Python爬虫连载7-cookie的保存与读取、SSL讲解
一、cookie的保存与读取
1.cookie的保存-FileCookie.Jar
from urllib import request,parse
from http import cookiejar
#创建cookiejar实例
filename = "cookie.txt"
cookie = cookiejar.MozillaCookieJar(filename)
#生成cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
#创建http请求管理器
http_handler = request.HTTPHandler()
#生成https管理器
https_handler = request.HTTPHandler()
#创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
"""
负责初次登录
需要输入用户名密码
:return:
"""
url = "http://www.renren.com/PLogin.do"
data = {
"email":"1215217867@qq.com",
"password":""
}
#把数据进行编码
data = parse.urlencode(data)
#创建一个请求对象
req = request.Request(url,data=data.encode())
#使用opener发起请求
rep = opener.open(req)
#保存cookie到文件
#ignore_discard表示及时cookie将要被丢弃也要保存下来
#ignore_expire表示如果该文件中cookie即使已经过期,保存
cookie.save(ignore_discard=True,ignore_expires=True)
def getHomePage():
url = "http://www.renren.com/965187997/profile"
#如果已经执行了login函数,则opener自动已经包含相应的cookie值
rsp = opener.open(url)
html = rsp.read().decode()
with open("rsp.html","w") as f:
f.write(html)
if __name__ == "__main__":
"""
执行完login之后,会得到授权之后的cookie
我们尝试把cookie打印出来
"""
login()
getHomePage()
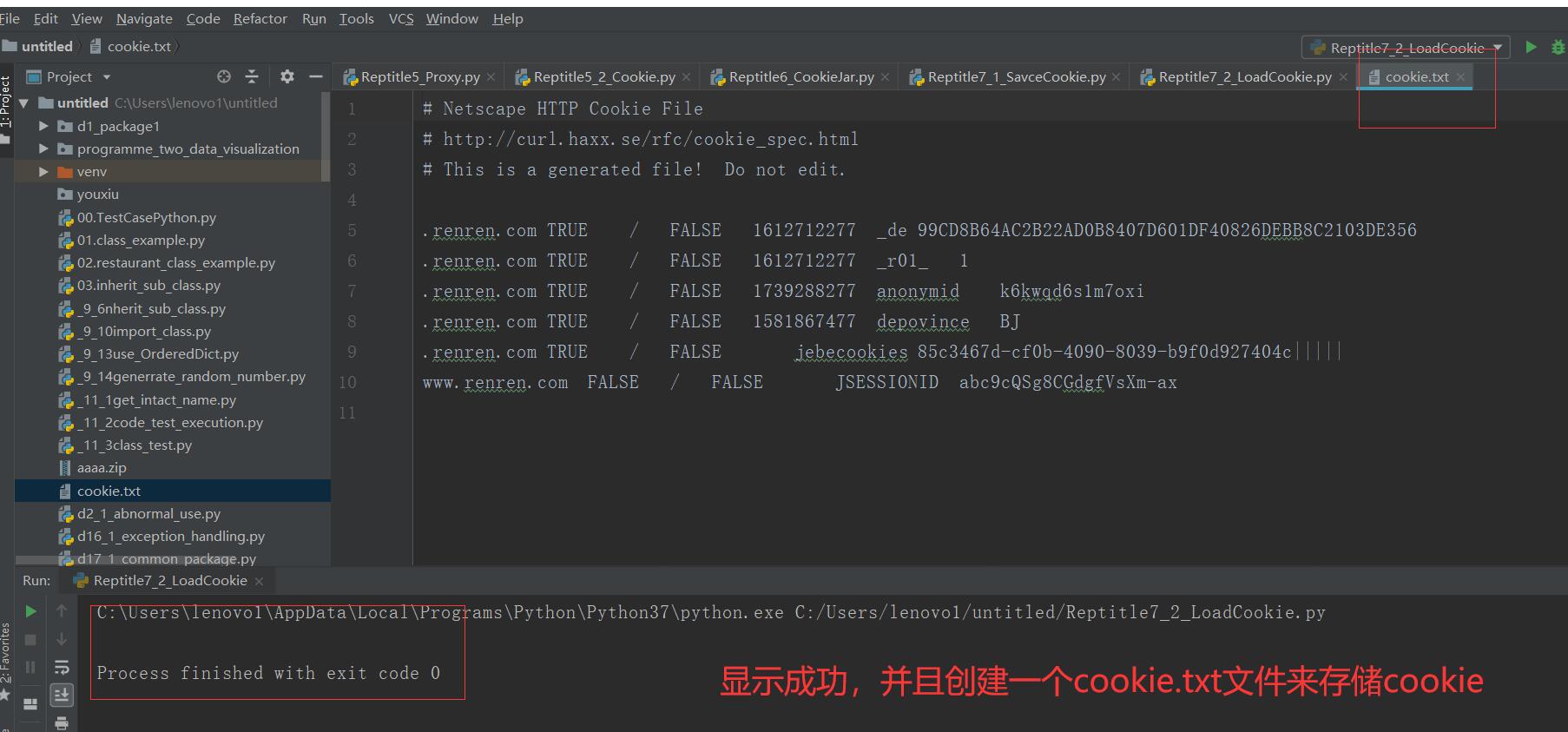
2.cookie的读取
from urllib import request,parse
from http import cookiejar
#创建cookiejar实例
cookie = cookiejar.MozillaCookieJar()
cookie.load("cookie.txt",ignore_discard=True,ignore_expires=True)
#生成cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
#创建http请求管理器
http_handler = request.HTTPHandler()
#生成https管理器
https_handler = request.HTTPHandler()
#创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
"""
负责初次登录
需要输入用户名密码
:return:
"""
url = "http://www.renren.com/PLogin.do"
data = {
"email":"1215217867@qq.com",
"password":""
}
#把数据进行编码
data = parse.urlencode(data)
#创建一个请求对象
req = request.Request(url,data=data.encode())
#使用opener发起请求
rep = opener.open(req)
#保存cookie到文件
#ignore_discard表示及时cookie将要被丢弃也要保存下来
#ignore_expire表示如果该文件中cookie即使已经过期,保存
cookie.save(ignore_discard=True,ignore_expires=True)
def getHomePage():
url = "http://www.renren.com/965187997/profile"
#如果已经执行了login函数,则opener自动已经包含相应的cookie值
rsp = opener.open(url)
html = rsp.read().decode()
with open("rsp.html","w") as f:
f.write(html)
if __name__ == "__main__":
"""
执行完login之后,会得到授权之后的cookie
我们尝试把cookie打印出来
"""
# login()
getHomePage()
改代码读取了保存的cookie文件,并且访问网页成功。
二、SSL
1.什么是SSL
(1)SSL证书就是指遵守SSL安全套阶层协议的服务器数字证书(SercureSocketLayer)
(2)该证书是由美国网景公司开发
(3)CA(CertifacateAuthority)是数字证书认证中心,是发放、管理、废除数字证书的收信人的第三方机构。
(4)遇到不信任的SSL证书,可以用代码进行忽略掉
