Linux运维---1.磁盘相关知识
一 磁盘物理结构
(1) 盘片:硬盘的盘体由多个盘片叠在一起构成。
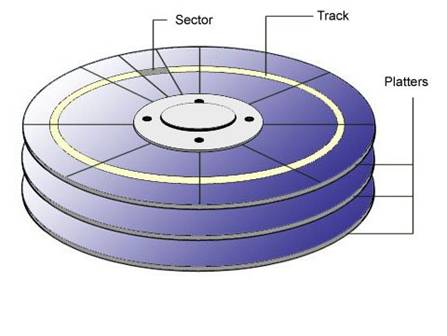
在硬盘出厂时,由硬盘生产商完成了低级格式化(物理格式化),作用是将空白的盘片(Platter)划分为一个个同圆心、不同半径的磁道(Track),还将磁道划分为若干个扇区(Sector),每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息,默认每个扇区的大小为512字节。通常使用者无需再进行低级格式化操作。
(2) 磁头:每张盘片的正反两面各有一个磁头。
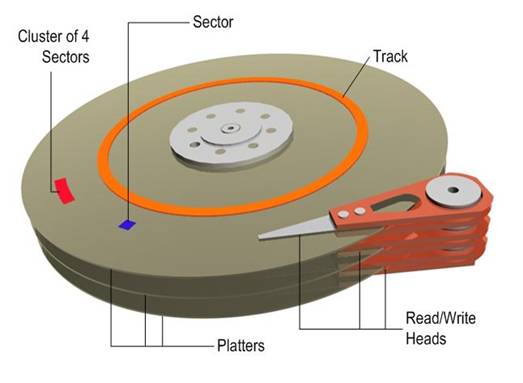
(3) 主轴:所有盘片都由主轴电机带动旋转。

(4) 控制集成电路板:复杂!上面还有ROM(内有软件系统)、Cache等。

二 磁盘如何完成单次IO操作
(1) 寻道
当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带动磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻道(Seeking),对应消耗的时间被称为寻道时间(Seek Time);
(2) 旋转延迟
找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正下方之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Latency);
(3) 数据传送
接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后单次IO操作也就完成了。
根据磁盘单次IO操作的过程,可以发现:
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间
进而推算IOPS(IO per second)的公式为:
IOPS = 1000ms/单次IO时间
三 磁盘IOPS计算
不同磁盘,它的寻道时间,旋转延迟,数据传送所需的时间各是多少?
1. 寻道时间
考虑到被读写的数据可能在磁盘的任意一个磁道,既有可能在磁盘的最内圈(寻道时间最短),也可能在磁盘的最外圈(寻道时间最长),所以在计算中我们只考虑平均寻道时间。
在购买磁盘时,该参数都有标明,目前的SATA/SAS磁盘,按转速不同,寻道时间不同,不过通常都在10ms以下:
|
转速 |
平均寻道时间 |
|
15000rpm |
2~3ms |
|
10000rpm |
3~5ms |
|
7200rpm |
8~9ms |
2. 旋转延时
和寻道一样,当磁头定位到磁道之后有可能正好在要读写扇区之上,这时候是不需要额外的延时就可以立刻读写到数据,但是最坏的情况确实要磁盘旋转整整一圈之后磁头才能读取到数据,所以这里也考虑的是平均旋转延时,对于15000rpm的磁盘就是(60s/15000)*(1/2)
= 2ms。
3. 传送时间
(1) 磁盘传输速率
磁盘传输速率分两种:内部传输速率(Internal Transfer Rate),外部传输速率(External Transfer Rate)。
内部传输速率(Internal Transfer Rate),是指磁头与硬盘缓存之间的数据传输速率,简单的说就是硬盘磁头将数据从盘片上读取出来,然后存储在缓存内的速度。
理想的内部传输速率不存在寻道,旋转延时,就一直在同一个磁道上读数据并传到缓存,显然这是不可能的,因为单个磁道的存储空间是有限的;
实际的内部传输速率包含了寻道和旋转延时,目前家用磁盘,稳定的内部传输速率一般在30MB/s到45MB/s之间(服务器磁盘,应该会更高)。
外部传输速率(External Transfer Rate),是指硬盘缓存和系统总线之间的数据传输速率,也就是计算机通过硬盘接口从缓存中将数据读出交给相应的硬盘控制器的速率。
硬盘厂商在硬盘参数中,通常也会给出一个最大传输速率,比如现在SATA3.0的6Gbit/s,换算一下就是6*1024/8,768MB/s,通常指的是硬盘接口对外的最大传输速率,当然实际使用中是达不到这个值的。
这里计算IOPS,保守选择实际内部传输速率,以40M/s为例。
(2) 单次IO操作的大小
有了传送速率,还要知道单次IO操作的大小(IO Chunk Size),才可以算出单次IO的传送时间。那么磁盘单次IO的大小是多少?答案是:不确定。
操作系统为了提高
IO的性能而引入了文件系统缓存(File System
Cache),系统会根据请求数据的情况将多个来自IO的请求先放在缓存里面,然后再一次性的提交给磁盘,也就是说对于数据库发出的多个8K数据块的读操作有可能放在一个磁盘读IO里就处理了。还有,有些存储系统也是提供了缓存(Cache),接收到操作系统的IO请求之后也是会将多个操作系统的
IO请求合并成一个来处理。
不管是操作系统层面的缓存,还是磁盘控制器层面的缓存,目的都只有一个,提高数据读写的效率。因此每次单独的IO操作大小都是不一样的,它主要取决于系统对于数据读写效率的判断。这里以SQL Server数据库的数据页大小为例:8K。
(3) 传送时间
传送时间 = IO Chunk Size/Internal Transfer Rate = 8k/40M/s = 0.2ms
可以发现:
