Java并发机制的底层实现原理之volatile应用,初学者误看!
Java并发机制的底层实现原理之volatile应用,初学者误看!的更多相关文章
- 《Java并发编程的艺术》Java并发机制的底层实现原理(二)
Java并发机制的底层实现原理 1.volatile volatile相当于轻量级的synchronized,在并发编程中保证数据的可见性,使用 valotile 修饰的变量,其内存模型会增加一个 L ...
- 【java并发编程艺术学习】(三)第二章 java并发机制的底层实现原理 学习记录(一) volatile
章节介绍 这一章节主要学习java并发机制的底层实现原理.主要学习volatile.synchronized和原子操作的实现原理.Java中的大部分容器和框架都依赖于此. Java代码 ==经过编译= ...
- Java 并发系列之二:java 并发机制的底层实现原理
1. 处理器实现原子操作 2. volatile /** 补充: 主要作用:内存可见性,是变量在多个线程中可见,修饰变量,解决一写多读的问题. 轻量级的synchronized,不会造成阻塞.性能比s ...
- 《Java并发编程的艺术》读书笔记:二、Java并发机制的底层实现原理
二.Java并发机制底层实现原理 这里是我的<Java并发编程的艺术>读书笔记的第二篇,对前文有兴趣的朋友可以去这里看第一篇:一.并发编程的目的与挑战 有兴趣讨论的朋友可以给我留言! 1. ...
- (第二章)Java并发机制的底层实现原理
一.概述 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. ...
- Java并发机制和底层实现原理
Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码转化为汇编指令在CPU上执行.Java中的并发机制依赖于JVM的实现和CPU的指令. Java语言规范第三版中 ...
- 并发艺术--java并发机制的底层实现原理
前言 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. 一 ...
- java并发机制的底层实现原理
volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的"可见性".可见性是说当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值. vola ...
- 【java并发编程艺术学习】(五)第二章 java并发机制的底层实现原理 学习记录(三) 原子操作的实现原理学习
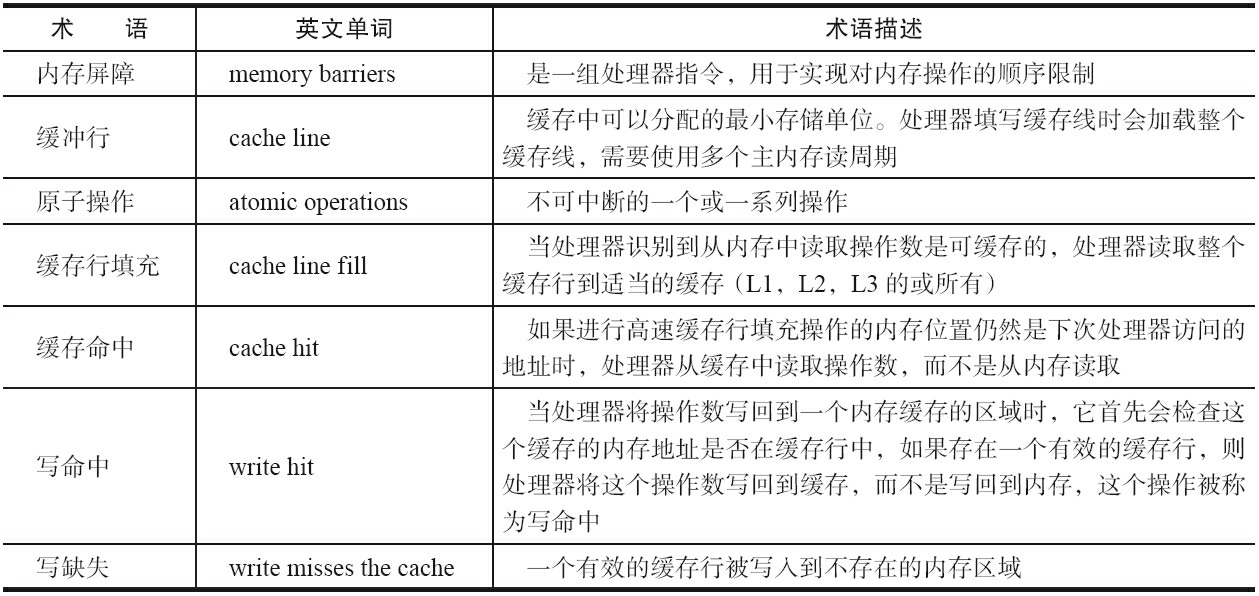
章节介绍 主要包括 术语定义.处理器如何实现原子操作.Java如何实现原子操作: 原子(atomic)本意是 不能再进一步分割的最小粒子,“原子操作” 意为 不可被中断的一个或一系列操作. 术语定义 ...
随机推荐
- Servlet会话跟踪和Cookies及HttpSession会话
会话只是指一段指定的时间间隔. 会话跟踪是维护用户状态(数据)的一种方式.它也被称为servlet中的会话管理. Http协议是一个无状态的,所以我们需要使用会话跟踪技术来维护用户状态. 每次用户请求 ...
- (四)IO流之InputStream和OutputStream
InputStream:定义了字节输入流的抽象类 OutputStream:定义了字节输出流的抽象类;该类所有方法返回void值 FileInputStream:继承InputStream FileO ...
- 【JZOJ4889】【NOIP2016提高A组集训第14场11.12】最长公共回文子序列
题目描述 YJC最近在学习字符串的有关知识.今天,他遇到了这么一个概念:最长公共回文子序列.一个序列S,如果S是回文的且分别是两个或多个已知序列的子序列,且是所有符合此条件序列中最长的,则 S 称为已 ...
- 【JZOJ4883】【NOIP2016提高A组集训第12场11.10】灵知的太阳信仰
题目描述 在炽热的核熔炉中,居住着一位少女,名为灵乌路空. 据说,从来没有人敢踏入过那个熔炉,因为人们畏缩于空所持有的力量--核能. 核焰,可融真金. 咳咳. 每次核融的时候,空都会选取一些原子,排成 ...
- 服务网关zuul----zuul中的动态刷新路由配置
Spring Cloud实战小贴士:Zuul处理Cookie和重定向 所以解决该问题的思路也很简单,我们只需要通过设置sensitiveHeaders即可,设置方法分为两种: 全局设置: zuul.s ...
- Myeclipse运行提示错误: 找不到或无法加载主类 test.test1 终极解决办法
前提是代码没有问题 简单粗暴的解决办法: 重启电脑 解决办法2: 1.在控制台中点开“Problems”,查看里面的错误.如果是多个项目,可以将其他项目暂时关闭. 根据错误进行处理. 2.把项目cle ...
- 设置PHP最长运行时间
通常来说,默认的PHP程序最大运行时间是30s,如果你的程序运行超过这个时间限制,那么会有类似Maximum execution time of 30 seconds exceeded的报错. 有几种 ...
- Android 高仿微信支付键盘
现在很多app的支付.输入密码功能,都已经开始使用自定义数字键盘,不仅更加方便.其效果着实精致. 下面带着大家学习下,如何高仿微信的数字键盘,可以拿来直接用在自身的项目中. 先看下效果图: 1. 自定 ...
- 基于Qt框架的GUI控制台——qtconsole
- oracle函数 add_months(d1,n1)
[功能]:返回在日期d1基础上再加n1个月后新的日期. [参数]:d1,日期型,n1数字型 [返回]:日期