基于VGGnet的人脸识别系统-ubuntu 系统下的Caffe环境搭建(CPU)
对于caffe的系统一般使用linux系统,当然也有windows版本的caffe,不过如果你一开始使用了windows下面的caffe,后面学习的过程中,会经常遇到各种错误,网上下载的一些源码、模型也往往不能快速的跑起来,因为貌似caffe的官方只提供了linux版本,而且caffe在不断的快速迭代更新中,如果不使用原版的话,后面编译出现什么问题,自己怎么错的,自己都不知道。本篇博文主要讲解快速搭建caffe环境:
电脑系统:ubuntu 14.04
显卡:GTX 850
在ubuntu下要完整的搭建caffe,个人感觉最难的一步就是cuda的安装了,特别是对于双显卡的电脑来说,很容易黑屏、无法登陆图形界面,这个我安装了n久,都没装成功,因为我的电脑笔记本双显卡,每次装完cuda就黑屏,网上的教程一大堆,但都中看不中用,导致我重装了二三十次的系统,最后才成功。这里为了讲caffe的安装,我们先不使用GPU,进行安装测试,因为没有GPU我们依旧可以跑caffe,只是速度比较慢而已。
1、安装caffe所需要的依赖库
命令:
- sudo apt-get install libatlas-base-dev
- sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev
- sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler
这些库要安装挺久的,请耐心等待。
2、下载caffe。
到github上下载caffe:https://github.com/BVLC/caffe。下载完成后,解压caffe源码包。解压后,我们打开文件,可以看到caffe的源码包如下:

3、配置Make.config 文件。caffe文件解压后,文件夹下面有一个Makefile.config.example文件,我们需要对这个文件进行重命名为:Make.config 。也就是去掉后缀example。然后我们打开这个文件,可以看到如下内容:
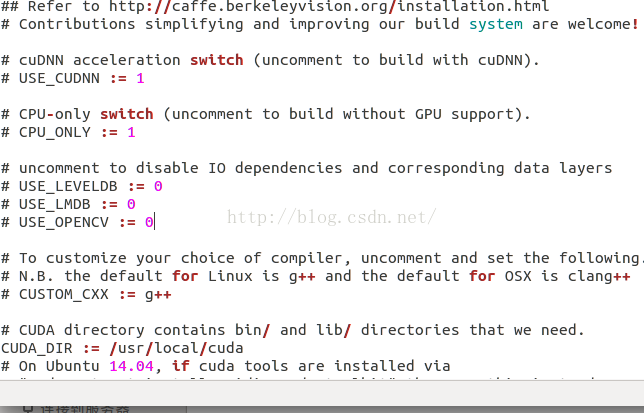
然后我们把:#CPU_ONLY:=1,那一行的注释符号去掉:CPU_ONLY:=1。这是因为我们没有安装CUDA,还不能使用gpu,所以我们把配置改为只使用cpu。
4、编译caffe。
方案一:
(1)在完成Make.config配置后,我们输入命令:
- make all
进行caffe源码编译.这一步有可能遇到如下错误:
- caffe/proto/caffe.pb.h: No such file or directory
如果出现这个错误,那么输入命令:
- protoc src/caffe/proto/caffe.proto --cpp_out=.
- mkdir include/caffe/proto
- mv src/caffe/proto/caffe.pb.h include/caffe/proto
然后在进行make all 就可以了
(2)编译完成后,在安装python接口,输入命令:
- make pycaffe
这个如果不使用python接口,调用caffe模型的话也可以不用安装,不过建议还是搞一下,就一句话的事。完事后,我们会发现caffe源码目录下,多了一个build文件,这个文件下面有个tools,打开这个文件夹:
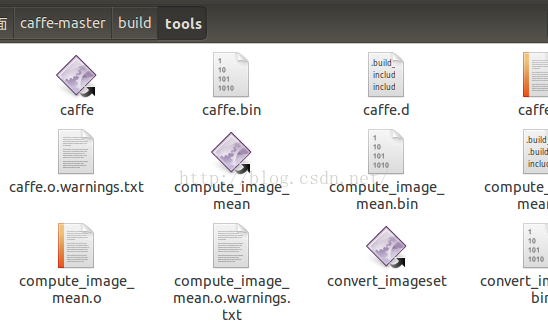
这个文件夹下面的工具可是个好东西啊,以后我们会经常用到这些可执行文件,最常用的就是可执行文件:caffe,我们只要调用这个工具,就可以进行训练。
(3)接着编译test文件夹下面的源码。命令如下:
- make test
- make runtest
采用这种方案一般没问题,不过我在使用c++调用的时候,会使用到链接库:libcaffe.so.1.0.0-rc3,这种方法编译后没有生成这个文件;经过google查找,发现采用cmake编译,才会生成libcaffe.so文件
方案二:直接采用cmake:
- mkdir build
- cd build
- cmake ..