(3.1) 如果IO Chunk Size大的话,传送时间会变长,单次IO时间就也变长,从而导致IOPS变小;
(3.2) 机械磁盘的主要读写成本,都花在了寻址时间上,即:寻道时间 + 旋转延迟,也就是磁盘臂的摆动,和磁盘的旋转延迟。
(3.3) 如果粗略的计算IOPS,可以忽略传送时间,1000ms/(寻道时间 + 旋转延迟)即可。
4. IOPS计算示例
以15000rpm为例:
(1) 单次IO时间
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间 = 3ms + 2ms + 0.2 ms = 5.2 ms
(2) IOPS
IOPS = 1000ms/单次IO时间 = 1000ms/5.2ms = 192 (次)
这里计算的是单块磁盘的随机访问IOPS。
考虑一种极端的情况,如果磁盘全部为顺序访问,那么就可以忽略:寻道时间 + 旋转延迟 的时长,IOPS的计算公式就变为:IOPS = 1000ms/传送时间
IOPS = 1000ms/传送时间= 1000ms/0.2ms = 5000 (次)
显然这种极端的情况太过理想,毕竟每个磁道的空间是有限的,寻道时间 + 旋转延迟 时长确实可以减少,不过是无法完全避免的。
四 数据库中的磁盘读写
1. 随机访问和连续访问
(1) 随机访问(Random Access)
指的是本次IO所给出的扇区地址和上次IO给出扇区地址相差比较大,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
(2) 连续访问(Sequential Access)
相反的,如果当次IO给出的扇区地址与上次IO结束的扇区地址一致或者是接近的话,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
(3) 以SQL Server数据库为例
数据文件,SQL Server统一区上的对象,是以extent(8*8k)为单位进行空间分配的,数据存放是很随机的,哪个数据页有空间,就写在哪里,除非通过文件组给每个表预分配足够大的、单独使用的文件,否则不能保证数据的连续性,通常为随机访问。
另外哪怕聚集索引表,也只是逻辑上的连续,并不是物理上。
日志文件,由于有VLF(virtual log file)的存在,日志的读写理论上为连续访问,但如果日志文件设置为自动增长,且增量不大,VLF就会很多很小,那么就也并不是严格的连续访问了。
2. 顺序IO和并发IO
(1) 顺序IO模式(Queue Mode)
磁盘控制器可能会一次对磁盘组发出一连串的IO命令,如果磁盘组一次只能执行一个IO命令,称为顺序IO;
(2) 并发IO模式(Burst Mode)
当磁盘组能同时执行多个IO命令时,称为并发IO。并发IO只能发生在由多个磁盘组成的磁盘组上,单块磁盘只能一次处理一个IO命令。
(3) 以SQL Server数据库为例
有的时候,尽管磁盘的IOPS(Disk Transfers/sec)还没有太大,但是发现数据库出现IO等待,为什么?通常是因为有了磁盘请求队列,有过多的IO请求堆积。
磁盘的请求队列和繁忙程度,通过以下性能计数器查看:
LogicalDisk/Avg.Disk Queue Length (处理列队中的队列的平均长度)
LogicalDisk/Current Disk Queue Length
LogicalDisk/%Disk Time 磁盘利用率
这种情况下,可以做的是:
(1) 简化业务逻辑,减少IO请求数;
(2) 同一个实例下的多个用户数据库,迁移到不同实例下;
(3) 同一个数据库的日志、数据文件,分离到不同的存储单元;
(4) 借助HA策略,做读写操作的分离。
3. IOPS和吞吐量(throughput)
(1) IOPS
IOPS即每秒进行读写(I/O)操作的次数。在计算传送时间时,有提到:如果IO Chunk Size大的话,那么IOPS会变小,假设以100M为单位读写数据,那么IOPS就会很小。
(2) 吞吐量(throughput)
吞吐量指每秒可以读写的字节数。同样假设以100M为单位读写数据,尽管IOPS很小,但是每秒读写了N*100M的数据,吞吐量并不小。
(3) 以SQL Server数据库为例
对于OLTP(On-Line Transaction Processing)的系统,经常读写小块数据,多为随机访问,用IOPS来衡量读写性能;
对于数据仓库,日志文件,经常读写大块数据,多为顺序访问,用吞吐量来衡量读写性能。
磁盘当前的IOPS,通过以下性能计数器查看:
LogicalDisk/Disk Transfers/sec
LogicalDisk/Disk Reads/sec
LogicalDisk/Disk Writes/sec
磁盘当前的吞吐量,通过以下性能计数器查看:
LogicalDisk/Disk Bytes/sec
LogicalDisk/Disk Read Bytes/sec
LogicalDisk/Disk Write Bytes/sec
Linux运维---1.磁盘相关知识的更多相关文章
- linux运维需要掌握什么知识?linux运维学习路线
linux运维需要掌握什么知识?这个问题算是老生常谈了,但是本人认为知道需要掌握什么知识不是重点,重点是我们需要知道运维是做什么的?再来根据工作需求去讨论需要学习什么知识才是正途,须知知识是学不完的, ...
