Scala与Mongodb实践3-----运算环境的搭建
目的:使的在IDEA中编辑代码,令代码实现mongodb运算,且转换较为便捷
- 由实验2可知,运算环境的搭建亦需要对数据进行存储和计算,故需要实现类型转换,所以在实验2的基础上搭建环境。
- 由菜鸟教程可得到mongodb命令的具体格式等,如:新建集合
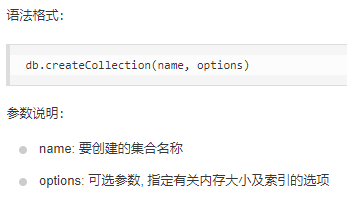
==》可以新建:
case class CreateCollection(name:String,options:Options[Any]=None) //其他的mongodb命令也是照着这样建立的
由org.mongodb.scala.model.Filters可知Filters内的相关方法的返回类型都是Bson。例子如下:
/**
* Creates a filter that matches all documents where the value of the given field is greater than the specified value.
*
* @param fieldName the field name
* @param value the value
* @tparam TItem the value type
* @return the filter
* @see [[http://docs.mongodb.org/manual/reference/operator/query/gt \$gt]]
*/
def gt[TItem](fieldName: String, value: TItem): Bson = JFilters.gt(fieldName, value) /**
* Creates a filter that matches all documents where the value of the given field is less than the specified value.
*
* @param fieldName the field name
* @param value the value
* @tparam TItem the value type
* @return the filter
* @see [[http://docs.mongodb.org/manual/reference/operator/query/lt \$lt]]
*/
def lt[TItem](fieldName: String, value: TItem): Bson = JFilters.lt(fieldName, value)
根据相关语法格式,可新建
case class Count(filter: Option[Bson], options: Option[Any])
- 执行相关命令需要引入数据库和集合,新建MGOContext.scala
case class MGOContext(
dbName:String,
collName:String,
action:MGOCommands=null
){ctx=>
def setDbName(name:String):MGOContext=ctx.copy(dbName=name) def setCollName(name:String):MGOContext=ctx.copy(collName=name) def setCommand(cmd:MGOCommands):MGOContext=ctx.copy(action=cmd)
} object MGOContext {
def apply(db:String,coll:String) = new MGOContext(db,coll) def apply(
db: String,
coll: String,
action: MGOCommands = null
): MGOContext = new MGOContext(db, coll, action) }
- 分别新建相关的数据库操作,新建MGOCommands.scala和MGOAdmins.scala
//MGOAdmins.scala
import org.bson.conversions.Bson object MGOAdmins {
case class DropCollection(collName: String) extends MGOCommands case class CreateCollection(collName: String, options: Option[Any] = None) extends MGOCommands case class ListCollection(dbName: String) extends MGOCommands case class CreateView(viewName: String, viewOn: String, pipeline: Seq[Bson], options: Option[Any] = None) extends MGOCommands case class CreateIndex(key: Bson, options: Option[Any] = None) extends MGOCommands case class DropIndexByName(indexName: String, options: Option[Any] = None) extends MGOCommands case class DropIndexByKey(key: Bson, options: Option[Any] = None) extends MGOCommands case class DropAllIndexes(options: Option[Any] = None) extends MGOCommands } //MGOCommands.scala
import org.mongodb.scala.{Document, FindObservable}
import org.mongodb.scala.bson.conversions.Bson
import org.mongodb.scala.model.WriteModel trait MGOCommands object MGOCommands {
case class Count(filter: Option[Bson], options: Option[Any]) extends MGOCommands case class Distict(fieldName: String, filter: Option[Bson]) extends MGOCommands case class Find[M](filter: Option[Bson] = None,
andThen: Option[FindObservable[Document] => FindObservable[Document]]= None,
converter: Option[Document => M] = None,
