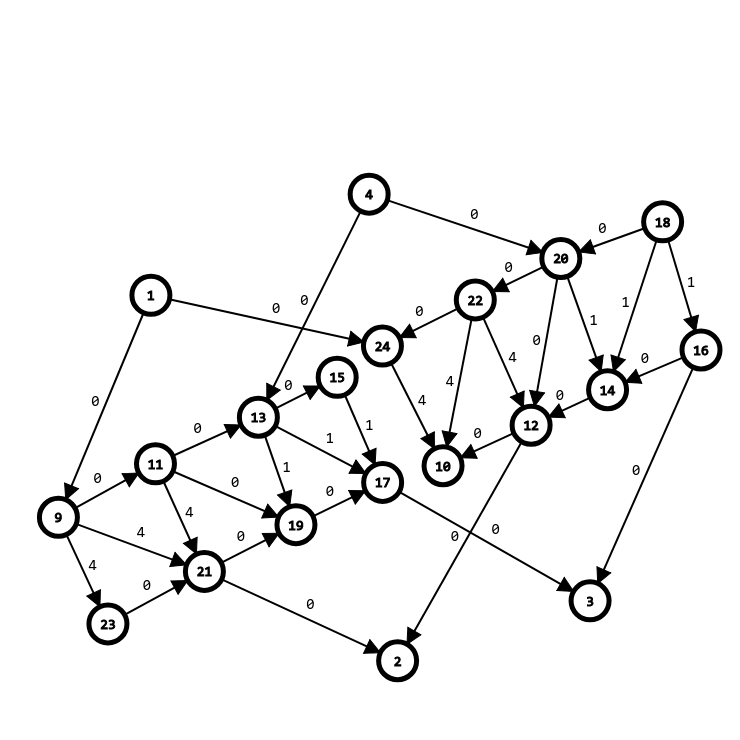
点数和边数都是 \(\mathcal O(m)\) 的,最后跑一次 \(Dijkstra\) 是 \(O(m \log m)\) 的。
总结
最短路的题一般都是考虑重构图,降低边数/点数。
如果是取 \(\min_{i = l}^{r} a_i\) 用双层图跑最短路,如果是 \(\sum_{i = l}^{r} a_i\) 就差分跑最短路。
代码
#include <bits/stdc++.h>
#define For(i, l, r) for (register int i = (l), i##end = (int)(r); i <= i##end; ++i)
#define Fordown(i, r, l) for (register int i = (r), i##end = (int)(l); i >= i##end; --i)
#define Rep(i, r) for (register int i = (0), i##end = (int)(r); i < i##end; ++i)
#define Set(a, v) memset(a, v, sizeof(a))
#define Cpy(a, b) memcpy(a, b, sizeof(a))
#define debug(x) cout << #x << ": " << (x) << endl
#define pb push_back
using namespace std;
template<typename T> inline bool chkmin(T &a, T b) { return b < a ? a = b, 1 : 0; }
template<typename T> inline bool chkmax(T &a, T b) { return b > a ? a = b, 1 : 0; }
inline int read() {
int x(0), sgn(1); char ch(getchar());
for (; !isdigit(ch); ch = getchar()) if (ch == '-') sgn = -1;
for (; isdigit(ch); ch = getchar()) x = (x * 10) + (ch ^ 48);
return x * sgn;
}
void File() {
#ifdef zjp_shadow
freopen ("2270.in", "r", stdin);
freopen ("2270.out", "w", stdout);
#endif
}
const int N = 1e6 + 1e3, M = N << 2;
int n, m, k, val[N], id[N], tot;
vector<int> In[N], Out[N], ch[N];
int Head[N], Next[M], to[M], weight[M], e;
inline void add_edge(int u, int v, int w, bool rev = false) {
if (rev) swap(u, v);
to[++ e] = v; Next[e] = Head[u]; Head[u] = e; weight[e] = w;
}
int clk, dfn[N], anc[N][20], Log2[N], dep[N];
void Dfs_Init(int u) {
dfn[u] = ++ clk;
for (int v : ch[u])
dep[v] = dep[u] + 1, Dfs_Init(v), anc[v][0] = u;
}
inline int Lca(int x, int y) {
if (dep[x] < dep[y]) swap(x, y);
int gap = dep[x] - dep[y];
Fordown (i, Log2[gap], 0)
if (gap >> i & 1) x = anc[x][i];
if (x == y) return x;
Fordown (i, Log2[dep[x]], 0)
if (anc[x][i] != anc[y][i]) x = anc[x][i], y = anc[y][i];
return anc[x][0];
}
void Rebuild() {
static int pre[N][2], suf[N][2];
For (i, 1, n) {
struct Node { int type, num, pos; };
vector<Node> V;
for (int x : In[i]) V.push_back({0, x, id[x]});
for (int x : Out[i]) V.push_back({1, x, id[x]});
sort(V.begin(), V.end(), [&](Node a, Node b) { return dfn[a.pos] < dfn[b.pos]; });
Rep (i, V.size()) Rep (id, 2) {
pre[i][id] = ++ tot;
if (V[i].type == id)
add_edge(V[i].num, pre[i][id], 0, V[i].type);
