<scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目
dos窗口输入:
scrapy startproject images360
cd images360
2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义)
import scrapy class Images360Item(scrapy.Item):
# define the fields for your item here like:
#图片ID
image_id = scrapy.Field()
#链接
url = scrapy.Field()
#标题
title = scrapy.Field()
#缩略图
thumb = scrapy.Field()
3.创建爬虫文件
dos窗口输入:
scrapy genspider myspider images.so.com
4.编写myspider.py文件(接收响应,处理数据)
# -*- coding: utf-8 -*-
from urllib.parse import urlencode
import scrapy
from images360.items import Images360Item
import json class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['images.so.com']
urls = []
data = {'ch': 'beauty', 'listtype': 'new'}
base_url = 'https://image.so.com/zj?0'
for page in range(1,51):
data['sn'] = page * 30
params = urlencode(data)
url = base_url + params
urls.append(url)
print(urls)
start_urls = urls # ch: beauty
# sn: 120
# listtype: new
# temp: 1 def parse(self, response):
result = json.loads(response.text)
for each in result.get('list'):
item = Images360Item()
item['image_id'] = each.get('imageid')
item['url'] = each.get('qhimg_url')
item['title'] = each.get('group_title')
item['thumb'] = each.get('qhimg_thumb_url')
yield item
5.编写pipelines.py(存储数据)
import pymysql.cursors class Images360Pipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host='localhost',
user='root',
password='',
database='quotes',
charset='utf8',
)
self.cursor = self.connect.cursor() def process_item(self, item, spider):
item = dict(item)
sql = 'insert into images360(image_id,url,title,thumb) values(%s,%s,%s,%s)'
self.cursor.execute(sql, (item['image_id'], item['url'], item['title'],item['thumb']))
self.connect.commit()
return item def close_spider(self, spider):
self.cursor.close()
self.connect.close()
6.编写settings.py(设置headers,pipelines等)
robox协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
headers
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
pipelines
ITEM_PIPELINES = {
'quote.pipelines.Images360Pipeline': 300,
}
7.运行爬虫
dos窗口输入:
scrapy crawl myspider
运行结果
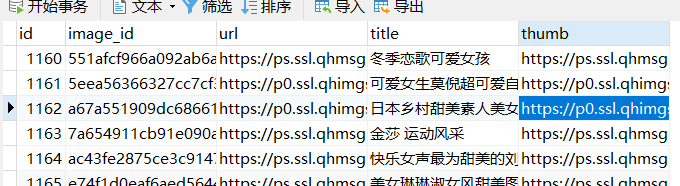
<scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)的更多相关文章
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- Scrapy框架学习(四)爬取360摄影美图
我们要爬取的网站为http://image.so.com/z?ch=photography,打开开发者工具,页面往下拉,观察到出现了如图所示Ajax请求, 其中list就是图片的详细信息,接着观察到每 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- <scrapy爬虫>爬取quotes.toscrape.com
1.创建scrapy项目 dos窗口输入: scrapy startproject quote cd quote 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) import ...
- scrapy爬虫爬取小姐姐图片(不羞涩)
这个爬虫主要学习scrapy的item Pipeline 是时候搬出这张图了: 当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释 我们可以自定义Item Pip ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- <scrapy爬虫>爬取腾讯社招信息
1.创建scrapy项目 dos窗口输入: scrapy startproject tencent cd tencent 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # - ...
随机推荐
- 6361. 【NOIP2019模拟2019.9.18】鲳数
题目 题目大意 给你一个区间\([l,r]\),求这个区间内每个整数的十进制上从高位到低位的逆序对个数之和. 思考历程 一开始就知道这是个数位DP-- 结果一直都没有调出来,心态崩了-- 正解 先讲讲 ...
- 单源最短路径问题1 (Bellman-Ford算法)
/*单源最短路径问题1 (Bellman-Ford算法)样例: 5 7 0 1 3 0 3 7 1 2 4 1 3 2 2 3 5 2 4 6 3 4 4 输出: [0, 3, 7, 5, 9] */ ...
- 2019hdu第二场
10:签到求n!取模 #include <iostream> #include <iterator> #include <algorithm> typedef lo ...
- Elasticsearch集群状态查看命令
_cat $ curl localhost:9200/_cat=^.^=/_cat/allocation/_cat/shards/_cat/shards/{index}/_cat/master/_ca ...
- Java-Class-C:org.springframework.http.HttpHeaders
ylbtech-Java-Class-C:org.springframework.http.HttpHeaders 1.返回顶部 1.1. import org.springframework.htt ...
- Delph i2010
我在习惯Delphi2010 转载 一直留着一个txt文件,不晓得是干嘛的(忘记了),偶然打开一看.乖乖~ 2010 还可以这样玩. 1.循环有了新用法 procedure TForm1.Butt ...
- jQuery 基本使用
index.html <head><meta http-equiv="Content-Type" content="text/html; charset ...
- 洛谷P3916 图的遍历
题目链接:https://www.luogu.org/problemnew/show/P3916 题目大意 略. 分析 以终为始,逆向思维. 代码如下 #include <bits/stdc++ ...
- 20140421 常量指针与指针常量; const指针; reinterpret_cast ;const_cast作用
1.reinterpret_cast<type_id>(表达式)的作用: type-id 必须是一个指针.引用.算术类型.函数指针或者成员指针.它可以把一个指针转换成一个整数,也可以把一个 ...
- JS与Jquery的事件委托机制
传送:http://www.ituring.com.cn/article/467 概念: 什么是事件委托:通俗的讲,事件就是onclick,onmouseover,onmouseout,等就是事件,委 ...