并发编程之线程池ThreadPoolExecutor
前言
在我们平时自己写线程的测试demo时,一般都是用new Thread的方式来创建线程。但是,我们知道创建线程对象,就会在内存中开辟空间,而线程中的任务执行完毕之后,就会销毁。
单个线程的话还好,如果线程的并发数量上来之后,就会频繁的创建和销毁对象。这样,势必会消耗大量的系统资源,进而影响执行效率。
所以,线程池就应运而生。
线程池ThreadPoolExecutor
可以通过idea先看下线程池的类图,了解一下它的继承关系和大概结构。

它继承自AbstractExecutorService类,这是一个抽象类,不过里边的方法都是已经实现好的。然后这个类实现了ExecutorService接口,里边声明了各种方法,包括关闭线程池,以及线程池是否已经终止等。此接口继承自父接口Executor,里边只声明了一个execute方法。
线程池就是为了解决单个线程频繁的创建和销毁带来的性能开销。同时,可以帮我们自动管理线程。并且不需要每次执行新任务都去创建新的线程,而是重复利用已有的线程,大大提高任务执行效率。
我们打开 ThreadPoolExecutor的源码,可以看到总共有四个构造函数。
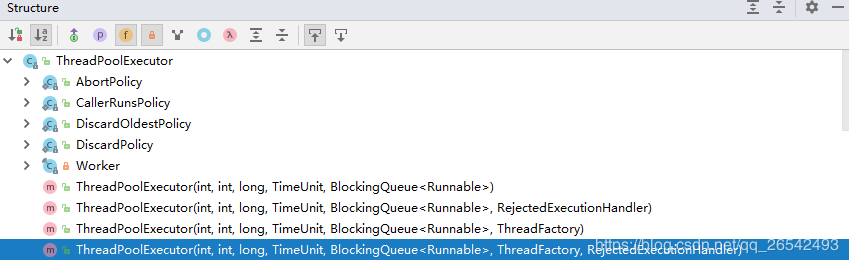
但是,前三个最终都会调用到最后一个构造函数。我们来看下这个构造函数都有哪些参数。(其实,多看下参数的英文解释就能明白其中的含义,看来英语对程序员来说是真的重要呀)
//核心构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
1)corePoolSize
代表核心线程数。每当新的任务提交过来的时候,线程池就会创建一个核心线程来执行这个任务,即使已经有其他的核心线程处于空闲状态。 而当需要执行的任务数大于核心线程数时,将不再创建新的核心线程。
其实,我们可以看下JDK提供的官方注释说明。even if they are idle,就照应上边的加粗字体。

此外,最后一句话说,除非allowCoreThreadTimeOut 这个参数被设置了值。

什么意思呢,可以去看下这个参数默认值是false,代表当核心线程在空闲状态时,即没有任务在执行,就会一直存活,不会销毁。而设置为true之后,就会有线程存活时间,即假如设置存活时间60秒,则60秒之后,如果没有新的可执行任务,则核心线程也会自动销毁。
2)maximumPoolSize
线程所允许的最大数量。即,当阻塞队列已满的时候,并且已经创建的线程数小于最大线程数,则会创建新的线程去执行任务。所以,这个参数只有在阻塞队列满的情况下才有意义。因此,对于无界队列,这个参数将会失去效果。
3)keepAliveTime
代表线程空闲后,保持存活的时间。也就是说,超过一定的时间没有任务执行,线程就会自动销毁。
注意,这个参数,是针对大于核心线程数,小于最大线程数的那部分非核心线程来说的。如果是任务数量特别多的情况下,可以适当增加这个参数值的大小。以保证,在下个任务到来之前,此线程不会立即销毁,从而避免线程的重新创建。
4)unit
这个是描述存活时间的时间单位。可以使用TimeUnit里边的枚举值。
5)workQueue
代表阻塞队列,存储所有等待执行的任务。
6)threadFactory
代表用来创建线程的工厂。可以自定义一个工厂,传参进来。如果不指定的话,就会使用默认工厂(Executors类里边的 DefaultThreadFactory)。
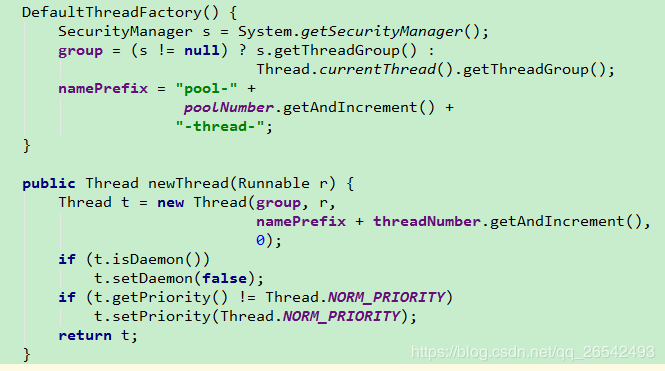