firstOnly: Boolean = false) extends MGOCommands case class Aggregate(pipeLine: Seq[Bson]) extends MGOCommands case class MapReduce(mapFunction: String, reduceFunction: String) extends MGOCommands case class Insert(newdocs: Seq[Document], options: Option[Any] = None) extends MGOCommands case class Delete(filter: Bson, options: Option[Any] = None, onlyOne: Boolean = false) extends MGOCommands case class Replace(filter: Bson, replacement: Document, options: Option[Any] = None) extends MGOCommands case class Update(filter: Bson, update: Bson, options: Option[Any] = None, onlyOne: Boolean = false) extends MGOCommands case class BulkWrite(commands: List[WriteModel[Document]], options: Option[Any] = None) extends MGOCommands }
- 综上所述,具体实现相关的操作
import org.mongodb.scala.{Document, MongoClient}
import org.mongodb.scala.model.{BulkWriteOptions, CountOptions, CreateCollectionOptions, CreateViewOptions, DeleteOptions, DropIndexOptions, IndexOptions, InsertManyOptions, InsertOneOptions, UpdateOptions}
import scala.concurrent.Future
object MGOEngine{
import MGOAdmins._
import MGOCommands._
def DAO[T](ctx: MGOContext)(implicit client: MongoClient): Future[T] = {
val db = client.getDatabase(ctx.dbName)
val coll = db.getCollection(ctx.collName)
ctx.action match {
case Count(Some(filter), Some(opt)) =>
coll.count(filter, opt.asInstanceOf[CountOptions])
.toFuture().asInstanceOf[Future[T]]
case Count(Some(filter), None) =>
coll.count(filter).toFuture()
.asInstanceOf[Future[T]]
case Count(None, None) =>
coll.count().toFuture()
.asInstanceOf[Future[T]]
/* distinct */
case Distict(field, Some(filter)) =>
coll.distinct(field, filter).toFuture()
.asInstanceOf[Future[T]]
case Distict(field, None) =>
coll.distinct((field)).toFuture()
.asInstanceOf[Future[T]]
/* find */
case Find(None, None, optConv, false) =>
if (optConv == None) coll.find().toFuture().asInstanceOf[Future[T]]
else coll.find().map(optConv.get).toFuture().asInstanceOf[Future[T]]
case Find(None, None, optConv, true) =>
if (optConv == None) coll.find().first().head().asInstanceOf[Future[T]]
else coll.find().first().map(optConv.get).head().asInstanceOf[Future[T]]
case Find(Some(filter), None, optConv, false) =>
if (optConv == None) coll.find(filter).toFuture().asInstanceOf[Future[T]]
else coll.find(filter).map(optConv.get).toFuture().asInstanceOf[Future[T]]
case Find(Some(filter), None, optConv, true) =>
if (optConv == None) coll.find(filter).first().head().asInstanceOf[Future[T]]
else coll.find(filter).first().map(optConv.get).head().asInstanceOf[Future[T]]
case Find(None, Some(next), optConv, _) =>
if (optConv == None) next(coll.find[Document]()).toFuture().asInstanceOf[Future[T]]
else next(coll.find[Document]()).map(optConv.get).toFuture().asInstanceOf[Future[T]]
case Find(Some(filter), Some(next), optConv, _) =>
if (optConv == None) next(coll.find[Document](filter)).toFuture().asInstanceOf[Future[T]]
else next(coll.find[Document](filter)).map(optConv.get).toFuture().asInstanceOf[Future[T]]
/* aggregate */
case Aggregate(pline) => coll.aggregate(pline).toFuture().asInstanceOf[Future[T]]
/* mapReduce */
case MapReduce(mf, rf) => coll.mapReduce(mf, rf).toFuture().asInstanceOf[Future[T]]
/* insert */
case Insert(docs, Some(opt)) =>
if (docs.size > 1) coll.insertMany(docs, opt.asInstanceOf[InsertManyOptions]).toFuture()
.asInstanceOf[Future[T]]
else coll.insertOne(docs.head, opt.asInstanceOf[InsertOneOptions]).toFuture()
.asInstanceOf[Future[T]]
case Insert(docs, None) =>
if (docs.size > 1) coll.insertMany(docs).toFuture().asInstanceOf[Future[T]]
else coll.insertOne(docs.head).toFuture().asInstanceOf[Future[T]]
/* delete */
case Delete(filter, None, onlyOne) =>
