java并发系列(八)-----java异步编程
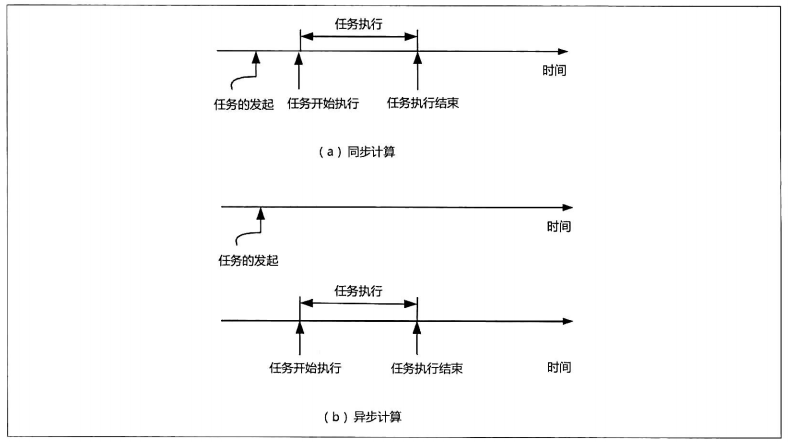
同步计算与异步计算
从多个任务的角度来看,任务是可以串行执行的,也可以是并发执行的。从单个任务的角度来看,任务的执行方式可以是同步的,也可以是异步的。
Runnable、Callable、FutureTask
1、Runnable
先说一下java.lang.Runnable吧,它是一个接口,在它里面只声明了一个run()方法:
public interface Runnable {
public abstract void run();
}
由于run()方法返回值为void类型,所以在执行完任务之后无法返回任何结果。
2、Callable
Callable位于java.util.concurrent包下,它也是一个接口,在它里面也只声明了一个方法,只不过这个方法叫做call():
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
可以看到,这是一个泛型接口,call()函数返回的类型就是传递进来的V类型。
那么怎么使用Callable呢?一般情况下是配合ExecutorService来使用的,在ExecutorService接口中声明了若干个submit方法的重载版本:
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
3、Future
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。
Future类位于java.util.concurrent包下,它是一个接口:
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
在Future接口中声明了5个方法,下面依次解释每个方法的作用:
- cancel方法用来取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。参数mayInterruptIfRunning表示是否允许取消正在执行却没有执行完毕的任务,如果设置true,则表示可以取消正在执行过程中的任务。如果任务已经完成,则无论mayInterruptIfRunning为true还是false,此方法肯定返回false,即如果取消已经完成的任务会返回false;如果任务正在执行,若mayInterruptIfRunning设置为true,则返回true,若mayInterruptIfRunning设置为false,则返回false;如果任务还没有执行,则无论mayInterruptIfRunning为true还是false,肯定返回true。
- isCancelled方法表示任务是否被取消成功,如果在任务正常完成前被取消成功,则返回 true。
- isDone方法表示任务是否已经完成,若任务完成,则返回true;
- get()方法用来获取执行结果,这个方法会产生阻塞,会一直等到任务执行完毕才返回;
- get(long timeout, TimeUnit unit)用来获取执行结果,如果在指定时间内,还没获取到结果,就直接返回null。
也就是说Future提供了三种功能:
- 1)判断任务是否完成;
- 2)能够中断任务;
- 3)能够获取任务执行结果。
因为Future只是一个接口,所以是无法直接用来创建对象使用的,因此就有了下面的FutureTask。
4、FutureTask
我们先来看一下FutureTask的实现:
public class FutureTask<V> implements RunnableFuture<V>
FutureTask类实现了RunnableFuture接口,我们看一下RunnableFuture接口的实现:
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
可以看出RunnableFuture继承了Runnable接口和Future接口,而FutureTask实现了RunnableFuture接口。所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
FutureTask提供了2个构造器:
public FutureTask(Callable<V> callable) {
}
public FutureTask(Runnable runnable, V result) {
}
事实上,FutureTask是Future接口的一个唯一实现类。
示例:
public class Test {
public static void main(String[] args) {
//第一种方式
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
executor.submit(futureTask);
executor.shutdown();
//第二种方式,注意这种方式和第一种方式效果是类似的,只不过一个使用的是ExecutorService,一个使用的是Thread
/*Task task = new Task();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
Thread thread = new Thread(futureTask);
thread.start();*/