可以看到,会给每个线程的名字指定一个有规律的前缀。并且每个线程都设置相同的优先级(优先级总共有三个,1、5、10)。优先级可以理解为,优先级高的线程被执行的概率会更高,但是不代表优先级高的线程一定会先执行。
7)handler
这个参数代表,拒绝策略。当阻塞队列和线程池都满了,即达到了最大线程数,会用什么策略来处理。一共有四种策略可供选择,分别对应四个内部类。
- AbortPolicy:直接拒绝,并抛出异常,这也是默认的策略。
- CallerRunsPolicy:直接让调用execute方法的线程去执行此任务。
- DiscardOldestPolicy:丢弃最老的未处理的任务,然后重新尝试执行当前的新任务。
- DiscardPolicy:直接丢弃当前任务,但是不抛异常。
总结一下线程池的执行过程。
- 当线程数量未达到corePoolSize的时候,就会创建新的线程来执行任务。
- 当核心线程数已满,就会把任务放到阻塞队列。
- 当队列已满,并且未达到最大线程数,就会新建非核心线程来执行任务。
- 当队列已满,并且达到了最大线程数,则选择一种拒绝策略来执行。
线程池常用的一些方法
我们一般用 execute 方法来提交任务给线程池。当线程需要返回值时,可以使用submit 方法。
shutdown方法用来关闭线程池。注意,此时不再接受新提交的任务,但是,会继续处理正在运行的任务和阻塞队列里边的任务。
shutdownNow也会关闭线程池。但是,它不再接受新任务,并且会尝试终止正在运行的任务。
用Executors创建线程池
了解了线程池工作流程之后,那么我们怎样去创建它呢。
Executors类提供了四种常用的方法。可以发现它们最终都调用了线程池的构造方法。都有两种创建方式,其中一种可以传自定义的线程工厂。此处,只贴出不带工厂的方法便于理解。
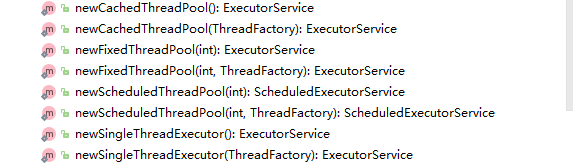
①newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
创建一个固定大小的线程池。核心线程数和最大线程数相等。当线程数量达到核心线程数时,新任务就会放到阻塞队列里边等待执行。
②newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
创建一个核心线程数和最大线程数都是1的线程池。即线程池中只会存在一个正在执行的线程,若线程空闲则执行,否则把任务放到阻塞队列。
③ newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
创建一个可根据实际情况调整线程个数的线程池。这句话,可以理解为,有多少任务同时进来,就会创建同等数量的线程去执行任务。当然,这是在线程数不能超过Integer最大值的前提下。
当再来一个新任务时,若有空闲线程则执行任务。否则,等线程空闲60秒之后,就会自动回收。
当没有新任务,就不会创建新的线程。
④newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
创建一个可指定核心线程数的线程池。这个线程池可以执行周期性的任务。
如果本文对你有用,欢迎点赞,评论,转发。
学习是枯燥的,也是有趣的。我是「烟雨星空」,欢迎关注,可第一时间接收文章推送。
并发编程之线程池ThreadPoolExecutor的更多相关文章
- Java并发编程:线程池ThreadPoolExecutor
多线程的程序的确能发挥多核处理器的性能.虽然与进程相比,线程轻量化了很多,但是其创建和关闭同样需要花费时间.而且线程多了以后,也会抢占内存资源.如果不对线程加以管理的话,是一个非常大的隐患.而线程池的 ...
