网络结构解读之inception系列三:BN-Inception(Inception V2)
网络结构解读之inception系列三:BN-Inception(Inception V2)
BN的出现大大解决了训练收敛问题。作者主要围绕归一化的操作做了一系列优化思路的阐述,值得细看。
Batch Normalization: Accelerating Deep Network Training
by Reducing Internal Covariate Shift
深度网络为什么难训练?
因为internal covariate shift
- internal covariate shift:在训练过程中,每层的输入分布因为前层的参数变化而不断变化
- 从不同的角度说明问题internal covariate shift
1.SGD训练多层网络
总损失是 ,当
,当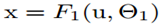 ,损失转换为
,损失转换为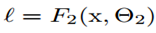
梯度更新是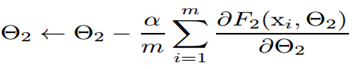
当x的分布固定时候,训练 是容易收敛的。而当x的分布不断变化时候,需要不断调整去修正x分布的变化带来的影响
是容易收敛的。而当x的分布不断变化时候,需要不断调整去修正x分布的变化带来的影响
2.易进入饱和状态
什么是饱和状态?以sigmoid为例,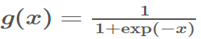 ,当|x|增加,
,当|x|增加,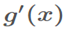 趋向于0,称为饱和状态。(梯度消失,模型将缓慢训练)。这里
趋向于0,称为饱和状态。(梯度消失,模型将缓慢训练)。这里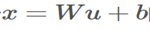 x受W、b和前面层参数的影响,训练期间前面层参数的变化可能会将x的许多维度移动到非线性的饱和状态并收敛减慢。且这个前层的影响随着网络深度的增加而放大。
x受W、b和前面层参数的影响,训练期间前面层参数的变化可能会将x的许多维度移动到非线性的饱和状态并收敛减慢。且这个前层的影响随着网络深度的增加而放大。
- BN之前的做法 :1.较低的学习率,但减慢了收敛速度。2.谨慎的参数初始化。3.ReLU代替sigmoid
如何解决internal covariate shift,BN的思考起源:
whitened(LeCun et al,1998b),对输入进行白化即输入线性变化为具有0均值和单位方差,并去相关。使用白化来进行标准化(normalization),以此来消除internal covariate shift的不良影响由于whitened需要计算协方差矩阵和它的平方根倒数,而且在每次参数更新后需要对整个训练集进行分析,代价昂贵。因此寻求一种可替代的方案,BN。
Batch Normalization
在白化的基础上做简化:
简化1,单独标准化每个标量特征(每个通道)
简单标准化可能改变该层的表达能力,以sigmoid层为例会把输入约束到线性状态。因此我们需要添加新的恒等变换去抵消这个(scale操作)。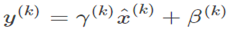
简化2,mini-batch方式进行normalization。计算过程如图:

为了数值稳定, 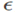 是一个加到方差上的常量。
是一个加到方差上的常量。
Batch Normalization的求导
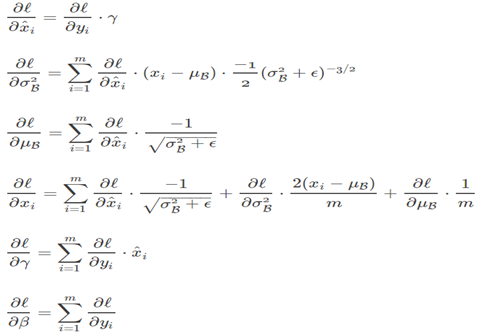
BN的训练和预测
训练时取决于当前batch的输入。
预测需要用总体统计来进行标准化。训练完成后得到均值参数 和方差参数
和方差参数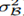 :
:

网络中加入BN
仿射(线性)变换和非线性变换组成用下式表示: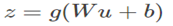
其中g是非线性如sigmoid。当normalization非线性输出时,它的分布形状可能会改变无法消除internal covariate shift。
而线性 更加具有对称性,非稀疏分布 ,即更高斯。对其进行normalization更能产生稳定分布的激活。
更加具有对称性,非稀疏分布 ,即更高斯。对其进行normalization更能产生稳定分布的激活。
因此BN的对象是线性变换的输出。
这时 中偏置可以忽略。
中偏置可以忽略。
偏置b的作用可以被BN的中心化取消,且后面scale部分会有shift。最终的公式如下:
添加BN后可以采用更大学习
通过bn整个网络的激活值,在数据通过深度网络传播时,它可以防止层参数的微小变化被放大。(梯度消失)
bn使参数缩放更有弹性。通常,大的学习率可能增加参数的缩放,这在BP时会放大梯度并导致梯度爆炸。通过BN,bp不受其参数缩放的影响。
实验1:minist训练
a图是性能和迭代次数。b,c是某一层的激活值分布。添加bn训练收敛更快且性能更优,且分布更加稳定。

实验2:Imagenet Classfication
训练tricks:1.提高学习率。大学习率依然能收敛。2.去掉dropout。删除后获得更高的验证准确率。推测bn能提供类似dropout的正则化收益。(这里只测试了验证集,感觉不够严密)。3.更彻底的shuffle。防止同一类一起出现在同一个minibatch。验证集提高了1%。4.减小L2正则权重。减小5倍后验证集性能提高。(相当于caffe里deacy)。5.加速学习率衰减。训练时间更短。6.去掉RPN。7.减少photometric distortions(光照扭曲)。
单模型实验:
Inception
BN-Baseline:在Inception 基础上加bn
BN-x5: 在BN-Baseline 基础上增大5倍学习率到0.0075
BN-x30:在BN-Baseline 基础上增大30倍学习率到0.045
BN-x5-Sigmoid:使用sigmoid替代ReLU