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("主线程在执行任务");
try {
//futureTask其实是Runnable+Future的综合体,因此可以通过futureTask.get()获取执行结果
System.out.println("task运行结果"+futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("所有任务执行完毕");
}
}
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
System.out.println("子线程在进行计算");
Thread.sleep(3000);
int sum = 0;
for(int i=0;i<100;i++)
sum += i;
return sum;
}
}
java Executor框架
Runnable接口和Callable接口是对任务处理逻辑的抽象,不管是什么样的任务,其处理逻辑总是展现为一个具有统一签名的方法——Runnable.run()或者Callable.call()。二者区别如下:
- 方法签名不同,
void Runnable.run(),V Callable.call() throws Exception - 是否允许有返回值,
Callable允许有返回值 - 是否允许抛出异常,
Callable允许抛出异常。
java.util.concurrent.Executor接口则是对任务的执行进行的抽象,接口定义了如下方法:
void execute(Runnable command)
ExecutorService在Executor的基础上增加了“service”特性的方法:
- shutdown()、shutdownNow():都是关闭当前service服务,释放Executor的所有资源(参见实现类);它所触发的动作就是取消队列中任务的执行。shutdown是一种“友好”的关闭,它将不再(事实上是不能)接受新的任务提交,同时把已经提交到队列中的任务执行完毕。shutdownNow更加直接一些,它将会把尚未执行的任务不再执行,正在执行的任务,通过“线程中断”(thread.interrupt),如果线程无法响应“中断”,那么将不会通过此方式被立即结束。shutdowNow是个有返回类型的方法,它返回那些等待执行的任务列表(List<Runnable>)
- isShutdown:程序是否已经关闭,1)方法将导致其返回true。
- isTerminated:是否已经结束,如果关闭后,所有的任务都执行完成,将返回true,否则其他情况均返回false。
- awaitTermination(timeout):会抛出interruptException,此方法就是个废柴,大概意思是等待一段之间直到“任务全部结束”,如果超时就返回false。
- Future submit(callable/runnale):向Executor提交任务,并返回一个结果未定的Future。
- List<Future> invokeAll(Collection<Callable>):一个废柴方法,同步的方法,执行所有的任务列表,当所有任务都执行完成后,返回Future列表。这方法有啥用??貌似,可以对一批任务进行批量跟踪。此方法会抛出interruptException。
- T invokeAny(Collection<Callable>): 任务集合中,任何一个任务完成就返回。
这些方法都会被ExecutorService的子类实现,其实Executor的子类的实现原理,才是最有意义的。其实基于Executor接口自己也能创造世界。
Executors
java中提供了Executors工具类,能够返回默认线程工厂、能够将runnable实例转换为callable实例。
| 方法名 | 功能 |
|---|---|
| newFixedThreadPool(int nThreads) | 创建固定大小的线程池 |
| newSingleThreadExecutor() | 创建只有一个线程的线程池 |
| newCachedThreadPool() | 创建一个不限线程数上限的线程池,任何提交的任务都将立即执行 |
不过阿里开发手册中禁止使用这种方式去创建线程池,需要使用ThreadPoolExecutor,这个后面介绍。
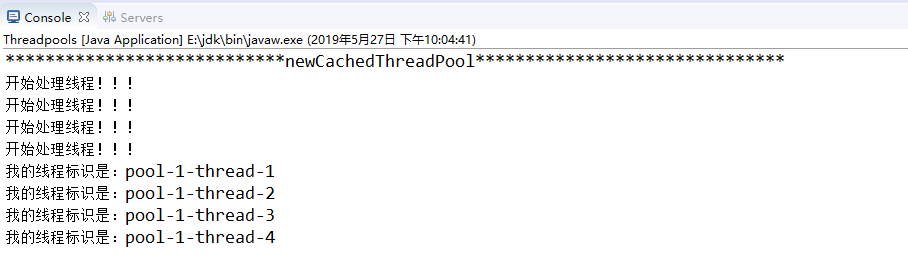
1、newCachedThreadPool
创建一个可缓存线程池,应用中存在的线程数可以无限大,示例代码如下:
package com.alivn.sockets;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class Threadpools { /**
* 我们获取四次次线程,观察4个线程地址
* @param args
*/
public static void main(String[]args)
{
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
System.out.println("****************************newCachedThreadPool*******************************");
for(int i=0;i<4;i++)
{
final int index=i;
//submit本质上还是调用execute(),submit()方法可以有返回结果future
