[Machine Learning] 浅谈LR算法的Cost Function
了解LR的同学们都知道,LR采用了最小化交叉熵或者最大化似然估计函数来作为Cost Function,那有个很有意思的问题来了,为什么我们不用更加简单熟悉的最小化平方误差函数(MSE)呢?
我个人理解主要有三个原因:
- MSE的假设是高斯分布,交叉熵的假设是伯努利分布,而逻辑回归采用的就是伯努利分布;
- MSE会导致代价函数$J(\theta)$非凸,这会存在很多局部最优解,而我们更想要代价函数是凸函数;
- MSE相对于交叉熵而言会加重梯度弥散。
这里着重讨论下后边两条原因。
代价函数为什么要为凸函数?
假设对于LR我们依旧采用线性回归的MSE作为代价函数:
$$J(\theta)=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2$$
其中
$$h_{\theta}(x)=\frac{1}{1+e^{-\theta^T x}}$$
这样代价函数$J(\theta)$关于算法参数$\theta$会是非凸函数,存在多个局部解,我们可以形式化的表示为下图:
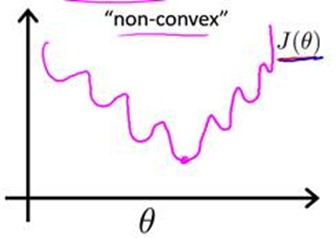
如上图所示,$J(\theta)$非常复杂,这并不是我们想要的。我们想要的代价函数是关于$\theta$的凸函数,这样我们就可以轻松地根据梯度下降法等最优化手段去轻松地找到全局最优解了。
所以,我们理想的代价函数应该是凸函数,如下图所示:

因此,MSE对于LR并不是一个理想的代价函数。那么为什么交叉熵可以呢?我们先给出交叉熵的公式形式:
$$J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}\log{\hat{y}^{(i)}}+(1-y^{(i)})\log{(1-\hat{y}^{(i)})}]$$
即令每个样本属于其真实标记的概率越大越好,可以证明$J(\theta)$是关于$\theta$的高阶连续可导的凸函数,因此可以根据凸优化理论求的最优解。
note:最小化交叉熵也可以理解为最大化似然估计,即利用已知样本分布,找到最有可能导致这种分布的参数值,即最优解$\theta^{*}$。
为什么MSE会更易导致梯度弥散?
我们简单求解下MSE和交叉熵对应$w$的梯度,首先是MSE:
对于单样本的Loss Function为:
$$L_{MSE}=\frac{1}{2}(y-\hat{y})^{2}$$
$L_{MSE}$对于$w$的梯度为:
$$\frac{\partial L_{MSE}}{\partial w}=(y-\hat{y})\sigma(w, b)h$$
其中$\sigma(w, b)$为sigmoid函数:
$$\sigma(w, b)=\frac{1}{1+e^{-w^{T}x+b}}$$
而以交叉熵为Loss Function:
$$L_{cross\_entropy}=-(y\log{\hat{y}}+(1-y)\log(1-\hat{y}))$$
则对应的梯度为:
$$\frac{\partial L_{cross\_entropy}}{\partial w}=(\hat{y}-y)h$$
我们对比两者的梯度绝对值可以看出MSE和交叉熵两种损失函数的梯度大小差异:
$$\frac{|\Delta_{MSE}|}{|\Delta_{cross\_entropy}|}=|\sigma^{'}(w, b)| \le 0.25$$
即MSE的梯度是交叉熵梯度的1/4。
note:
- 上式为什么小于0.25可以参考另一篇博文《[Machine Learning] 深度学习中消失的梯度》
- Cost Function和Loss Function的区别
- Cost Function:指基于参数$w$和$b$,在所有训练样本上的总成本;
- Loss Function:指单个训练样本的损失函数。
其实可以从另外一个角度理解为什么交叉熵函数相对MSE不易导致梯度弥散:当训练结果接近真实值时会因为梯度算子极小,使得模型的收敛速度变得非常的缓慢。而由于交叉熵损失函数为对数函数,在接近上边界的时候,其仍然可以保持在高梯度状态,因此模型的收敛速度不会受损失函数的影响。
[Machine Learning] 浅谈LR算法的Cost Function的更多相关文章
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦
Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦 近期活动: 2014年9月3日,第8次西安面试&算法讲座视频 + PPT 的下载地址:http ...
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈 Adaboost 算法
http://blog.csdn.net/haidao2009/article/details/7514787 菜鸟最近开始学习machine learning.发现adaboost 挺有趣,就把自己 ...
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
- 浅谈Tarjan算法
从这里开始 预备知识 两个数组 Tarjan 算法的应用 求割点和割边 求点-双连通分量 求边-双连通分量 求强连通分量 预备知识 设无向图$G_{0} = (V_{0}, E_{0})$,其中$V_ ...
- 浅谈 Tarjan 算法
目录 简述 作用 Tarjan 算法 原理 出场人物 图示 代码实现 例题 例题一 例题二 例题三 例题四 例题五 总结 简述 对于初学 Tarjan 的你来说,肯定和我一开始学 Tarjan 一样无 ...
随机推荐
- C++设计模式视频讲解
设计模式(C++) 视频网址: http://www.qghkt.com/ 设计模式(C++)视频地址: https://ke.qq.com/course/318637?tuin=a508ea62 目 ...
- idea中Springcloud同时运行多个模块、微服务
idea中有个窗口叫做 Run DashBoard 在这里可以管理多个模块的启停,这个面板一般情况下是关闭的打开Run DashBoard面板 在工程的.idea中找到workspace.xml,并找 ...
- shader高级纹理学习总结
最近看了shader的高级纹理 做个总结 复习! shader迟早是要拿下的
- python接口自动化-json数据处理
前言 有些post的请求参数是json格式的,需要导入json模块进行处理,json是一种数据交换格式,独立于编程语言 一般常见的接口返回数据也是json格式的,我们在做判断的时候,往往只需要提取其中 ...
- Redis详解(五)------ redis的五大数据类型实现原理
前面两篇博客,第一篇介绍了五大数据类型的基本用法,第二篇介绍了Redis底层的六种数据结构.在Redis中,并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这些对 ...
- 一键发布部署vs插件[AntDeploy],让net开发者更幸福
一键发布工具(ant deploy tool) 插件下载地址: https://marketplace.visualstudio.com/items?itemName=nainaigu.AntDepl ...
- 15 Django REST Framework 给api添加自定义搜索条件
一.ListModelMixin源码 # 源码 class ListModelMixin(object): """ List a queryset. "&quo ...
- On the structure of submodule of finitely generated module over PID
I was absorbed into this problem for three whole days......
- MySQL工作原理
Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的. mysql原理图各个组件说明: 1. connectors 与其他编程语言中的sql 语句进行交互,如php.java等. 2. M ...
- linux查看目录下各个文件大小的命令
linux查看目录下各个文件大小的命令 由于需要经常查看各个文件的具体大小 ,所以这里记一下. 命令如下: du -h --max-depth=1