- make all -j8
5、测试阶段
安装完了,自然要测试一下能不能用咯。首先cd到caffe目录,然后输入命令:
- sh data/mnist/get_mnist.sh
- sh examples/mnist/create_mnist.sh
- vim examples/mnist/lenet_solver.prototxt
把lenet_solver.prototxt里面的solver_mode 改为 CPU。因为我们还没装GPU,暂时只使用CPU就好了。
然后我们运行脚本:
- ./examples/mnist/train_lenet.sh
这个时候,如果成功的话,就会开始跑起来:
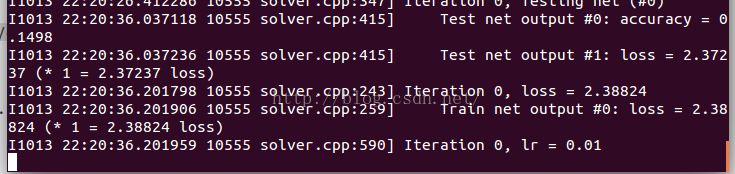
说明:如果在使用caffe、或者编译安装caffe过程中,出现如下错误:
- CXX/LD -o .build_release/tools/convert_imageset.bin
- .build_release/lib/libcaffe.so: undefined reference tocv::imread(cv::String const&, int)'.build_release/lib/libcaffe.so: undefined reference tocv::imencode(cv::String const&, cv::_InputArray const&, std::vector >&, std::vector > const&)'
那么请修改上面的Makefile文件(不是Makefile.config):
- LIBRARIES += glog gflags protobuf leveldb snappy \
- lmdb boost_system hdf5_hl hdf5 m \
- opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs
也就是在libraries后面,加上opencv的相关库文件。
接着就开始caffe搞起吧,推荐个caffe模型网站:https://github.com/BVLC/caffe/wiki/Model-Zoo。本来个人不是很喜欢caffe的,就是因为这个网站吸引了我,这个网站可以搞到好多caffe模型、源码,非常适合于我们学习。
/***************************************************************************************************************************
http://blog.csdn.net/autocyz/article/details/51783857 (2016.6月份的博文,本文没有参考这篇博客,不过感觉写的挺好 贴上连接)
http://www.ithao123.cn/content-1759601.html
caffe是一个简洁高效的深度学习框架,具体介绍可以看这里http://caffe.berkeleyvision.org/,caffe环境配置过程可以参考这里:http://caffe.berkeleyvision.org/installation.html,我在搭建环境时搜集了许多资料,这里整理了一下,介绍一下caffe在无CUDA的环境下如何配置。
1. 安装build-essentials
安装开发所需要的一些基本包
- sudo apt-get install build-essential
如果出现essential包不可用的情况,可以执行下列命令解决:
- sudo apt-get update
2. 安装ATLAS for Ubuntu
执行命令:
- sudo apt-get install libatlas-base-dev
注:ATLAS, MKL,或OpenBLAS都可以,我这里选择安装ATLAS
3. 安装OpenCV
下载该脚本,解压".zip"文件,解压命令:
安装2.4.10 (推荐)
- 下载安装脚本 https://github.com/bearpaw/Install-OpenCV
- 进入目录
Install-OpenCV/Ubuntu/2.4 - 执行脚本
sh sudo ./opencv2_4_10.sh
安装2.4.9(不推荐)
- unzip /home/liuxiabing/下载/Install-OpenCV-master.zip
进入Ubuntu/2.4 目录, 给所有shell脚本加上可执行权限:
- chmod +x *.sh
然后安装最新版本 (当前为2.4.9):
- sudo ./opencv2_4_9.sh
4. 安装其他依赖项
Ubuntu14.04用户执行
- sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler
使用其它系统的可以参考官网介绍。
5. 编译Caffe
完成了上述环境的配置,就可以编译Caffe了!