newCachedThreadPool.submit(new ThreadForpools(index));
}
}
}
package com.alivn.sockets;
public class ThreadForpools implements Runnable{
private Integer index;
public ThreadForpools(Integer index)
{
this.index=index;
}
@Override
public void run() {
/***
* 业务......省略
*/
try {
System.out.println("开始处理线程!!!");
Thread.sleep(index*100);
System.out.println("我的线程标识是:" + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
输出结果是:可以有无限大的线程数进来(线程地址不一样)
2、newFixedThreadPool
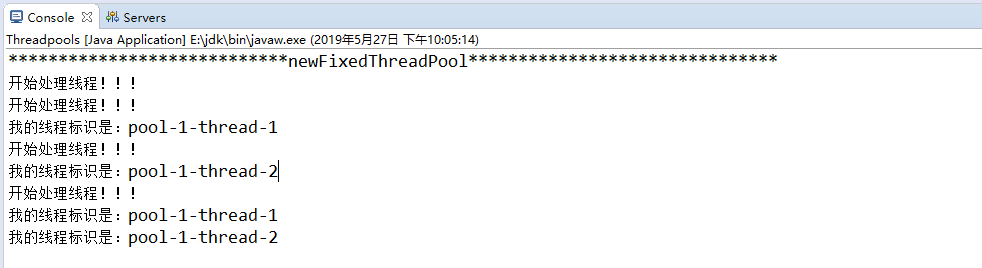
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。示例代码如下:
package com.alivn.sockets;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class Threadpools { /**
* 我们获取四次次线程,观察4个线程地址
* @param args
*/
public static void main(String[]args)
{
//线程池允许同时存在两个线程
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(2);
System.out.println("****************************newFixedThreadPool*******************************");
for(int i=0;i<4;i++)
{
final int index=i;
newFixedThreadPool.submit(new ThreadForpools(index));
}
}
}
输出结果:每次只有两个线程在处理,当第一个线程执行完毕后,新的线程进来开始处理(线程地址不一样)
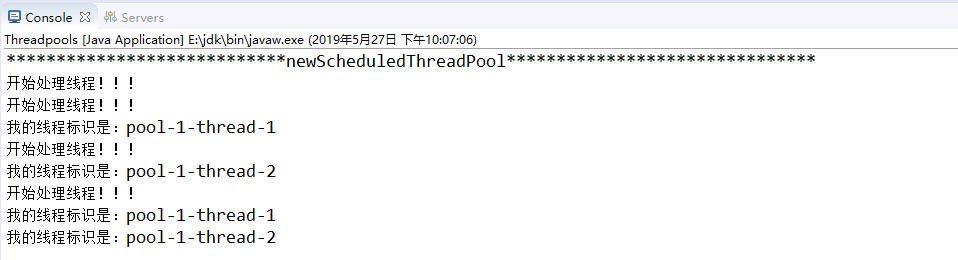
3、newScheduledThreadPool
package com.ty.thread; import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit; public class Threadpools {
/**
* 我们获取四次次线程,观察4个线程地址
* @param args
*/
public static void main(String[]args)
{
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(2);
System.out.println("****************************newScheduledThreadPool*******************************");
for(int i=0;i<4;i++)
{
final int index=i;
//延迟三秒执行
newScheduledThreadPool.schedule(new ThreadForpools(index), 3, TimeUnit.SECONDS);
}
}
}
执行结果:延迟三秒之后执行,除了延迟执行之外和newFixedThreadPool基本相同,可以用来执行定时任务
4、newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。示例代码如下:
package com.ty.thread; import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class Threadpools {
/**
* 我们获取四次次线程,观察4个线程地址
* @param args
*/
public static void main(String[]args)
{
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();
System.out.println("****************************newSingleThreadExecutor*******************************");
for(int i=0;i<4;i++)
{
final int index=i;
newSingleThreadExecutor.submit(new ThreadForpools(index));
}
}
}
执行结果:只存在一个线程,顺序执行

ThreadPoolExecutor
Executors中创建线程池的快捷方法,实际上是调用了ThreadPoolExecutor的构造方法(定时任务使用的是ScheduledThreadPoolExecutor),该类构造方法参数列表如下:
// Java线程池的完整构造函数