if (onlyOne) coll.deleteOne(filter).toFuture().asInstanceOf[Future[T]]
else coll.deleteMany(filter).toFuture().asInstanceOf[Future[T]]
case Delete(filter, Some(opt), onlyOne) =>
if (onlyOne) coll.deleteOne(filter, opt.asInstanceOf[DeleteOptions]).toFuture().asInstanceOf[Future[T]]
else coll.deleteMany(filter, opt.asInstanceOf[DeleteOptions]).toFuture().asInstanceOf[Future[T]]
/* replace */
case Replace(filter, replacement, None) =>
coll.replaceOne(filter, replacement).toFuture().asInstanceOf[Future[T]]
case Replace(filter, replacement, Some(opt)) =>
coll.replaceOne(filter, replacement, opt.asInstanceOf[UpdateOptions]).toFuture().asInstanceOf[Future[T]]
/* update */
case Update(filter, update, None, onlyOne) =>
if (onlyOne) coll.updateOne(filter, update).toFuture().asInstanceOf[Future[T]]
else coll.updateMany(filter, update).toFuture().asInstanceOf[Future[T]]
case Update(filter, update, Some(opt), onlyOne) =>
if (onlyOne) coll.updateOne(filter, update, opt.asInstanceOf[UpdateOptions]).toFuture().asInstanceOf[Future[T]]
else coll.updateMany(filter, update, opt.asInstanceOf[UpdateOptions]).toFuture().asInstanceOf[Future[T]]
/* bulkWrite */
case BulkWrite(commands, None) =>
coll.bulkWrite(commands).toFuture().asInstanceOf[Future[T]]
case BulkWrite(commands, Some(opt)) =>
coll.bulkWrite(commands, opt.asInstanceOf[BulkWriteOptions]).toFuture().asInstanceOf[Future[T]]
/* drop collection */
case DropCollection(collName) =>
val coll = db.getCollection(collName)
coll.drop().toFuture().asInstanceOf[Future[T]]
/* create collection */
case CreateCollection(collName, None) =>
db.createCollection(collName).toFuture().asInstanceOf[Future[T]]
case CreateCollection(collName, Some(opt)) =>
db.createCollection(collName, opt.asInstanceOf[CreateCollectionOptions]).toFuture().asInstanceOf[Future[T]]
/* list collection */
case ListCollection(dbName) =>
client.getDatabase(dbName).listCollections().toFuture().asInstanceOf[Future[T]]
/* create view */
case CreateView(viewName, viewOn, pline, None) =>
db.createView(viewName, viewOn, pline).toFuture().asInstanceOf[Future[T]]
case CreateView(viewName, viewOn, pline, Some(opt)) =>
db.createView(viewName, viewOn, pline, opt.asInstanceOf[CreateViewOptions]).toFuture().asInstanceOf[Future[T]]
/* create index */
case CreateIndex(key, None) =>
coll.createIndex(key).toFuture().asInstanceOf[Future[T]]
case CreateIndex(key, Some(opt)) =>
coll.createIndex(key, opt.asInstanceOf[IndexOptions]).toFuture().asInstanceOf[Future[T]]
/* drop index */
case DropIndexByName(indexName, None) =>
coll.dropIndex(indexName).toFuture().asInstanceOf[Future[T]]
case DropIndexByName(indexName, Some(opt)) =>
coll.dropIndex(indexName, opt.asInstanceOf[DropIndexOptions]).toFuture().asInstanceOf[Future[T]]
case DropIndexByKey(key, None) =>
coll.dropIndex(key).toFuture().asInstanceOf[Future[T]]
case DropIndexByKey(key, Some(opt)) =>
coll.dropIndex(key, opt.asInstanceOf[DropIndexOptions]).toFuture().asInstanceOf[Future[T]]
case DropAllIndexes(None) =>
coll.dropIndexes().toFuture().asInstanceOf[Future[T]]
case DropAllIndexes(Some(opt)) =>
coll.dropIndexes(opt.asInstanceOf[DropIndexOptions]).toFuture().asInstanceOf[Future[T]]
}
}}
Scala与Mongodb实践3-----运算环境的搭建的更多相关文章
- Scala与Mongodb实践4-----数据库操具体应用
目的:在实践3中搭建了运算环境,这里学会如何使用该环境进行具体的运算和相关的排序组合等. 由数据库mongodb操作如find,aggregate等可知它们的返回类型是FindObservable.A ...
