[Python]爬取 游民星空网站 每周精选壁纸(1080高清壁纸) 网络爬虫
一、检查
首先进入该网站的https://www.gamersky.com/robots.txt页面
给出提示:

弹出错误页面
注:
- 网络爬虫:自动或人工识别robots.txt,再进行内容爬取
- 约束性:robots协议建议但非约束性,不遵守可能存在法律风险
如果一个网站不设置robots协议,说明所有内容都可以爬取,所以该网站为可爬取内容。
二、实现
源程序如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : HtmlParser.py
# @Author: 赵路仓
# @Date : 2020/2/28
# @Desc : 爬取游民星空网站每周精选壁纸
# @Contact : 398333404@qq.com import requests
from bs4 import BeautifulSoup
import os
import re # 网址
url = "http://so.gamersky.com/all/news?s=%u58c1%u7eb8%u7cbe%u9009&type=hot&sort=des&p="
# 请求头
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
} # 检查是否存在filePath路径的文件夹,若无则创建,若有则不执行
def createFile(filePath):
if os.path.exists(filePath):
print('%s:存在' % filePath)
else:
try:
os.mkdir(filePath)
print('新建文件夹:%s' % filePath)
except:
print("创建文件夹失败!") # 获取每周壁纸的主题超链接
def href(url):
try:
path = "D:/img"
createFile(path)
# 清空html_href.txt的内容
f_init = open(path + '/html_href.txt', 'w', encoding='utf-8')
f_init.write("")
f_init.close()
f = open(path + '/html_href.txt', 'a+', encoding='utf-8')
for i in range(1, 12):
r = requests.get(url + str(i))
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'html.parser')
hrefs = soup.find_all("div", {"class": "link"})
for h in hrefs:
print(h.string)
# 写入txt文件
f.write(h.string + '\n')
f.close()
print("爬取成功!")
except:
print("爬取壁纸主题失败!") # 读取html_href(主题地址超链接)并写入img_hef(图片地址)
def read():
try:
path = "D:/img"
f_read = open(path + '/html_href.txt', 'r+', encoding='utf-8')
# 清空img_href.txt的内容
f_init = open(path + '/img_href.txt', 'w', encoding='utf-8')
f_init.write("")
f_init.close()
# 读取txt文件内容
f_writer = open(path + '/img_href.txt', 'a+', encoding='utf-8')
number=1
for line in f_read:
try:
line = line.rstrip("\n")
r = requests.get(line, headers=head, timeout=3)
soup = BeautifulSoup(r.text, 'html.parser')
imgs = soup.find_all("p", {"align": "center"})
try:
for i in imgs:
print(re.sub(r'http.*shtml.', '', i.find("a").attrs['href'])+" 当前第"+str(number)+"张图片!")
f_writer.write(re.sub(r'http.*shtml.', '', i.find("a").attrs['href']) + '\n')
number+=1
except:
print("图片地址出错!")
except:
print("超链接出错!")
f_read.close()
f_writer.close()
print("共有"+str(number)+"个图片地址!")
except:
print("读取html_href并写入img_href过程失败!!") def save_img():
path = "D:/img/"
img_path="D:/img/images/"
createFile(path)
f_read = open(path + 'img_href.txt', 'r+', encoding='utf-8')
number = 1
for line in f_read:
try:
line = line.rstrip("\n")
# 根据个数顺序重命名名称
f_write = open(img_path + str(number) + '.jpg', 'wb')
r = requests.get(line)
# 打印状态码
print(r.status_code)
# 如果图片地址有效则下载图片状态码200,否则跳过。
if r.status_code == 200:
f_write.write(r.content)
# 若保存成功,则命名顺序+1
number += 1
print("当前保存第" + str(number) + "张图片。")
f_write.close()
except:
print("下载图片出错!!")
