Person Re-identification 系列论文笔记(五):SVD-net
SVDNet for Pedestrian Retrieval
Sun Y, Zheng L, Deng W, et al. SVDNet for Pedestrian Retrieval[J]. 2017.
a spotlight at ICCV 2017
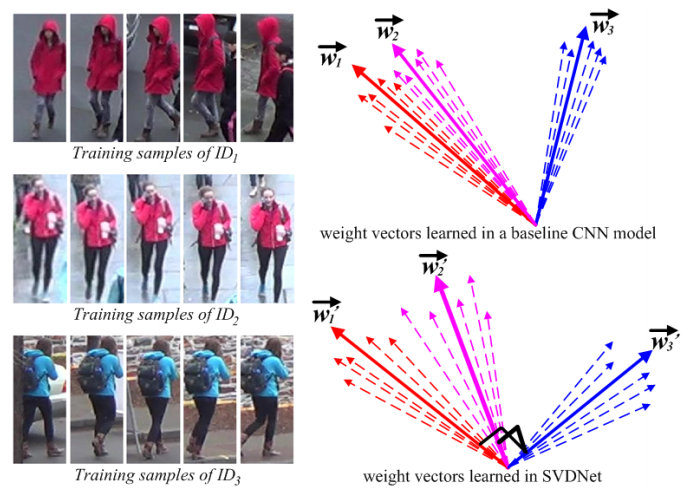
这篇的出发点是全连接层的权值相关性分析,作者认为全连接层的作用可以看做一组向量投影。当权值直接相关性较高时(可以理解为权值冗余),特征差异小,直接导致检索中距离差异小,无法获取差异化的特征。
作者提出用SVD对降维层进行操作,提高权值矩阵的正交性,从而提高检索性能。但整个算法流程中,需要人工操作的地方很多,导致整个流程非常不自然。性能不错,但实际操作起来需要过多的人工干预,倒不如将正交性做成一种正则,添加到训练中。
有兴趣的可以看看这篇论文《All You Need is Beyond a Good Init: Exploring Better Solution for Training Extremely Deep Convolutional Neural Networks with Orthonormality and Modulation》。
contributions
提出对全连接层进行SVD,让权值向量正交化从而减少冗余,提高检索性。
SVD简介
A是m*n的矩阵且rank(A)是k,A的SVD如下:
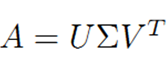
其中,U是m*m的正交阵,U的列向量称为A的左奇异向量,V是n*n的正交阵,V的列向量称为A的右奇异向量, 是m*n的对角阵,对角线上的值称为A的奇异值。
SVD物理意义
借用《数学之美》中的解释,
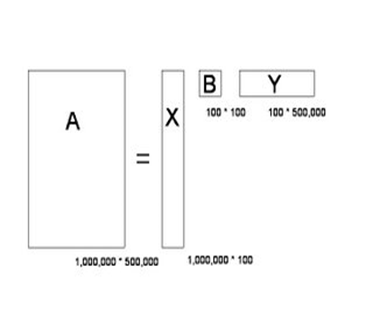
奇异值分解是把一个大矩阵,分解成三个小矩阵相乘。比如把上面的例子中的矩阵分解成一个一百万乘以一百的矩阵X,
一个一百乘以一百的矩阵B,和一个一百乘以五十万的矩阵Y。这三个矩阵的元素总数加起来也不过1.5亿,
仅仅是原来的三千分之一。相应的存储量和计算量都会小三个数量级以上。
三个矩阵物理含义:X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。
Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章类之间的相关性。
因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
SVD-net pipeline
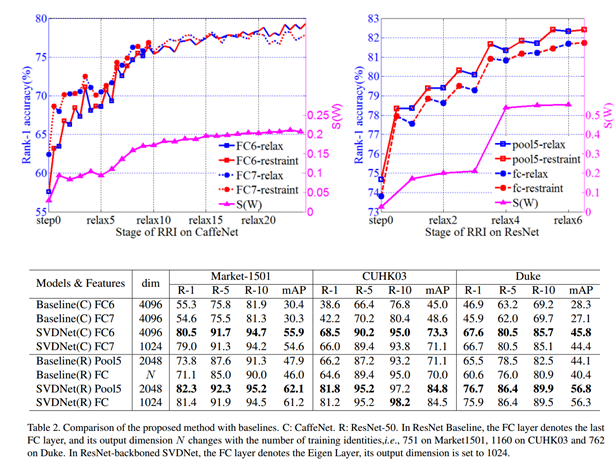
将倒数第二个FC层(如果是最后一个FC会出现不收敛,有可能是最后一层FC是由样本分布决定)进行SVD,且bias设置为0(bias会破坏正交性),测试特征用输入前的特征会更好一点(经过测试得到的结论)。