public ThreadPoolExecutor(
int corePoolSize, // 线程池长期维持的线程数,即使线程处于Idle状态,也不会回收。
int maximumPoolSize, // 线程数的上限
long keepAliveTime, TimeUnit unit, // 超过corePoolSize的线程的idle时长,超过这个时间,多余的线程会被回收。
BlockingQueue<Runnable> workQueue, // 任务的排队队列
ThreadFactory threadFactory, // 新线程的产生方式
RejectedExecutionHandler handler) // 拒绝策略
这些参数中,比较容易引起问题的有corePoolSize, maximumPoolSize, workQueue以及handler:
corePoolSize和maximumPoolSize设置不当会影响效率,甚至耗尽线程;workQueue设置不当容易导致OOM;handler设置不当会导致提交任务时抛出异常。
1、线程池的工作顺序
corePoolSize -> 任务队列 -> maximumPoolSize -> 拒绝策略
2、提交任务的方式:
| 提交方式 | 是否关心返回结果 |
|---|---|
Future<T> submit(Callable<T> task) |
是 |
void execute(Runnable command) |
否 |
Future<?> submit(Runnable task) |
否,虽然返回Future,但是其get()方法总是返回null |
3、如何正确使用线程池
3.1避免使用无界队列
不要使用Executors.newXXXThreadPool()快捷方法创建线程池,因为这种方式会使用无界的任务队列,为避免OOM,我们应该使用ThreadPoolExecutor的构造方法手动指定队列的最大长度:
ExecutorService executorService = new ThreadPoolExecutor(2, 2,
0, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(512), // 使用有界队列,避免OOM
new ThreadPoolExecutor.DiscardPolicy());
3.2明确拒绝任务时的行为
任务队列总有占满的时候,这是再submit()提交新的任务会怎么样呢?RejectedExecutionHandler接口为我们提供了控制方式,接口定义如下:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
线程池给我们提供了几种常见的拒绝策略:
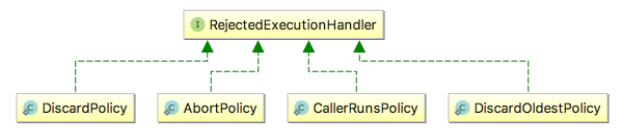
| 拒绝策略 | 拒绝行为 |
|---|---|
| AbortPolicy | 抛出RejectedExecutionException |
| DiscardPolicy | 什么也不做,直接忽略 |
| DiscardOldestPolicy | 丢弃执行队列中最老的任务,尝试为当前提交的任务腾出位置 |
| CallerRunsPolicy | 直接由提交任务者执行这个任务 |
线程池默认的拒绝行为是AbortPolicy,也就是抛出RejectedExecutionException异常,该异常是非受检异常,很容易忘记捕获。如果不关心任务被拒绝的事件,可以将拒绝策略设置成DiscardPolicy,这样多余的任务会悄悄的被忽略。
ExecutorService executorService = new ThreadPoolExecutor(2, 2,
0, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(512),
new ThreadPoolExecutor.DiscardPolicy());// 指定拒绝策略
3.3获取处理结果和异常
线程池的处理结果、以及处理过程中的异常都被包装到Future中,并在调用Future.get()方法时获取,执行过程中的异常会被包装成ExecutionException,submit()方法本身不会传递结果和任务执行过程中的异常。获取执行结果的代码可以这样写:
ExecutorService executorService = Executors.newFixedThreadPool(4);
Future<Object> future = executorService.submit(new Callable<Object>() {
@Override
public Object call() throws Exception {
throw new RuntimeException("exception in call~");// 该异常会在调用Future.get()时传递给调用者
}
}); try {
Object result = future.get();
} catch (InterruptedException e) {
// interrupt
} catch (ExecutionException e) {
// exception in Callable.call()
e.printStackTrace();
}
上述代码输出类似如下:

CompletionService异步任务的批量执行