if (i) add_edge(pre[i - 1][id], pre[i][id], 0, id);
}
Fordown (i, V.size() - 1, 0) Rep (id, 2) {
suf[i][id] = ++ tot;
if (V[i].type == (id ^ 1))
add_edge(V[i].num, suf[i][id], 0, V[i].type);
if (i < int(V.size()) - 1)
add_edge(suf[i][id], suf[i + 1][id], 0, id);
}
Rep (i, V.size()) Rep (id, 2)
add_edge(pre[i][id], suf[i][id], dep[V[i].pos], id);
Rep (i, V.size() - 1) {
int dis = dep[Lca(V[i].pos, V[i + 1].pos)];
Rep (id, 2)
add_edge(pre[i][id], suf[i + 1][id], dis, id);
}
}
}
int dis[N]; bool vis[N];
void Dijkstra() {
priority_queue<pair<int, int>> P;
Set(dis, 0x7f); Set(vis, false);
for (int v : Out[1])
P.emplace(- (dis[v] = val[v]), v);
while (!P.empty()) {
int u = P.top().second; P.pop();
if (vis[u]) continue; vis[u] = true;
for (int i = Head[u], v = to[i]; i; v = to[i = Next[i]])
if (chkmin(dis[v], dis[u] + weight[i] + val[v]))
P.emplace(- dis[v], v);
}
}
int main () {
File();
int cases = read();
while (cases --) {
n = read(); tot = m = read(); k = read();
Set(val, 0); Set(Head, 0); e = clk = 0;
For (i, 1, n)
In[i].clear(), Out[i].clear();
For (i, 1, k)
ch[i].clear();
For (i, 1, m) {
Out[read()].pb(i);
In[read()].pb(i);
val[i] = read(), id[i] = read();
}
For (i, 1, k - 1) {
int u = read(), v = read(); read(); ch[u].pb(v);
}
Dfs_Init(1);
For (i, 2, k)
Log2[i] = Log2[i >> 1] + 1;
For (j, 1, Log2[k]) For (i, 1, k)
anc[i][j] = anc[anc[i][j - 1]][j - 1];
Rebuild();
Dijkstra();
For (i, 2, n) {
int ans = 0x7f7f7f7f;
for (int v : In[i])
chkmin(ans, dis[v]);
printf ("%d\n", ans);
}
}
return 0;
}
「SDOI2017」遗忘的集合
题意
给你一个长度为 \(n\) 的数组 \(f(i)\) ,你需要构造一个集合,满足对于所有 \(i\) 能被集合中元素凑出来的方案(只考虑出现次数,不考虑顺序)对于 \(p\) 取模为 \(f(i)\) ( \(p\) 为质数)。
然后解要字典序尽量小。
数据范围
对于 \(100\%\) 的数据,有 \(1 \leq n < 2^{18}\),\(10^6 \leq p < 2^{30}\),\(\forall i, 0 \leq f(i)< p\) 。
题解
对于计数类背包我们通常考虑生成函数,令 \(a_i \in \{0, 1\}\) 表示 \(i\) 是否出现在集合中,那么 \(f\) 对应的生成函数就是:
\]
现在就变成了构造一组 \(a_i\) 满足 \(F(x)\) 。
两边取对数那么有:
\]
如果做过各种背包套路题的就知道:
\]
这个证明可以看 zsy 大佬的博客 。
考虑代入前面的式子,就有
\]
令 \(T = ij\) 交换和式,那么就有
\]
那么我们就只要求出 \(\ln F(x)\) ,然后就可以得到 \(\sum_{d | T}a_d \times \frac dT\) 。
也就是 \(ia_i = \sum_{k | i} k c_k\) ,其中 \(c_k\) 为给定的系数。
可以莫比乌斯反演,但是没有必要。我们从前往后枚举每个 \(d\) 我们把每个 \(d\) 的倍数 \(T\) 减掉当前的值就行了。
多项式求 \(\ln\) 复杂度在于多项式除法,用主定理证的 \(\mathcal O(n \log n)\) 实际上常数大到飞起(还有个 \(MTT\) 。。)
总结
牢记普通生成函数的形式。
\]
以及一个经典多项式对数的形式。
\]
代码
傻吊出题人出个求 \(\ln\) 的题还要任意模数 \(FFT\) 。。
