SQL JOIN 的解析
1、SQL语句结构
select distinct < select_list >
from < left_table > < join_type >
join < right_table >
on < join_condition >
where < where_condition >
group by < group_by_list >
having < having_condition >
order by < order_by_condition >
limit < limit_number >
2、7种Join方式及实例
实验脚本:
drop table IF EXISTS shuzi ;
create table shuzi (id tinyint,note varchar(20));
insert into shuzi values (1,'一'),(2,'二'),(3,'三'),(4,'四'),(5,'五'),(6,'六'),(7,'七'),(8,'八'),(9,'九'),(10,'十');
select * from shuzi;
drop table IF EXISTS qianshu ;
create table qianshu (id int,des varchar(20));
insert into qianshu values (1,'壹'),(2,'贰'),(4,'肆'),(5,'伍'),(6,'陆'),(10,'拾'),(100,'佰'),(1000,'仟'),(10000,'万');
select * from qianshu;

- 左连接,左表的全部,右表不满足的列补空
select a.id,a.note,b.id,b.des from shuzi a left join qianshu b on a.id=b.id order by a.id;

- 右连接,右表的全部,左表不满足的列补空
select a.id,a.note,b.id,b.des from shuzi a right join qianshu b on a.id=b.id order by b.id;
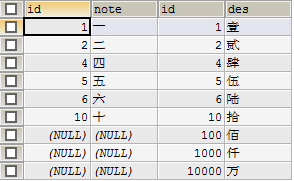
- 内连接,只输出左右表均存在的记录(默认from a,b方式)
SELECT a.id,a.note,b.id,b.des FROM shuzi a INNER JOIN qianshu b ON a.id=b.id ORDER BY b.id;

- 左连接,只保留左表特有数据(差集)
select a.id,a.note,b.id,b.des from shuzi a left join qianshu b on a.id=b.id where b.id is null order by a.id

- 右连接,只保留右表特有数据(差集)
SELECT a.id,a.note,b.id,b.des FROM shuzi a RIGHT JOIN qianshu b ON a.id=b.id WHERE a.id IS NULL ORDER BY b.id;