普通情况下,我们使用Runnable作为主要的任务表示形式,可是Runnable是一种有非常大局限的抽象,run方法中仅仅能记录日志,打印,或者把数据汇总入某个容器(一方面内存消耗大,还有一方面须要控制同步,效率非常大的限制),总之不能返回运行的结果;比方同一时候1000个任务去网络上抓取数据,然后将抓取到的数据进行处理(处理方式不定),我认为最好的方式就是提供回调接口,把处理的方式最为回调传进去;可是如今我们有了更好的方式实现:CompletionService + Callable
Callable的call方法能够返回运行的结果;
CompletionService将Executor(线程池)和BlockingQueue(堵塞队列)结合在一起,同一时候使用Callable作为任务的基本单元,整个过程就是生产者不断把Callable任务放入堵塞对了,Executor作为消费者不断把任务取出来运行,并返回结果;
通过一个示例来明确CompletionService的作用,
1、不使用CompletionService
任务类
package net.aty.completeservice; import java.util.concurrent.Callable;
import java.util.concurrent.TimeUnit; public class ReturnAfterSleepCallable implements Callable<Integer>
{
private int sleepSeconds; private int returnValue; public ReturnAfterSleepCallable(int sleepSeconds, int returnValue)
{
this.sleepSeconds = sleepSeconds;
this.returnValue = returnValue;
} @Override
public Integer call() throws Exception
{
System.out.println("begin to execute."); TimeUnit.SECONDS.sleep(sleepSeconds); System.out.println("end to execute."); return returnValue;
}
}
通过一个List来保存每个任务返回的Future,然后轮询这些Future,直到每个Future都已完成。我们不希望出现因为排在前面的任务阻塞导致后面先完成的任务的结果没有及时获取的情况,所以在调用get方式时,需要将超时时间设置为0。
package net.aty.completeservice; import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException; public class TraditionalTest
{
public static void main(String[] args)
{
int taskSize = 5; ExecutorService executor = Executors.newFixedThreadPool(taskSize); List<Future<Integer>> futureList = new ArrayList<Future<Integer>>(); for (int i = 1; i <= taskSize; i++)
{
int sleep = taskSize - i; // 睡眠时间 int value = i; // 返回结果 // 向线程池提交任务
Future<Integer> future = executor.submit(new ReturnAfterSleepCallable(sleep, value)); // 保留每个任务的Future
futureList.add(future);
} // 轮询,获取完成任务的返回结果
while(taskSize > 0)
{
for (Future<Integer> future : futureList)
{
Integer result = null; try
{
result = future.get(0, TimeUnit.SECONDS);
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
} catch (TimeoutException e)
{
// 超时异常需要忽略,因为我们设置了等待时间为0,只要任务没有完成,就会报该异常
} // 任务已经完成
if(result != null)
{
System.out.println("result=" + result); // 从future列表中删除已经完成的任务
futureList.remove(future);
taskSize--;
//此处必须break,否则会抛出并发修改异常。(也可以通过将futureList声明为CopyOnWriteArrayList类型解决)
break; // 进行下一次while循环
}
}
} // 所有任务已经完成,关闭线程池
System.out.println("all over.");
executor.shutdown();
}
}
可见轮询future列表非常的复杂,而且还有很多异常需要处理,TimeOutException异常需要忽略;还要通过双重循环和break,防止遍历集合的过程中,出现并发修改异常。另外就是ExcutorService里面任务结果Future也得按照入队列的顺序来取,比如任务一先进队列,那么取Future的时候也是先取到任务一的结果。那么如果十个任务中,第一个执行时间最长,后面的不能先取出,这也是一个问题。这么多需要考虑的细节,程序员很容易犯错。