注意用 \(MTT\) 的话要预处理单位根来卡精度。
#include <bits/stdc++.h>
#define For(i, l, r) for (register int i = (l), i##end = (int)(r); i <= i##end; ++i)
#define Fordown(i, r, l) for (register int i = (r), i##end = (int)(l); i >= i##end; --i)
#define Rep(i, r) for (register int i = (0), i##end = (int)(r); i < i##end; ++i)
#define Set(a, v) memset(a, v, sizeof(a))
#define Cpy(a, b) memcpy(a, b, sizeof(a))
#define debug(x) cout << #x << ": " << (x) << endl
using namespace std;
template<typename T> inline bool chkmin(T &a, T b) { return b < a ? a = b, 1 : 0; }
template<typename T> inline bool chkmax(T &a, T b) { return b > a ? a = b, 1 : 0; }
inline int read() {
int x(0), sgn(1); char ch(getchar());
for (; !isdigit(ch); ch = getchar()) if (ch == '-') sgn = -1;
for (; isdigit(ch); ch = getchar()) x = (x * 10) + (ch ^ 48);
return x * sgn;
}
void File() {
#ifdef zjp_shadow
freopen ("2271.in", "r", stdin);
freopen ("2271.out", "w", stdout);
#endif
}
const double Pi = acos(-1.0);
struct Complex {
double re, im;
};
inline Complex operator + (const Complex &lhs, const Complex &rhs) {
return (Complex) {lhs.re + rhs.re, lhs.im + rhs.im};
}
inline Complex operator - (const Complex &lhs, const Complex &rhs) {
return (Complex) {lhs.re - rhs.re, lhs.im - rhs.im};
}
inline Complex operator * (const Complex &lhs, const Complex &rhs) {
return (Complex){lhs.re * rhs.re - lhs.im * rhs.im, lhs.re * rhs.im + lhs.im * rhs.re};
}
const int Maxn = (1 << 22) + 5;
int len, rev[Maxn];
Complex W[Maxn];
void FFT(Complex *P, int opt) {
For (i, 0, len - 1) if (i < rev[i]) swap(P[i], P[rev[i]]);
for (int i = 2, p = 1; i <= len; p = i, i <<= 1) {
Rep (k, p)
W[k] = (Complex){cos(2 * Pi * k / i), opt * sin(2 * Pi * k / i)};
for (int j = 0; j < len; j += i) {
For (k, 0, p - 1) {
Complex u = P[j + k], v = P[j + k + p] * W[k];
P[j + k] = u + v; P[j + k + p] = u - v;
}
}
}
if (!~opt) For (i, 0, len - 1) P[i].re /= len;
}
void FFT_Init(int n) {
int cnt = 0; for (len = 1; len <= n; len <<= 1) ++ cnt;
For (i, 0, len - 1) rev[i] = (rev[i >> 1] >> 1) | ((i & 1) << (cnt - 1));
}
void Trans(int *a, Complex *P) {
Rep (i, len)
P[i] = (Complex){(double)a[i], 0};
FFT(P, 1);
}
const int Pow = (1 << 15) - 1;
int F[Maxn], G[Maxn], CoefF[Maxn], CoefG[Maxn], res[Maxn], Mod;
Complex A[Maxn], B[Maxn], C[Maxn], D[Maxn], sum[Maxn];