下载caffe安装包,下载地址:https://github.com/BVLC/caffe
解压该压缩包,解压缩命令:
- sudo unzip /home/liuxiabing/下载/caffe-master.zip
注:如果解压位置出错了,可以使用以下命令删除该目录及所有的子目录:
- sudo rm -rf caffe-master
进入caffe根目录, 首先复制一份Makefile.config,命令:
- cp Makefile.config.example Makefile.config
然后修改里面的内容,主要需要修改的参数包括:
1.修改文件权限 规则:chmod [who] [+ | - | =] [mode] 文件名¼
使用 chmod g+w Makefile.config
2.打开文件进行修改
使用 sudo vim Makefile.config
按“i”键开始修改,修改结束后按esc键,键入“:wq”保存并退出
修改 将# CPU_ONLY = 1前面的#去掉 并按“tab”键,(默认从tab处执行)
CPU_ONLY 是否只使用CPU模式,由于我没有NVIDIA的显卡,就没有安装CUDA,因此需要打开这个选项。
其余的一些配置可以根据需要修改:
BLAS (使用intel mkl还是OpenBLAS)
MATLAB_DIR 如果需要使用MATLAB wrapper的同学需要指定matlab的安装路径, 如我的路径为 /usr/local/MATLAB/R2013b (注意该目录下需要包含bin文件夹,bin文件夹里应该包含mex二进制程序)
DEBUG 是否使用debug模式,打开此选项则可以在eclipse或者NSight中debug程序
完成上述设置后,开始编译:
- sudo make all -j4
- sudo make test
- sudo make runtest
注意:-j4 是指使用几个线程来同时编译,可以加快速度,j后面的数字可以根据CPU core的个数来决定,如果CPU是4核的,则参数为-j4,也可以不添加这个参数,直接使用“make all”,这样速度可能会慢一点儿。
6.使用MNIST数据集进行测试
Caffe默认情况会安装在$CAFFE_ROOT,就是解压到的那个目录,例如:$ home/username/caffe-master,所以下面的工作,
默认已经切换到了该工作目录。下面的工作主要是测试Caffe是否工作正常,不做详细评估。具体设置请参考官网:
http://caffe.berkeleyvision.org/gathered/examples/mnist.html
(1)数据预处理
可以用下载好的数据集,也可以重新下载,直接下载的具体操作如下:
- $ cd data/mnist
- $ sudo sh ./get_mnist.sh
(2)重建LDB文件,就是处理二进制数据集为Caffe识别的数据集,以后所有的数据,包括jpe文件都要处理成这个格式,执行命令如下:
- $ sudo sh ./examples/mnist/create_mnist.sh
生成mnist-train-leveldb/ 和 mnist-test-leveldb/文件夹,这里包含了LDB格式的数据集
注:新版caffe都需要从根目录上执行,如果使用下列命令执行:
- # cd examples/mnist
- # sudo sh ./create_mnist.sh
可能会遇到这个错误:./create_mnist.sh: 16: ./create_mnist.sh: build/examples/mnist/convert_mnist_data.bin: not found
(3)训练mnist
如果没有GPU,只有CPU的话,需要先修改examples/mnist目录下lenet_solver.prototxt文件,将solver_mode:GPU改为 solver_mode:CPU,修改后结果如下所示:
- # solver mode: CPU or GPU
- solver_mode: CPU
修改时可以使用vi编辑命令(ubuntu14.0.4下也可以直接双击打开,修改后保存即可),如果是只读文件,不能编辑,可以用sudo命令,比如:
- sudo vi lenet_solver.prototxt
先进入命令模式,使用a进入编辑模式,修改完之后,使用esc退出编辑模式,进入末行模式,再使用“:wq”保存修改并退出(“:q!”为退出但不保存修改)
修改完成后,再在根目录下(即/caffe-master目录)执行下面的命令进行训练:
- $ sudo sh ./examples/mnist/train_lenet.sh
至此,Caffe安装的所有步骤完结。注:如果进入到mnist目录下执行这个sh命令,会出现错误。即这样操作
- cd ./examples/mnist
- sudo sh ./train_lenet.sh
会有一个caffe-master/.build_release/tool/caffe找不到或不存在的错误。
7.使用MNIST数据集进行测试
- touch test_lenet.sh #生成.sh文件
- sudo vim test_lenet.sh #进入.sh文件键入内容
- #键入的内容为
- #!/usr/bin/env sh
- "空行"
- ./build/tools/caffe test --model=examples/mnist/lenet_train_test.prototxt --weights=examples/mnist/lenet_iter_10000.caffemodel -iterations 100
备注:因为没有用GPU所以官网指导文档中的"gpu 0"这部分参数就没有添加进去
保存.sh文件 按ESC键 然后键入:wq
 (因为编辑器的问题,自动换行了,所以这里插入了图片)
(因为编辑器的问题,自动换行了,所以这里插入了图片)- sudo sh ./examples/mnist/test_lenet.sh
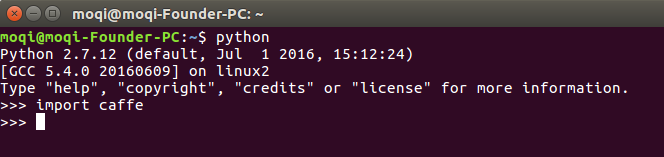
最后放两张测试成功的图片
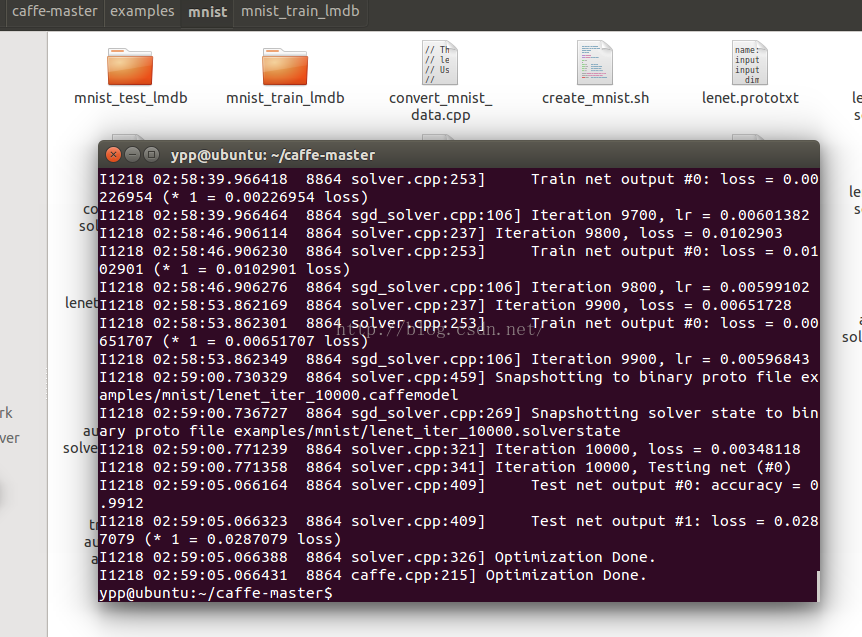


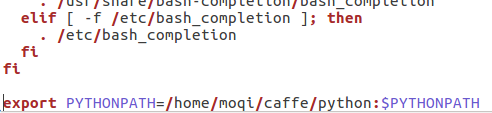
- # add library path
- LD_LIBRARY_PATH=your_anaconda_path/lib:$LD_LIBRARY_PATH
- export LD_LIBRARY_PATH
(4)安装pip和python-dev ,执行
- sudo apt-get install python-dev python-pip
(5)cd到caffe-master/python目录下,执行
- for req in $(cat requirements.txt); do sudo pip install $req; done
(6)cd到caffe-master目录下,编译执行
- sudo make pycaffe


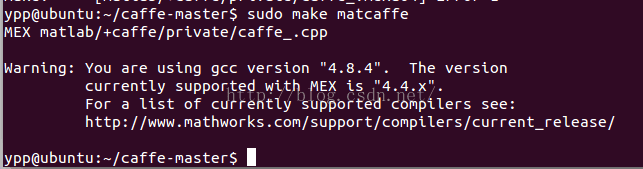
- sudo make matcaffe
一、检查自己电脑是否具有GPU





基于VGGnet的人脸识别系统-ubuntu 系统下的Caffe环境搭建(CPU)的更多相关文章
- 【嵌入式硬件Esp32】Ubuntu 1804下ESP32交叉编译环境搭建
一.ESP32概述EPS32是乐鑫最新推出的集成2.4GWi-Fi和蓝牙双模的单芯片方案,采用台积电(TSMC)超低功耗的40nm工艺,拥有最佳的功耗性能.射频性能.稳定性.通用性和可靠性,适用于多种 ...