- Linux运维学习笔记-文件系统知识体系总结
文件系统知识总结 新买的硬盘要存放数据需要怎么做? 首先将硬盘装机做RAID,做完RAID后进行分区,分完区后格式化创建文件系统,最后存放数据. 硬盘的内外部结构: 物理形状: 接口类型: IDE(I ...
- linux运维常用命令及知识
1.查找当前目录下所有以.tar结尾的文件然后移动到指定目录: find . -name “*.tar” -exec mv {} ./backup/ ; 查找当前目录30天以前大于100M的LOG文件 ...
- Linux运维学习笔记-角色知识总结
角色通过UID和GID区分 root:超级管理员,拥有所有权限,UID(0). 普通用户:拥有操作自己家目录下的所有权限,其他文件及目录(/etc./var)只有读的权限,UID(500-65535) ...
- Linux运维学习笔记-iptables知识总结
- Linux运维学习笔记-定时任务知识总结
定时任务编辑规范流程: 重要知识点: 切记用全路径编写定时脚本.定时任务 大部分在 crontab 计划任务中都会年到未尾带 >/dev/null 2>&1,是什么意思呢? > ...
- 亲爱的,我是一条Linux运维技术学习路径呀。
根据我的经验,人在年轻时,最头疼的一件事就是决定自己这一生要做什么.在这方面,我倒没有什么具体的建议:干什么都可以,但最好不要写小说,这是和我抢饭碗.总而言之,干什么都是好的:但要干出个样子来,这才是 ...
- linux 运维知识体系
这里将会介绍一下,LINUX运维工程师的知识体系. 只能说是个人理解吧.并不是必要或者充分的,仅供网友参考. 大部分本博客都有涉及,并不完整. 1.LINUX运维基础 1.1.LINUX系统的简介,分 ...
- 转载---linux运维相关
前段时间,我在准备面试的时搜到的一套Linux运维工程师面试题,感觉比较全面,一直保存在草稿,刚在整理后台时翻了出来,干脆就发出来好了,以备不时之需. 1.linux如何挂在windows下的共享目录 ...
随机推荐
- 20191102Java课堂记录
1. import javax.swing.*; class AboutException { public static void main(String[] a) { int i=1, j=0, ...
- SuperSocket Code解析
SuperSocket1.6Code解析 Normal Socket System.Net.Sockets.dll程序集中使用socket类: 服务器: 创建socket:_socket = new ...
- MySQL军规升级版(转)
一.基础规范 表存储引擎必须使用InnoDB 表字符集默认使用utf8,必要时候使用utf8mb4 解读:(1)通用,无乱码风险,汉字3字节,英文1字节(2)utf8mb4是utf8的超集,有存储4字 ...
- AVL练习题——宠物收养所
题目描述 最近,阿Q开了一间宠物收养所.收养所提供两种服务:收养被主人遗弃的宠物和让新的主人领养这些宠物.每个领养者都希望领养到自己满意的宠物,阿Q根据领养者的要求通过他自己发明的一个特殊的公式,得出 ...
- selenium,统计某分支下有多少个同类子分支的方法(用于循环获取同类型子分支属性值)
利用selenium自动化统计微博阅读数 查看微博阅读数的元素路径 微博列表中第一条微博的元素路径“//*[@id="Pl_Official_MyProfileFeed__20"] ...
- CSS-12-盒子模型
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- mui html5 plus
mui: mod:框架 mhe:头文件 mbody:内容 mta:底部 msl:轮播图 mg:九宫格 ml:图文列表 mu.post : ajax dga: 绑定事件 mui.toast :来实 ...
- 数据结构与算法 --- js二分算法
var arr = [-34, 1, 3, 4, 5, 8, 34, 45, 65, 87]; //递归方式 function binarySearch(data,dest,start,end ){ ...
- H5新增特性
1.pattern:写正则,但是需要和form表单连着用 2.WebSocket "网络套接字", 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议.在 W ...
- Redis入门,Jedis和常用命令
一.Redis简介 1.关于关系型数据库和nosql数据库 关系型数据库是基于关系表的数据库,最终会将数据持久化到磁盘上,而nosql数据 库是基于特殊的结构,并将数据存储到内存的数据库.从性 ...