inline int Get_Mod(double x) {
return (int)((x - floor(x / Mod) * Mod) + .5);
}
void Mult(Complex *a, Complex *b, int base, int opt = 1) {
Rep (i, len) sum[i] = sum[i] + a[i] * b[i];
if (opt) {
FFT(sum, -1);
Rep (i, len) {
res[i] = (res[i] + 1ll * base * Get_Mod(sum[i].re)) % Mod;
sum[i] = (Complex){0, 0};
}
}
}
void Mult(int *f, int *g, int *ans, int len) {
FFT_Init(len);
Rep (i, len << 1) res[i] = 0;
Rep (i, len)
CoefF[i] = f[i] & Pow, F[i] = f[i] >> 15;
Rep (i, len)
CoefG[i] = g[i] & Pow, G[i] = g[i] >> 15;
Trans(CoefF, A); Trans(F, B);
Trans(CoefG, C); Trans(G, D);
Mult(A, C, 1);
Mult(B, D, 1 << 30);
Mult(A, D, 1 << 15, 0);
Mult(B, C, 1 << 15);
Rep (i, len << 1) ans[i] = res[i];
}
inline int fpm(int x, int power) {
int res = 1;
for (; power; power >>= 1, x = 1ll * x * x % Mod)
if (power & 1) res = 1ll * res * x % Mod;
return res;
}
const int N = 1e6 + 1e3;
int tmp[N];
void Get_Inv(int *a, int *b, int len) {
if (len == 1) {
b[0] = fpm(a[0], Mod - 2); return;
}
Get_Inv(a, b, len >> 1);
Mult(a, b, tmp, len);
Rep (i, len) tmp[i] = Mod - tmp[i]; tmp[0] += 2;
Mult(tmp, b, b, len);
}
int der[N], inv[N];
void Get_Ln(int *a, int *b, int len) {
For (i, 1, len - 1)
der[i - 1] = 1ll * i * a[i] % Mod;
Get_Inv(a, inv, len);
Mult(der, inv, b, len);
Fordown (i, len - 1, 0)
b[i] = 1ll * b[i - 1] * fpm(i, Mod - 2) % Mod;
}
int x[N], f[N], ans[N];
int main () {
File();
int n = read(); Mod = read();
f[0] = 1; For (i, 1, n) f[i] = read();
int len = 1; while (len <= n) len <<= 1;
Get_Ln(f, f, len);
For (i, 1, n) f[i] = 1ll * f[i] * i % Mod;
For (i, 1, n)
for (int j = i << 1; j <= n; j += i)
(f[j] += Mod - f[i]) %= Mod;
vector<int> ans;
For (i, 1, n)
if (f[i]) ans.push_back(i);
printf ("%d\n", int(ans.size()));
Rep (i, ans.size())
printf ("%d%c", ans[i], i == iend - 1 ? '\n' : ' ');
return 0;
}
「SDOI2017」文本校正
题意
给你字符串 \(S\) 和 \(T\) ,问你是否能把 \(T\) 分成三段重组后变成 \(S\) ,如果可行则给出方案。
数据范围
\(T \le 30, 3 \leq n \leq 1000000\),\(1 \leq S_i. T_i \leq m \leq 1000000\)
题解
可以考虑把 \(T\) 划分成 \(3\) 段为 \(ABC\) 考虑重组后的形式,共有 \(3! = 6\) 种方式。
- \(ABC:\) 直接暴力判断即可。
- \(CBA:\) 不会做。
- \(ACB:\) 枚举 \(AC\) 分界点,然后???
- \(BAC:\) 和上面是一样的。
- \(CAB:\) 不知道
- \(BCA:\) 和上面一种一样的。
省选没退役就来填坑。
SDOI2017 Round2 详细题解的更多相关文章
- SDOI2017 Round1 简要题解
我们 TM 怎么又要上文化课..我 哔哔哔哔哔哔 「SDOI2017」数字表格 题意 有 \(T\) 组数据,求 \[ \prod_{i = 1}^{n} \prod_{j = 1}^{m} fib[ ...