- Vmware Ubuntu 虚拟机下Android开发环境搭建
概况: 1.安装jdk: 2.安装adt-bundle: 1.安装jdk 先下载linux下的jdk,我下的是 jdk-7u13-linux-i586 :然后解压,为方便,建个文件夹--/home/x ...
- 践行初心|方正璞华爱心捐赠人脸识别测温系统WelComID
近日,方正璞华向金鸡湖社区卫生服务中心捐赠了人脸识别测温系统.该设备集人员识别.体温检测等功能于一体,在人员进出的时候完成体温的检测,从而判断是否有异常人员等问题,有效节省人力成本.减少人员接触风险, ...
- 基于MATLAB的人脸识别算法的研究
基于MATLAB的人脸识别算法的研究 作者:lee神 现如今机器视觉越来越盛行,从智能交通系统的车辆识别,车牌识别到交通标牌的识别:从智能手机的人脸识别的性别识别:如今无人驾驶汽车更是应用了大量的机器 ...
- 基于 OpenCV 的人脸识别
基于 OpenCV 的人脸识别 一点背景知识 OpenCV 是一个开源的计算机视觉和机器学习库.它包含成千上万优化过的算法,为各种计算机视觉应用提供了一个通用工具包.根据这个项目的关于页面,OpenC ...
- 基于 HTML5 的人脸识别技术
基于 HTML5 的人脸识别技术 https://github.com/auduno/headtrackr/
- 基于node.js人脸识别之人脸对比
基于node.js人脸识别之人脸对比 Node.js简介 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. Node.js 使用了一个事件驱动.非阻塞式 I/O ...
- 【计算机视觉】基于OpenCV的人脸识别
一点背景知识 OpenCV 是一个开源的计算机视觉和机器学习库.它包含成千上万优化过的算法,为各种计算机视觉应用提供了一个通用工具包.根据这个项目的关于页面,OpenCV 已被广泛运用在各种项目上,从 ...
- java基于OpenCV的人脸识别
基于Java简单的人脸和人眼识别程序 使用这个程序之前必须先安装配置OpenCV详细教程见:https://www.cnblogs.com/prodigal-son/p/12768948.html 注 ...
随机推荐
- eclipse如何实现智能提示功能
一直时候用idea很久没有使用eclipse了,idead的ctrl+鼠标滚轮是可以调节字体大小,这项功能是我的最爱. 早就忘记eclipse的智能助手设置,今天翻下以前的笔记,觉得还是做个博客方便今 ...
- NX二次开发-NX11创建表达式组NXOpen::ExpressionGroup
NX11+VS2013 #include <uf.h> #include <uf_modl.h> #include <uf_part.h> #include < ...
- Flutter介绍
1. flutter简介 Flutter是Google使用Dart语言开发的移动应用开发框架,使用一套Dart代码就能快速构建高性能.高保真的ios和Android应用程序, 并且在排版.图标.滚动. ...
- 测试Tensorflow-GPU的例子
import tensorflow as tf # import os # os.environ['TF_CPP_MIN_LOG_LEVEL']='2' a = tf.placeholder(tf.i ...
- python学习5—一些关于基本数据结构的练习题
python学习5—一些关于基本数据结构的练习题 # 1. use _ to connect entries in a list # if there are no numbers in list l ...
- 最短路(sp
#include<stdio.h> #include<iostream> #include<queue> using namespace std; #define ...
- 【Java】Appache Flume 中文介绍
Flume 是什么 Apache Flume是一个高可靠.高可用的分布式的海量日志收集.聚合.传输系统.它能够从不同的日志源採集数据并集中存储. Flume也算是Hadoop生态系 ...
- Xpath-Assertion断言
- Js_案例(电灯)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Jmeter压测快速体验
前言 最近在看neo4j相关的官网文档以及一些调优参数,同时也学了下Jmeter,为了测试下neo4j服务的性能,虽然不是专业搞测试的,但是我觉得每个优秀的开发者都应该学会主动压测自己服务和代码的性能 ...