from urllib import request #导入python ssl处理模块 import ssl #利用非认证上下文环境替换认证的下文环境 ssl._create_default_https_context = ssl._create_unverified_context url = "https://www.12306.cn/mormhweb/" rsp = request.urlopen(url) html = rsp.read().decode() print(html)
三、源码
Reptitle7_1_SaveCookie.py
Reptitle7_2_LoadCookie.py
Reptitle7_3_SSLAnalysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle7_1_SaveCookie.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle7_2_LoadCookie.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle7_3_SSLAnalysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

Python爬虫连载7-cookie的保存与读取、SSL讲解的更多相关文章
- Python爬虫入门:Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- 芝麻HTTP:Python爬虫入门之Cookie的使用
为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓 ...
- Python爬虫连载1-urllib.request和chardet包使用方式
一.参考资料 1.<Python网络数据采集>图灵工业出版社 2.<精通Python爬虫框架Scrapy>人民邮电出版社 3.[Scrapy官方教程](http://scrap ...
- Python爬虫连载5-Proxy、Cookie解析
一.ProxyHandler处理(代理服务器) 1.使用代理IP,是爬虫的常用手段 2.获取代理服务器的地址: www.xicidaili.com www.goubanjia.com 3.代理用来隐藏 ...
- Python爬虫基础之Cookie
一.Cookie会话 简单地说,cookie就是存储在用户浏览器中的一小段文本文件.Cookies是纯文本形式,它们不包含任何可执行代码.一个Web页面或服务器告之浏览器来将这些信息存储并且基于一系列 ...
- Python爬虫连载9-JS加密之“盐”、ajax请求
一.JS加密之“盐” 1.salt属性“盐":多用于密码学,比如我们的银行卡是六位密码,但是实际上在银行的系统里,我们输入密码后,会给原始的密码添加若干字符,形成更加难以破解的密码.这个过 ...
- Python爬虫连载6-cookie深入使用实例化实现自动登录
一.使用cookie登录 1.直接把cookie复制下去,然后手动放到请求头 2.http模块包含一些关于cookie的模块,通过他们我们可以自动使用cookie (1)cookieJar 管理存储c ...
随机推荐
- Scrum简介
1. 什么是Scrum Scrum是一种轻量级的框架,适合于小型的.结合紧密的团队开发复杂的产品.Scrum是二十世纪后期一些软件工程师协同努力的脑力劳动的成果,现已成为技术领域最具魅力的方法.但Sc ...
- 对one hot 编码的理解,sklearn. preprocessing.OneHotEncoder()如何进行fit()的?
查阅了很多资料,逐渐知道了one hot 的编码,但是始终没理解sklearn. preprocessing.OneHotEncoder()如何进行fit()的?自己琢磨了一下,后来终于明白是怎么回事 ...
- 将内裤穿在外面的男人(mysql)
superman 的好处是可以为所欲为,不仅可以修改自己的密码,还能给别人授权,修改别人的密码. 1.修改自己 的密码 首先要先登录mysql, 然后: mysqladmin -u root ...
- CVE-2019-0708 远程桌面代码执行漏洞复现
0x01 首先是靶机,这里的靶机是使用清水表哥提供的win7sp1的系统 漏洞环境使用VM安装Windows7 SP1模拟受害机Windows7 SP1下载链接:ed2k://|file|cn_win ...
- POJ1273【网络流】
Drainage Ditches Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 91824 Accepted ...
- 远程执行本地脚本_linux
一.远程执行脚本 1.免机器指纹确认(无需填写yes/no) ssh -o StrictHostKeyChecking=no root@192.168.108.78 2.远程执行本地脚本 ssh -o ...
- Zabbix使用手册
https://blog.csdn.net/qq_40025218/article/details/81778754
- asp.net core 发布到linux下Docker
1.linux Docker 安装 内核升级:https://www.cnblogs.com/zksfyz/p/7919425.html 安装: https://www.runoob.com/do ...
- Laravel通过用户名和密码查询
一.如果要检查要验证的用户数据是否正确,可以使用: if (Auth::validate($credentials)) { // } 二.但是如果您想通过用户和密码从数据库中获取用户,您可以使用: / ...
- mac或windows下Navicat Premium安装
找了很多地址都乱七八糟的说明一通还没啥用,好不容易找到一个靠谱的,记录一下,也方便一下和我一样苦苦寻找的人,亲测有用 https://www.52pojie.cn/thread-727433-1-1. ...