- 并发编程 13—— 线程池的使用 之 配置ThreadPoolExecutor 和 饱和策略
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程:线程池的使用(转)
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- (转)Java并发编程:线程池的使用
背景:线程池在面试时候经常遇到,反复出现的问题就是理解不深入,不能做到游刃有余.所以这篇博客是要深入总结线程池的使用. ThreadPoolExecutor的继承关系 线程池的原理 1.线程池状态(4 ...
- Java并发编程:线程池的使用(转载)
转载自:https://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- Java并发编程:线程池的使用(转载)
文章出处:http://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- [转]Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
随机推荐
- Mysql.复选条件的查询
场景:有筛选条件 联盟:1.复联 2.正义联盟 3.猛禽小队,条件可多选,求查询结果. name league 飞人 复联,正义联盟 黑人 复联,正义联盟,猛禽小队 打手枪的男人 复联,猛禽小队 深井 ...
- 通过示例学习rholang(下部:课程8-13)
课程8——状态通道和方法 保存数据 到现在为止,你已经很擅长于发送数据到元组空间和从元组空间中获取数据.但是无论你在什么时候进行计算,你有时需要把一些数据放在一边晚点才使用.几乎所有编程语言都有变量的 ...
- 痞子衡嵌入式:嵌入式里堆栈原理及其纯C实现
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家讲的是嵌入式里堆栈原理及其纯C实现. 今天给大家分享的这篇还是2016年之前痞子衡写的技术文档,花了点时间重新编排了一下格式.栈这种结构在嵌入式 ...
- tensorflow 案例
import tensorflow as tf import numpy as np #添加一层inputs输入的数据,in_size为输入节点数,out_size为输出节点数,下一个为激励函数 de ...
- Shiro Web集成及拦截器机制(四)
Shiro与 Web 集成 Shiro 提供了与 Web 集成的支持,其通过一个 ShiroFilter 入口来拦截需要安全控制的 URL,然后进行相应的控制,ShiroFilter 类似于如 Str ...
- 【WPF学习】第三十章 元素绑定——绑定到非元素对象
前面章节一直都在讨论如何添加链接两个各元素的绑定.但在数据驱动的应用程序中,更常见的情况是创建从不可见对象中提取数据的绑定表达式.唯一的要求是希望显示的信息必须存储在公有属性中.WPF数据绑定数据结构 ...
- 如何优雅的将Mybatis日志中的Preparing与Parameters转换为可执行SQL
原文链接 疫情期间大家宅在家里是不是已经快憋出“病”了~~ 公司给开了VPN,手机电脑都能连,手机装上APP测试包,就能干活了,所以walking从2020.02.01入京以来,已经窝在家里11天 ...
- c++IO对象不可复制
IO类型的3个独立的头文件: iostream定义读写控制窗口的类型, fstream 定义读写已命名文件的类型, (包含fstream类) sstream定义读写存储在内存中 ...
- Netty源码分析之ChannelPipeline—入站事件的传播
之前的文章中我们说过ChannelPipeline作为Netty中的数据管道,负责传递Channel中消息的事件传播,事件的传播分为入站和出站两个方向,分别通知ChannelInboundHandle ...
- 关于centos7下networkManager关闭操作
由于network和NetworkManager服务会出现冲突,而且NetworkManager通常会比较先启动,所以为了防止NetworkManager的启动导致我们直接配置的网络环境失效,我们需要 ...