MySQL学习(七) 索引选择(半原创)
概述
该篇文章主要阐述一个例子(例子来自参考资料,侵删),然后总结今天相关的知识点。
例子 (例子来自参考文章,非原创)
创建表并插入数据,并执行查询
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB; delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata(); mysql> select * from t where a between 10000 and 20000;

可以看到该语句查询使用到了索引,然后进行如下操作

下面的三条SQL语句,就是这个实验过程。
set long_query_time=0;
select * from t where a between 10000 and 20000; /*Q1*/
select * from t force index(a) where a between 10000 and 20000;/*Q2*/
- 第一句,是将慢查询日志的阈值设置为0,表示这个线程接下来的语句都会被记录入慢查询日志中;
- 第二句,Q1是session B原来的查询;
- 第三句,Q2是加了force index(a)来和session B原来的查询语句执行情况对比。
我们在第三条语句指定了强制使用a 索引,假如第三天语句执行的时间快过第二条的,那么我们可以认为数据库选错了索引,相反没有选错, 如图3所示是这三条SQL语句执行完成后的慢查询日志。
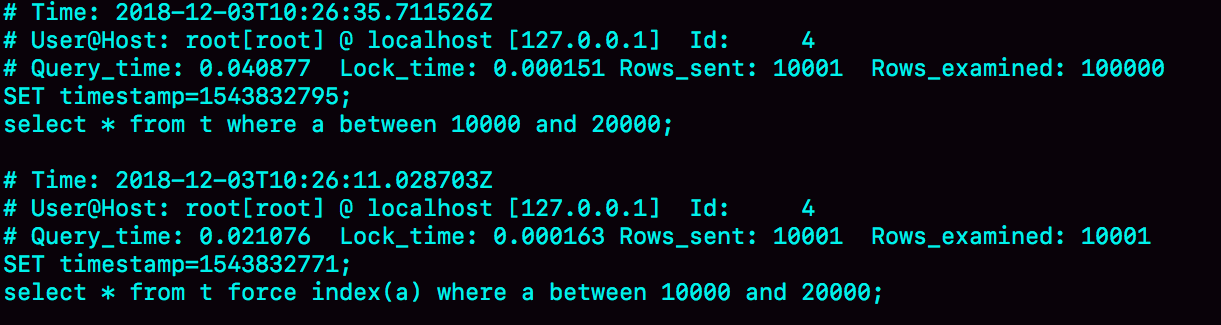
可以看到数据库确实选错了索引,我们要知道为什么选错了索引就要知道数据库是如何选择索引的。
优化器
我们从开始MySQL 架构图可以知道执行语句要经过一个优化器的组件,这个组件就相当于决策大脑,为语句选择合适的索引。
分析
一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。 而选择索引肯定看区分度高的索引,区分度高的索引能够准确找到符合条件的记录。思路如下 :
选择索引 -> 选择区分度高的索引 --> 如何找到区分度高的索引 --> 抽样统计算法
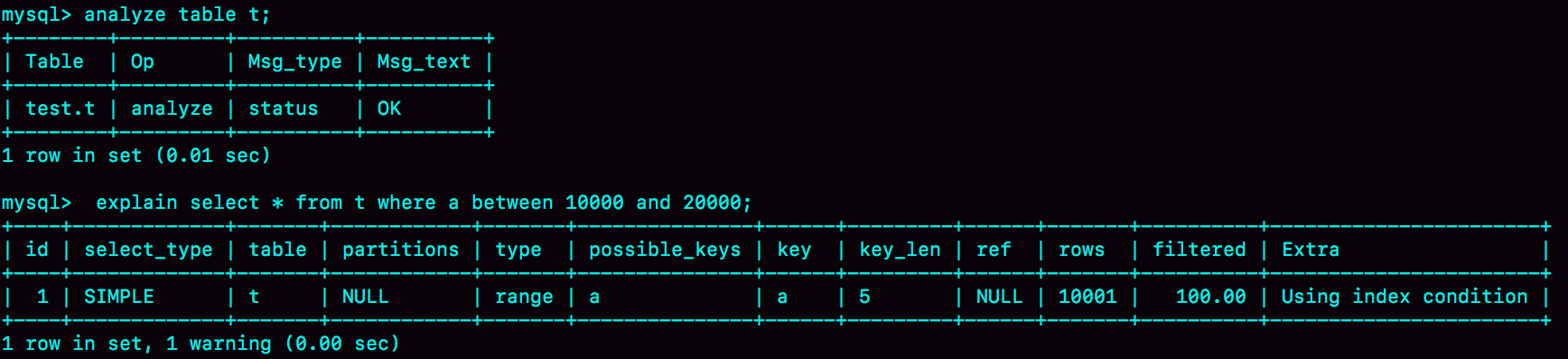
我们可以使用show index方法,看到一个索引的基数。如图4所示,就是表t的show index 的结果 。虽然这个表的每一行的三个字段值都是一样的,但是在统计信息中,这三个索引的基数值并不同,而且其实都不准确。