f_read.close() if __name__ == "__main__":
href(url)
read()
save_img()
# 测试下载图片↓
# save_img("https://img1.gamersky.com/image2019/04/20190427_ljt_red_220_3/gamersky_001origin_001_201942716489B7.jpg","D:/img/1.jpg")
路径无需改动,但有需求可自行更改。
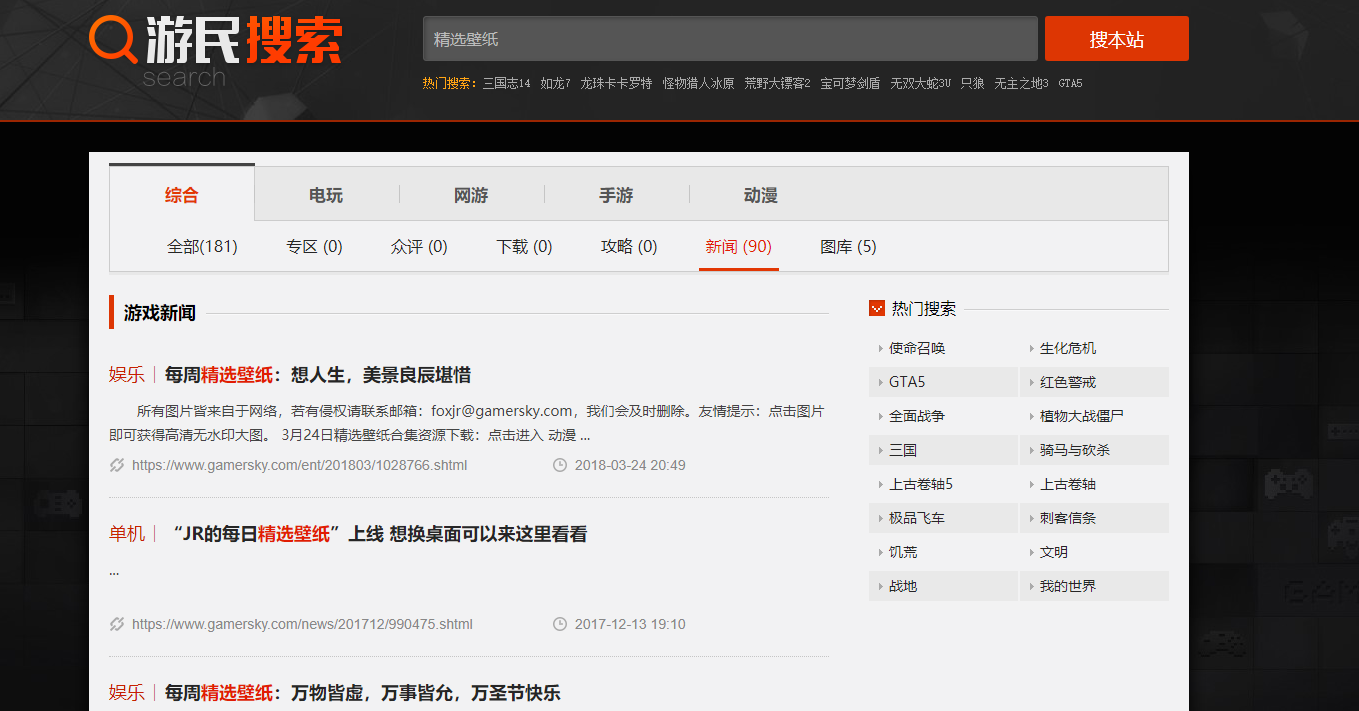
在爬取过程中,在游民星空网站的壁纸栏是通过js跳转,页面不翻页的模式,但后来可以通过搜索——壁纸到达如下界面:
三、实现步骤
- 然后通过 href(url) 函数爬取每周的大标题写入 html_href.txt 中
- 通过 read() 读取写入的标题超链接,将爬取的图片地址写入 img_href.txt 中。
- 最后一步,通过 save_img() 函数读取图片地址,下载壁纸图片。
四、效果
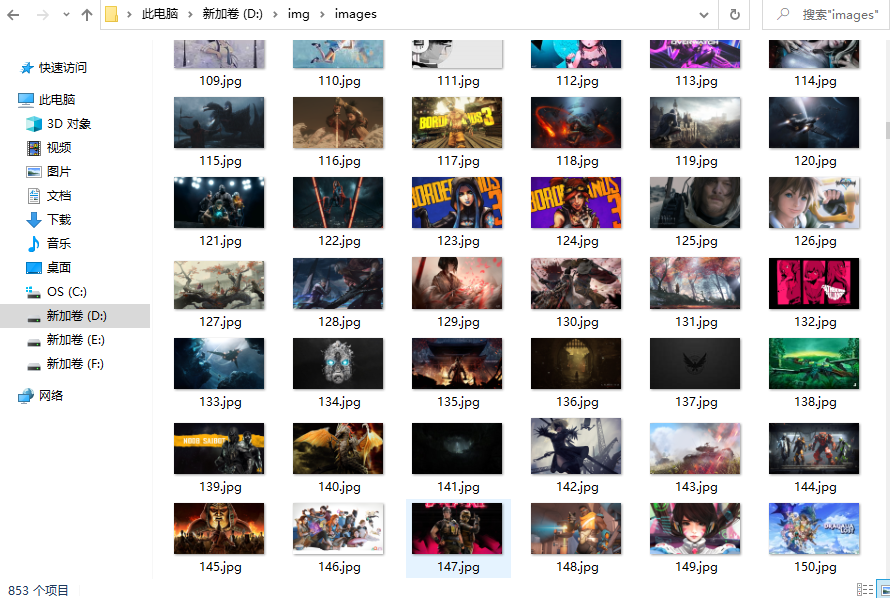
至此完成!!