2、使用CompletionService
package net.aty.completeservice; import java.util.concurrent.CompletionService;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorCompletionService;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class CompletionServiceTest
{
public static void main(String[] args)
{
int taskSize = 5; ExecutorService executor = Executors.newFixedThreadPool(taskSize); // 构建完成服务
CompletionService<Integer> completionService = new ExecutorCompletionService<Integer>(
executor); for (int i = 1; i <= taskSize; i++)
{
int sleep = taskSize - i; // 睡眠时间 int value = i; // 返回结果 // 向线程池提交任务
completionService
.submit(new ReturnAfterSleepCallable(sleep, value));
} // 按照完成顺序,打印结果
for (int i = 0; i < taskSize; i++)
{
try
{
System.out.println(completionService.take().get());
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
} // 所有任务已经完成,关闭线程池
System.out.println("all over.");
executor.shutdown();
}
}
可见使用CompletionService不会有TimeOutExeception的问题,不用遍历future列表,不用担心并发修改异常。
3、CompletionService和ExecutorCompletionService的实现
JDK源码中CompletionService的javadoc说明如下:
/**
* A service that decouples the production of new asynchronous tasks
* from the consumption of the results of completed tasks. Producers
* <tt>submit</tt> tasks for execution. Consumers <tt>take</tt>
* completed tasks and process their results in the order they
* complete.
*/
public ExecutorCompletionService(Executor executor) {
if (executor == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
this.completionQueue = new LinkedBlockingQueue<Future<V>>();
}
public Future<V> submit(Callable<V> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task);
executor.execute(new QueueingFuture(f));
return f;
}
QueueingFuture是FutureTask的一个子类,通过改写FutureTask类的done方法,可以实现当任务完成时,将结果放入到BlockingQueue中。
private class QueueingFuture extends FutureTask<Void> {
QueueingFuture(RunnableFuture<V> task) {
super(task, null);
this.task = task;
}
protected void done() { completionQueue.add(task); }
private final Future<V> task;
}
这里简单说明下:FutureTask.done(),这个方法默认什么都不做,就是一个回调,当提交的线程池中的任务完成时,会被自动调用。这也就说时候,当任务完成的时候,会自动执行QueueingFuture.done()方法,将返回结果加入到阻塞队列中,加入的顺序就是任务完成的先后顺序。
java并发系列(八)-----java异步编程的更多相关文章
- java并发系列(六)-----Java并发:volatile关键字解析
在 Java 并发编程中,要想使并发程序能够正确地执行,必须要保证三条原则,即:原子性.可见性和有序性.只要有一条原则没有被保证,就有可能会导致程序运行不正确.volatile关键字 被用来保证可见性 ...