假如数据库一行行去统计,对于大的表肯定是不行的,于是数据库就使用抽样统计。
采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择:
- 设置为on的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10。
- 设置为off的时候,表示统计信息只存储在内存中。这时,默认的N是8,M是16。
由于是采样统计,所以不管N是20还是8,这个基数都是很容易不准的。扫描的行数是一方面,还有一方面,例如使用非聚集索引的话还需要回表也是需要时间成本,优化器会从各个方面综合考虑最终得出最优解。
矫正统计错误
可以看到我们上面的统计是存在误差的,那么纠正这个偏差的方法肯定是让优化器再次统计一下。
补充题外话
count(*)、count(主键id)、count(字段)和count(1) 的区别?
count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;
而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。
对于count(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
注意哦,sever 自己判断
对于count(1)来说,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
对于count(字段)来说:
如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;
如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
也就是前面的第一条原则,server层要什么字段,InnoDB就返回什么字段。
#### 但是count()是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count()肯定不是null,按行累加。
按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(),所以我建议你,尽量使用count()
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
参考资料
- 《MySQL 45讲》
MySQL学习(七) 索引选择(半原创)的更多相关文章
- 【笔记】MySQL学习之索引
[笔记]MySQL学习之索引 一 索引简单介绍 索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可. 普通 ...
- MySql学习(七) —— 查询性能优化 深入理解MySql如何执行查询
本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避 ...
- MySQL学习13 - 索引
一.索引的介绍 二 .索引的作用 三.常见的几种索引: 3.1 普通索引 3.2 唯一索引 3.3 主键索引 3.4 组合索引 四.索引名词 五.正确使用索引的情况 什么是最左前缀呢? 六.索引的注意 ...
- Mysql学习笔记—索引
一.什么是索引 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重. 在数据 ...
- MYSQL学习(三) --索引详解
创建高性能索引 (一)索引简介 索引的定义 索引,在数据结构的查找那部分知识中有专门的定义.就是把关键字和它对应的记录关联起来的过程.索引由若干个索引项组成.每个索引项至少包含两部分内容.关键字和关键 ...
- MySQL学习(七)
学习子查询 1 查出本网站最新的good_id最大的一条商品(要求取出商品名) mysql> select goos_id,goods_name from goods -> order b ...
- MySQL学习笔记——索引和视图
索引(index)和管理索引 模式中的一个数据库对象 作用:在数据库中用来加速对表的查询 创建:自动在主键和唯一键上面创建索引 通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O 与表独立存放, ...
- mysql学习之索引
首先,看一个例子,有一张大表,记录数超过1000,SELECT * FROM student WHERE name='xinan'; 如果没有索引,查找程序就得从头查找,很费时间,表越大越费时间.建立 ...
- mysql系列七、mysql索引优化、搜索引擎选择
一.建立适当的索引 说起提高数据库性能,索引是最物美价廉的东西了.不用加内存,不用改程序,不用调sql,只要执行个正确的'create index',查询速度就可能提高百倍千倍,这可真有诱惑力.可是天 ...
随机推荐
- 树hash/树哈希 刷题记录
不同hash姿势: 树的括号序列最小表示法 s[i] 如果i为叶子节点:() 如果i的子节点为j1~jn:(s[j1]...s[jn]),注意s[j]要按照字典序排列
- Java String类型转换成Date日期类型
插入数据库时,存入当前日期,需要格式转换 import java.text.SimpleDateFormat; formatter = new SimpleDateFormat( "yyyy ...
- C++ lambda函数及其用法(转)
由于接触C++不久,很多东西比较陌生,今天看阿里云OSS的C++ SDK文件下载部分例子,发现有如下lambda表达式用法,故了解一下相关知识 /*获取文件到本地文件*/ GetObjectReque ...
- Netty中CompositeByteBuf的理解以及读写操作
转载请注明出处 https://www.cnblogs.com/majianming/articles/the_composite_byte_buf_read_and_wite_operation_o ...
- 虚拟机floppy0
网上搜索方法是:删除该虚拟机的软盘即可. 具体原因还不知道,以后再补上原因
- 一道CTF针对XXE漏洞的练习
题目链接:http://web.jarvisoj.com:9882/ 目的很明确获取/home/ctf/flag.txt的内容 一般读取目标机的本地文件都会用到file协议. 思路: 那么思路一:文件 ...
- Quartz.NET 2.x教程
第1课:使用Quartz第2课:工作和触发器第3课:关于工作和JobDetails的更多信息第4课:有关触发器的更多信息第5课:SimpleTriggers第6课:CronTriggers第7课:Tr ...
- [ZJOI2009] 狼与羊的故事 - 最小割
给定一个\(N \times M\)方格矩阵,每个格子可在\(0,1,2\)中取值.要求在方格的边上进行划分,使得任意联通块内不同时包含\(1\)和\(2\)的格子. ________________ ...
- ArcGis Server manager 忘记用户名和密码
ArcGIS 10.1及以后版本重置Server Manager账户密码:(1)找到arcgis server的安装目录,目录指向\ArcGIS\Server\tools\passwordreset文 ...
- Session方法
Session的save()和persist()方法Session的save()方法使一个临时对象转变为持久化对象.它完成以下操作:(1)将临时对象加入到Session缓存中,使其进入持久化状态.(2 ...