[Python]爬取 游民星空网站 每周精选壁纸(1080高清壁纸) 网络爬虫的更多相关文章
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取中国天气网站数据并对其进行数据可视化
网址:http://www.weather.com.cn/textFC/hb.shtml 解析:BeautifulSoup4 爬取所有城市的最低天气 对爬取的数据进行可视化处理 按温度对城市进行排 ...
- Python爬取十四万条书籍信息告诉你哪本网络小说更好看
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TM0831 PS:如有需要Python学习资料的小伙伴可以加点击 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- 利用Python爬取电影网站
#!/usr/bin/env python #coding = utf-8 ''' 本爬虫是用来爬取6V电影网站上的电影资源的一个小脚本程序,爬取到的电影链接会通过网页的形式显示出来 ''' impo ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- Python 爬取网站资源文件
爬虫原理: 以下来自知乎解释 首先你要明白爬虫怎样工作.想象你是一只蜘蛛,现在你被放到了互联“网”上.那么,你需要把所有的网页都看一遍.怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页 ...
随机推荐
- 《ASP.NET Core 高性能系列》关于.NET Core的配置信息的若干事项
1.配置文件的相关闲话 Core自身对于配置文件不是必须品,但由上文分析可知ASP.NET Core默认采用appsettings.json作为配置文件,关于配置信息的优先等级 命令行>环境变量 ...
- 手把手实操教程!使用k3s运行轻量级VM
前 言 k3s作为轻量级的Kubernetes发行版,运行容器是基本功能.VM的管理原本是IaaS平台的基本能力,随着Kubernetes的不断发展,VM也可以纳入其管理体系.结合Container和 ...
- Spacemacs安装
Spacemacs官网 为什么选择Spacemacs Spacemacs是一个已经配好的Emacs和Vim,正如官网所说的The best editor is neither Emacs nor Vi ...
- bzoj 50题纪念
bzoj好难,边看题解边做终于水到了50t,不知道水平提没提高啊TAT
- 2018icpc徐州网络赛-H Ryuji doesn't want to study(线段树)
题意: 有n个数的一个数组a,有两个操作: 1 l r:查询区间[l,r]内$a[l]*(r-l+1)+a[l+1]*(r-l)+a[l+2]*(r-l-1)+\cdots+a[r-1]*2+a[r] ...
- <七>对于之前的一些遗漏的地方的补充
1.线程的状态: 我们可以通过wait,start,notify等关键字来切换线程的状态,但是我们如何知道线程目前是处于哪一种状态呢?使用Thread.getState()来获取,有下面几种常见的状态 ...
- A simple way to monitor SQL server SQL performance.
This is all begins from a mail. ... Dear sir: This is liulei. Thanks for your help about last PM for ...
- Jdk14 都要出了,Jdk9 的新特性还不了解一下?
Java 9 中最大的亮点是 Java 平台模块化的引入,以及模块化 JDK.但是 Java 9 还有很多其他新功能,这篇文字会将重点介绍开发人员特别感兴趣的几种功能. 这篇文章也是 Java 新特性 ...
- Golang调用Dll案例
Golang调用Dll案例 前言 在家办公已经两个多星期了,目前最大的困难就是网络很差.独自一个人用golang开发调用dll的驱动程序.本来就是半桶水的我,还在为等待打开一个页面而磨平了耐心.本想依 ...
- python学习(10)字典学习,写一个三级菜单程序
学习了字典的应用.按老师的要求写一个三级菜单程序. 三级菜单程序需求如下: 1.深圳市的区--街道--社区---小区4级 2.建立一个字典,把各级区域都装进字典里 3.用户可以从1级进入2级再进入3级 ...