RRI训练步骤:

相关性指标S(W)

experiments
Person Re-identification 系列论文笔记(五):SVD-net的更多相关文章
- Person Re-identification 系列论文笔记(一):Scalable Person Re-identification: A Benchmark
打算整理一个关于Person Re-identification的系列论文笔记,主要记录近年CNN快速发展中的部分有亮点和借鉴意义的论文. 论文笔记流程采用contributions->algo ...
- Person Re-identification 系列论文笔记(二):A Discriminatively Learned CNN Embedding for Person Re-identification
A Discriminatively Learned CNN Embedding for Person Re-identification Zheng Z, Zheng L, Yang Y. A Di ...
- Person Re-identification 系列论文笔记(三):Improving Person Re-identification by Attribute and Identity Learning
Improving Person Re-identification by Attribute and Identity Learning Lin Y, Zheng L, Zheng Z, et al ...
- Person Re-identification 系列论文笔记(八):SPReID
Human Semantic Parsing for Person Re-identification Kalayeh M M, Basaran E, Gokmen M, et al. Human S ...
- Person Re-identification 系列论文笔记(六):AlignedReID
AlignedReID Zhang X, Luo H, Fan X, et al. AlignedReID: Surpassing Human-Level Performance in Person ...
- Person Re-identification 系列论文笔记(七):PCB+RPP
Beyond Part Models: Person Retrieval with Refined Part Pooling Sun Y, Zheng L, Yang Y, et al. Beyond ...
- Person Re-identification 系列论文笔记(四):Re-ID done right: towards good practices for person re-identification
Re-ID done right: towards good practices for person re-identification Almazan J, Gajic B, Murray N, ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
随机推荐
- Java程序员面试题收集(3)
面试中被问到过的题目: 1.<%@ include=""/>和<jsp:include page="" flush="true&qu ...
- HBase性能优化方法总结 (转)
AutoFlush 通过调用HTable.setAutoFlushTo(false)方法可以将HTable写客户端自动flush关闭,这样可以批量写入数据到HBase,而不是有一条put就执行一次更新 ...
- UVAL3700
Interesting Yang Hui Triangle 题目大意:杨辉三角第n + 1行不能整除p(p是质数)的数的个数 题解: lucas定理C(n,m) = πC(ni,mi) (mod p) ...
- spring cloud深入学习(四)-----eureka源码解析、ribbon解析、声明式调用feign
基本概念 1.Registe 一一服务注册当eureka Client向Eureka Server注册时,Eureka Client提供自身的元数据,比如IP地址.端口.运行状况指标的Uri.主页地址 ...
- python条件变量之生产者与消费者操作实例分析
python条件变量之生产者与消费者操作实例分析 本文实例讲述了python条件变量之生产者与消费者操作.分享给大家供大家参考,具体如下: 互斥锁是最简单的线程同步机制,面对复杂线程同步问题,Pyth ...
- win7使用经验-调整cmd窗口大小
分享一个调整cmd窗口的方法: 1.右击标题栏空白处,选择属性 2.选择布局栏 3.修改屏幕缓冲区大小的宽度和高度(自定义) 4.确定 注意:这里的缓冲区大小是指用户可拖动缩放的范围,并不是cmd窗口 ...
- Python科学计算生态圈--Pandas
- 怎样判断一个exe可执行程序(dll文件)是32位的还是64位的
看到一个比较简单粗暴的方式,做个记录. 直接用记事本或者notepad++(文本编辑软件都可)打开exe文件(dll文件), 会有很多乱码,接下来只需要在第二段中找到PE两个字母,在其后的不远出会出现 ...
- 介绍Provide以及Inject
介绍 Vue 的 Provide 以及 Inject Provide 以及 Inject 是 Vue 中用于祖先元素向其所有后台元素注入依赖的接口. 具体用法 // Data.vue ... expo ...
- C++ 之手写memcpy
#include<iostream>#include<cstdio>using namespace std; void* mymemcpy(void* dst, const v ...