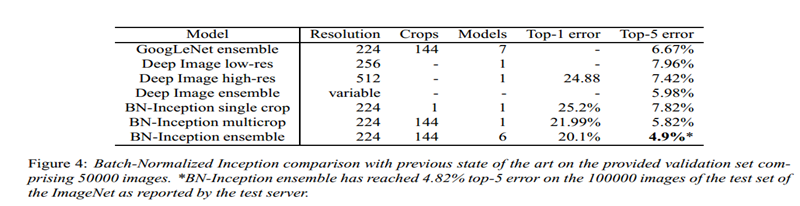
多模型实验结果:
(BN-inception就是我们说的V2)
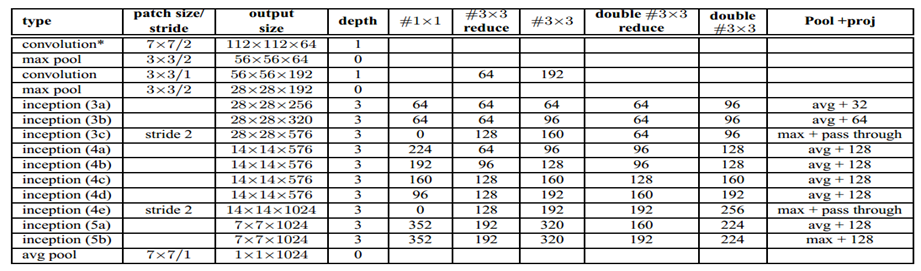
附录BN-inception的结构
V1到BN的改动:1.2个3*3代替5*5。2.28*28 modules从2个增加到3个。3.在modules中,pooling有时average ,有时maximum 。4.
没有across board pooling layers在任意两个inception modules。只在3c,4e里会有stride-2的卷积和pooling。
网络结构解读之inception系列三:BN-Inception(Inception V2)的更多相关文章
- 网络结构解读之inception系列五:Inception V4
网络结构解读之inception系列五:Inception V4 在残差逐渐当道时,google开始研究inception和残差网络的性能差异以及结合的可能性,并且给出了实验结构. 本文思想阐述不多, ...
- 网络结构解读之inception系列四:Inception V3
网络结构解读之inception系列四:Inception V3 Inception V3根据前面两篇结构的经验和新设计的结构的实验,总结了一套可借鉴的网络结构设计的原则.理解这些原则的背后隐藏的 ...
- 网络结构解读之inception系列二:GoogLeNet(Inception V1)
网络结构解读之inception系列二:GoogLeNet(Inception V1) inception系列的开山之作,有网络结构设计的初期思考. Going deeper with convolu ...
- 网络结构解读之inception系列一:Network in Network
网络结构解读之inception系列一:Network in Network 网上有很多的网络结构解读,之前也是看他人博客的介绍,但当自己看论文的时候,发现存在很多的细节和动机解读,而这部分能加深 ...
- NASNet学习笔记—— 核心一:延续NAS论文的核心机制使得能够自动产生网络结构; 核心二:采用resnet和Inception重复使用block结构思想; 核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
from:https://blog.csdn.net/xjz18298268521/article/details/79079008 NASNet总结 论文:<Learning Transfer ...
- Inception系列
从GoogLeNet的Inceptionv1开始,发展了众多inception,如inception v2.v3.v4与Inception-ResNet-V2. 故事还是要从inception v1开 ...
- Inception系列理解
博客:博客园 | CSDN | blog 写在前面 Inception 家族成员:Inception-V1(GoogLeNet).BN-Inception.Inception-V2.Inception ...
- 『高性能模型』卷积复杂度以及Inception系列
转载自知乎:卷积神经网络的复杂度分析 之前的Inception学习博客: 『TensorFlow』读书笔记_Inception_V3_上 『TensorFlow』读书笔记_Inception_V3_下 ...
- Inception系列之Inception_v1
目前,神经网络模型为了得到更好的效果,越来越深和越来越宽的模型被提出.然而这样会带来以下几个问题: 1)参数量,计算量越来越大,在有限内存和算力的设备上,其应用也就越难以落地. 2)对于一些数据集较少 ...
随机推荐
- android Toast提示异常:java.lang.RuntimeException: Can't create handler inside thread that has not called
Toast只能在UI线程弹出,解决此问题可以在Toast前后加两行代码,如下所示: Looper.prepare(); Toast.makeText(getApplicationContext(),& ...
- 分享安装Apache、MySQL、PHP、LAMP的完整教程
Operation timed out after 30000 milliseconds with 0 out of -1 bytes received请注意,在Linux中输入密码时,不会显示您输入 ...
- 长链接生成短链接Java源码(调用百度接口)
public static DefaultHttpClient httpclient; static { httpclient = new DefaultHttpClient(); //httpcli ...
- Oracle大数据SQL语句优化
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 阿里云图数据库GraphDB上线,助力图数据处理
GraphDB简介 GraphDB图数据库适用于存储,管理,查询复杂并且高度连接的数据,图库的结构特别适合发现大数据集下数据之间的共性和特性,特别善于释放蕴含在数据关系之间的巨大价值.GraphDB引 ...
- 访问配置信息的URL与配置文件的映射关系
- MT Call来电流程分析????
- element表单验证
rules: { name:[{ required: true, message: '请输入用户名', trigger: 'blur' },{ min: 2, max: 5, message: '长度 ...
- 关于java 线程的停止同时用 interrupt 和 join 的作用
/** * @FileName: ThreadTest.java * @Description: * @Author : xingchong * @CreateTime: Sep 22, 2018 1 ...
- [转]Git 常用命令详解
史上最浅显易懂的Git教程 http://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000/ ht ...