- Scala与Mongodb实践2-----图片、日期的存储读取
目的:在IDEA中实现图片.日期等相关的类型在mongodb存储读取 主要是Scala和mongodb里面的类型的转换.Scala里面的数据编码类型和mongodb里面的存储的数据类型各个不同.存在类 ...
- 转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
场景 好的,假设项目数据调研与需求分析已接近尾声,马上进入Coding阶段了,辣么在Coding之前需要干马呢?是的,“统一开发工具.开发环境的搭建与本地测试.测试环境的搭建与测试” - 本文详细记录 ...
- Scala与Mongodb实践1-----mongodbCRUD
目的:如何使用MongoDB之前提供有关Scala驱动程序及其异步API. 1.现有条件 IDEA中的:Scala+sbt+SDK mongodb-scala-driver的网址:http://mon ...
- 使用Scala操作Mongodb
介绍 Scala是一种功能性面向对象语言.它融汇了很多前所未有的特性.而同一时候又执行于JVM之上.随着开发人员对Scala的兴趣日增,以及越来越多的工具支持,无疑Scala语言将成为你手上一件不可缺 ...
- SDP(6):分布式数据库运算环境- Cassandra-Engine
现代信息系统应该是避不开大数据处理的.作为一个通用的系统集成工具也必须具备大数据存储和读取能力.cassandra是一种分布式的数据库,具备了分布式数据库高可用性(high-availability) ...
- Scala对MongoDB的增删改查操作
=========================================== 原文链接: Scala对MongoDB的增删改查操作 转载请注明出处! ==================== ...
- Windows 7上安装配置TensorFlow-GPU运算环境
Windows 7上安装配置TensorFlow-GPU运算环境 1. 概述 在深度学习实践中,对于简单的模型和相对较小的数据集,我们可以使用CPU完成建模过程.例如在MNIST数据集上进行手写数字识 ...
- 实验 2 Scala 编程初级实践
实验 2 Scala 编程初级实践 一.实验目的 1.掌握 Scala 语言的基本语法.数据结构和控制结构: 2.掌握面向对象编程的基础知识,能够编写自定义类和特质: 3.掌握函数式编程的基础知识,能 ...
随机推荐
- PyTorch中view的用法
相当于numpy中resize()的功能,但是用法可能不太一样. 我的理解是: 把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其 ...
- PyTorch官方中文文档:torch.optim 优化器参数
内容预览: step(closure) 进行单次优化 (参数更新). 参数: closure (callable) –...~ 参数: params (iterable) – 待优化参数的iterab ...
- IDEA中安装activiti并使用
1.IDEA中本身不带activiti,需要自己安装下载. 打开IDEA中File列表下的Settings 输入actiBPM,然后点击下面的Search...搜索 点击Install 下载 下载结束 ...
- java基本类型和String之间的转换
String → 基本类型,除了Character外所有的包装类提供parseXxx(String s)静态方法,用于把一个特定的字符串转换成基本类型变量: 基本类型 → String,String ...
- [转]1.2 java web的发展历史
前言 了解java web的发展历史和相关技术的演进历程,非常有助于加深对java web技术的理解和认识. 阅读目录 1.Servlet的出现 2.Jsp的出现 3.倡导了MVC思想的Servlet ...
- Python--day41--threading中的定时器Timer
定时器Timer:定时开启线程 代码示例: #定时开启线程 import time from threading import Timer def func(): print('时间同步') #1-3 ...
- 2019-8-24-win10-uwp-读取文本GBK错误
title author date CreateTime categories win10 uwp 读取文本GBK错误 lindexi 2019-8-24 16:2:27 +0800 2018-2-1 ...
- 【t093】外星密码
Time Limit: 1 second Memory Limit: 128 MB [问题描述] 有了防护伞,并不能完全避免2012的灾难.地球防卫小队决定去求助外星种族的帮助.经过很长时间的努力,小 ...
- 【b703】矩阵取数游戏
Time Limit: 1 second Memory Limit: 50 MB [问题描述] 帅帅经常跟同学玩一个矩阵取数游戏:对于一个给定的n*m的矩阵,矩阵中的每个元素aij均为非负整数.游戏规 ...
- 有趣的一行 Python 代码
https://mp.weixin.qq.com/s/o9rm4tKsJeEWyqQDgVEQiQ https://mp.weixin.qq.com/s/G5F_GaUGI0w-kugOZX145g ...