- 全外连接,获取左右表的所有记录,各自没有时补空
mysql不支持full outer join,要实现全外连接可以通过合并左,右外连接结果集实现
select a.id,a.note,b.id,b.des from shuzi a left join qianshu b on a.id=b.id
union
select a.id,a.note,b.id,b.des from shuzi a right join qianshu b on a.id=b.id
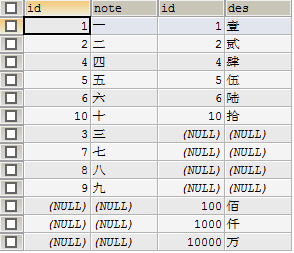
- 获取两表连接交集的补集(最后一个)
SELECT * FROM (
SELECT a.id aid,a.note,b.id bid,b.des FROM shuzi a LEFT JOIN qianshu b ON a.id=b.id
UNION
SELECT a.id aid,a.note,b.id bid,b.des FROM shuzi a RIGHT JOIN qianshu b ON a.id=b.id) v_a
WHERE aid IS NULL OR bid IS NULL;
SQL JOIN
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
Join 和 Key
有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
请看 "Persons" 表:
| Id_P | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
请注意,"Id_P" 列是 Persons 表中的的主键。这意味着没有两行能够拥有相同的 Id_P。即使两个人的姓名完全相同,Id_P 也可以区分他们。
接下来请看 "Orders" 表:
| Id_O | OrderNo | Id_P |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 1 |
| 4 | 24562 | 1 |
| 5 | 34764 | 65 |
请注意,"Id_O" 列是 Orders 表中的的主键,同时,"Orders" 表中的 "Id_P" 列用于引用 "Persons" 表中的人,而无需使用他们的确切姓名。
请留意,"Id_P" 列把上面的两个表联系了起来。
引用两个表
我们可以通过引用两个表的方式,从两个表中获取数据:
谁订购了产品,并且他们订购了什么产品?
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons, Orders
WHERE Persons.Id_P = Orders.Id_P
结果集:
| LastName | FirstName | OrderNo |
|---|---|---|
| Adams | John | 22456 |
| Adams | John | 24562 |
| Carter | Thomas | 77895 |
| Carter | Thomas | 44678 |
SQL JOIN - 使用 Join
除了上面的方法,我们也可以使用关键词 JOIN 来从两个表中获取数据。
如果我们希望列出所有人的定购,可以使用下面的 SELECT 语句:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
INNER JOIN Orders
ON Persons.Id_P = Orders.Id_P
ORDER BY Persons.LastName
结果集:
| LastName | FirstName | OrderNo |
|---|---|---|
| Adams | John | 22456 |
| Adams | John | 24562 |
| Carter | Thomas | 77895 |
| Carter | Thomas | 44678 |
不同的 SQL JOIN
除了我们在上面的例子中使用的 INNER JOIN(内连接),我们还可以使用其他几种连接。
下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。
- JOIN: 如果表中有至少一个匹配,则返回行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
SQL JOIN 的解析的更多相关文章
- SQL Server 深入解析索引存储(下)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- Oracle sql执行计划解析
Oracle sql执行计划解析 https://blog.csdn.net/xybelieve1990/article/details/50562963 Oracle优化器 Oracle的优化器共有 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Oracle SQL的硬解析和软解析
我们都知道在Oracle中每条SQL语句在执行之前都需要经过解析,这里面又分为软解析和硬解析.在Oracle中存在两种类型的SQL语句,一类为 DDL语句(数据定义语言),他们是从来不会共享使用的,也 ...
- ORACLE的SQL JOIN方式小结
在ORACLE数据库中,表与表之间的SQL JOIN方式有多种(不仅表与表,还可以表与视图.物化视图等联结),官方的解释如下所示 A join is a query that combines row ...
- SQL JOIN\SQL INNER JOIN 关键字\SQL LEFT JOIN 关键字\SQL RIGHT JOIN 关键字\SQL FULL JOIN 关键字
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据. Join 和 Key 有时为了得到完整的结果,我们需要从两个或更多的表中获取结果.我们就需要执行 join. 数据库中的表 ...
- 转:画图解释 SQL join 语句
画图解释 SQL join 语句 我认为 Ligaya Turmelle 的关于SQL联合(join)语句的帖子对于新手开发者来说是份很好的材料.SQL 联合语句好像是基于集合的,用韦恩图来解释咋一看 ...
随机推荐
- Docker快速上手之部署SpringBoot项目
Docker是基于Go语言实现的云开源项目. Docker的主要目标是“Build,Ship and Run Any App,Anywhere”,也就是通过对应用组件的封装.分发.部署.运行等生命周期 ...
- ubuntu系统下安装pip3及第三方库的安装
ubuntu系统下会自带python2.x和python3.x坏境,不需要我们去安装.并且ubuntu系统下还会自动帮助我们安装python2.x坏境下的pip安装工具, 但是没有python3.x坏 ...
- VS2017/19 在更新之后,.net core项目出一个500的神奇错误
先说症状: VS 更新升级之后,如果用的是 .net core 的项目的时候,当vs升级时,.net core的sdk或者runtime有跟着升级的话,项目发布之后,覆盖dll到服务器时,会出现这个错 ...
- cmd 重定向
关于cmd 命令的重定向输出 2>&1 mycommand >mylog.txt 2>&1 应该是最经典的用法了. 命令的结果可以通过" %> &qu ...
- Oracle笔记(1)--emp表查询(1)
(1)截取函数--TRUNC() 的用法 SELECT TRUNC(789.652) 截取小数, TRUNC(789.652,2) 截取两位小数, TRUNC(789.652,-2) 取整 FROM ...
- 【Pycharm使用者必看】自定义【光标快速定位到行尾】的按键
1.问题描述 使用Pycharm写代码时,有很多比较方便的快捷键,比如:Shift+Enter快速切换到下一行, 但每次切换到多个括号外或者想移动到行尾,就必须按 End 键或者鼠标点击, 这样操作幅 ...
- React+Echarts简单的封装套路
今天我们来介绍一下React中,对Echarts的一个简单的封装. 首先在我们的React项目中,想使用Echart包,首先需要先安装它,安装代码如下,任选一个就可以 cnpm install ech ...
- Altium Designer打印多块PCB到热转印纸上、拼板发给工厂
接下来介绍的方法的优势有: 节省电脑性能(来自不同PCB文件的图案被放置时只在第1块会卡顿一小会儿,之后不再卡顿) 便于排版(拖放图案时绝不会改变图案内容,拖放图案时鼠标拖住的矩形框的尺寸与图案的尺寸 ...
- 如何在git搭建自己博客
1.安装Node.js和配置好Node.js环境,打开cmd命令行输入:node v.2.安装Git和配置好Git环境,打开cmd命令行输入:git --version.3.Github账户注册和新建 ...
- NCE L3
单词 课文