- 【Java并发系列】--Java内存模型
Java内存模型 1 基本概念 程序:代码,完成某一个任务的代码序列(静态概念) 进程:程序在某些数据上的一次运行(动态) 线程:一个进程有一个或多个线程组成(占有资源的独立单元) 2 JVM与线程 ...
- Java 并发系列之一:java 并发体系
1. java 并发机制的底层原理实现 1.1 volatile 1.2 synchronized 1.3 原子操作 2. java 内存模型(JMM) 3. java并发基础线程 4. java ...
- java多线程系列(八)---CountDownLatch和CyclicBarrie
CountDownLatch 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 java多线 ...
- Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析
学习Java并发编程不得不去了解一下java.util.concurrent这个包,这个包下面有许多我们经常用到的并发工具类,例如:ReentrantLock, CountDownLatch, Cyc ...
- Java 并发系列之二:java 并发机制的底层实现原理
1. 处理器实现原子操作 2. volatile /** 补充: 主要作用:内存可见性,是变量在多个线程中可见,修饰变量,解决一写多读的问题. 轻量级的synchronized,不会造成阻塞.性能比s ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- Java并发系列[3]----AbstractQueuedSynchronizer源码分析之共享模式
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快 ...
- Java并发系列[5]----ReentrantLock源码分析
在Java5.0之前,协调对共享对象的访问可以使用的机制只有synchronized和volatile.我们知道synchronized关键字实现了内置锁,而volatile关键字保证了多线程的内存可 ...
随机推荐
- Apache下更改.htaccess文件名称
有时候我们需要更改.htaccess的名称以解决一些问题 比如:Eclipse下是不显示点开头的文件的 所以我们可以使用 Apache的AccessFileName来更改此配置文件的名称 Acces ...
- docker 个人遇到问题日志记录
system: openSUSE Leap 42.3 在openSUSE中可直接运行" sudo zypper in docker"进行安装docker-ce wakasann@l ...
- 【9.14NOIP模拟pj】wtaxi 题解——搜索
[9.14NOIP模拟pj]wtaxi 题目简化 有K辆车,N个人,上车给D元,只有S分钟.上车后无论多少人都要给D元,原地等多少分钟就没了多少元.求最小花费的钱. 我的思路 毫无疑问,此题可以用搜索 ...
- nvm-windows 之nodejs 版本管理
前言 最近准备学习后端相关的东西,但是公司目前的node版本是偏低的,但是现在的node版本变化太快.刚好也有nvm这种版本管理器的存在,简直了都.兴奋之后发现,不支持windows系统,此处~~ ...
- 19-11-2-M
最后一个当然要模自己辣. %%%Miemengsb ZJ一下: 三道题没有一道会的,唯一的20还是T2输出$n/2$得的 咝…… T1一看,只会暴力. T2一看,像是状压,但是我是$dpsb$,于是弃 ...
- IOS学习笔记56-IOS7状态栏适配方法一
近期由于IOS7的发布,所以应用的适配潮可谓是都搞的锣鼓喧天,甚是热闹,因此呢,因适配IOS7而产生的问题也是铺天盖地的卷来,所以了,我也从简单的状态栏适配开始,先研究了下关于状态栏的适配,特总结如下 ...
- 表单下拉框select
<!DOCTYPE html> <html lang="zh"> <head> <title></title> < ...
- 2019牛客暑假多校赛(第二场) F和H(单调栈)
F-Partition problem https://ac.nowcoder.com/acm/contest/882/F 题意:输入一个数n,代表总共有2n个人,然后每个人对所有人有个贡献值,然后问 ...
- PAT甲级——A1102 Invert a Binary Tree
The following is from Max Howell @twitter: Google: 90% of our engineers use the software you wrote ( ...
- MySQL Server Logs
日志记录存储方式 #日志记录存储方式 mysql> show variables like 'log_output'; mysql> set global log_output='FILE ...