- noip2013Day2T3-华容道【一个蒟蒻的详细题解】
描述 小 B 最近迷上了华容道,可是他总是要花很长的时间才能完成一次.于是,他想到用编程来完成华容道:给定一种局面,华容道是否根本就无法完成,如果能完成,最少需要多少时间. 小 B 玩的华容道与经典的 ...
- DZY Loves Math 系列详细题解
BZOJ 3309: DZY Loves Math I 题意 \(f(n)\) 为 \(n\) 幂指数的最大值. \[ \sum_{i = 1}^{a} \sum_{j = 1}^{b} f(\gcd ...
- BZOJ 4540 [Hnoi2016]序列 | 莫队 详细题解
传送门 BZOJ 4540 题解 --怎么说呢--本来想写线段树+矩阵乘法的-- --但是嘛--yali的机房太热了--困--写不出来-- 于是弃疗,写起了莫队.(但是我连莫队都想不出来!) 首先用单 ...
- Leetcode:Repeated DNA Sequences详细题解
题目 All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: " ...
- POJ 3468 A Simple Problem with Integers(详细题解) 线段树
这是个线段树题目,做之前必须要有些线段树基础才行不然你是很难理解的. 此题的难点就是在于你加的数要怎么加,加入你一直加到叶子节点的话,复杂度势必会很高的 具体思路 在增加时,如果要加的区间正好覆盖一个 ...
- HDU 2553 N皇后问题(详细题解)
这是一道深搜题目!问题的关键是在剪枝. 下面我们对问题进行分析: 1.一行只能放一个皇后,所以我们一旦确定此处可以放皇后,那么该行就只能放一个皇后,下面的就不要再搜了. 2.每一列只能放一个皇后,所以 ...
- Leetcode:Largest Number详细题解
题目 Given a list of non negative integers, arrange them such that they form the largest number. For e ...
- PAT1074 Reversing Linked List (25)详细题解
02-1. Reversing Linked List (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue ...
随机推荐
- iOS----------viewcontroller中的dealloc方法不调用
ios的viewcontroller生命周期是 init -> loadView -> viewDidLoad -> viewWillAppear -> viewDidAppe ...
- 牛客网:Java重命名文件
项目介绍 不管是C/C++还是JAVA,都可能生成一些持久性数据,我们可以将数据存储在文件或数据库中,此项目主要训练学习Java对本地磁盘的文件重命名,例如C:\nowcoder.txt重命名C:\n ...
- Spark之Yarn提交模式
一.Client模式 提交命令: ./spark-submit --master yarn --class org.apache.examples.SparkPi ../lib/spark-examp ...
- httpservlet里单纯分页
@Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletExcep ...
- Review: Basic Knowledge about SQL
非原创,转自Github:enochtangg/quick-SQL-cheatsheet SQL 语句用法的速查表. 内容 查找数据的查询 修改数据的查询 聚合查询 连接查询 视图查询 修改表的查询 ...
- 数字信号处理专题(1)——DDS函数发生器环路Demo
一.前言 会FPGA硬件描述语言.设计思想和接口协议,掌握些基本的算法是非常重要的,因此开设本专题探讨些基于AD DA数字信号处理系统的一些简单算法,在数字通信 信号分析与检测等领域都会或多或少有应用 ...
- mas录屏,带系统声音和麦克风声音
自带的QuickTime + Soundflower 可完美解决,同时录系统的声音和mic声音,也可以只录系统声音. 安装Soundflower 在应用程序 -> 实用工具,里面找到“音频 MI ...
- 个人对JS原型链的一些理解(prototype、__proto__)
前言 在我一开始学习java web的时候,对JS就一直抱着一种只是简单用用的心态,于是并没有一步一步地去学习,当时认为用法与java类似,但是在实际web项目中使用时却比较麻烦,便直接粗略了解后开始 ...
- SQL数据库一些系统语法含义
昨天在数据库中建立数据表的时候要求显示的添加一些系统语法规则,对于这些设置不知道都是什么含义,这次记录下来供以后学习. (1)SET ANSI_NULLS ON语句 T-SQL支持在与空值进行比较时, ...
- HTML5 canvas clearRect() 方法
浏览器支持 Internet Explorer 9.Firefox.Opera.Chrome 以及 Safari 支持 clearRect() 方法. 注释:Internet Explorer 8 或 ...