Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)
一、如何学习大规模数据集?
在训练样本集很大的情况下,我们可以先取一小部分样本学习模型,比如m=1000,然后画出对应的学习曲线。如果根据学习曲线发现模型属于高偏差,则应在现有样本上继续调整模型,具体调整策略参见第六节的高偏差时模型如何调整;如果发现模型属于高方差,则可以增加训练样本集。
二、随机梯度下降法(Stochastic Gradient Descent)
之前在讲到优化代价函数的时候,采取的都是“批量梯度下降法”Batch Gradient,这种方法在每次迭代的时候,都需要计算所有的训练样本,对于数以亿计的大规模样本集而言,计算代价太大,再加上需要多次迭代,累加起来计算量更大,收敛速度会比较慢。
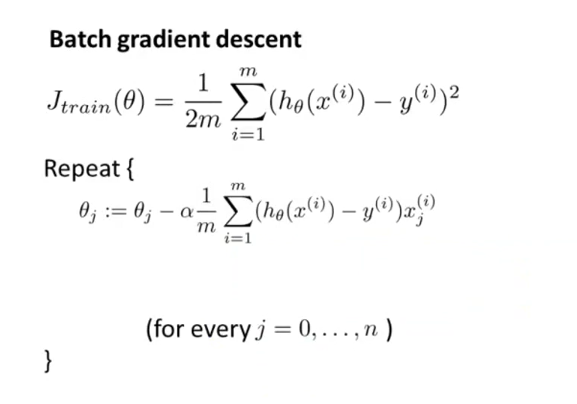
随机梯度下降法,首先打乱样本顺序,然后遍历样本集。对每一个样本就相当于迭代一次,调整一次参数,所以总体计算量小很大。对整个样本集的重复次数也就是1-10次足矣。所以,该算法要快很多。
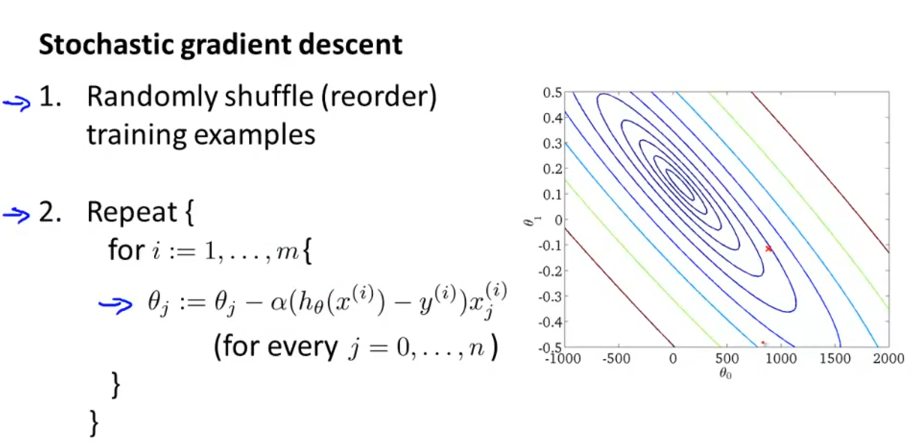
三、小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法介于批量梯度下降法与随机梯度下降法之间,每次迭代用b个样本数据,b往往=10,或者2~100的数。但是在使用小批量梯度下降法时,如果你采用的是向量化计算时,能够同时并行处理b个样本,此时效率应该比随机梯度法更好,因为其并没有并行处理数据。


四、随机梯度下降法的收敛。
随机梯度下降法最后的收敛不一定是全局最小值,这点跟批量梯度下降法不大一样,而是在全局最小值周围振荡徘徊,只要很接近全局最小值,这也是可以接受的。其实可以动态调整学习速率α=常数1/(迭代次数+常数2),这样随着迭代进行,α逐渐减小,有利于最后收敛到全局最小值。但是由于"常数1"与“常数2”不好确定,所以往往设定α是固定不变的。
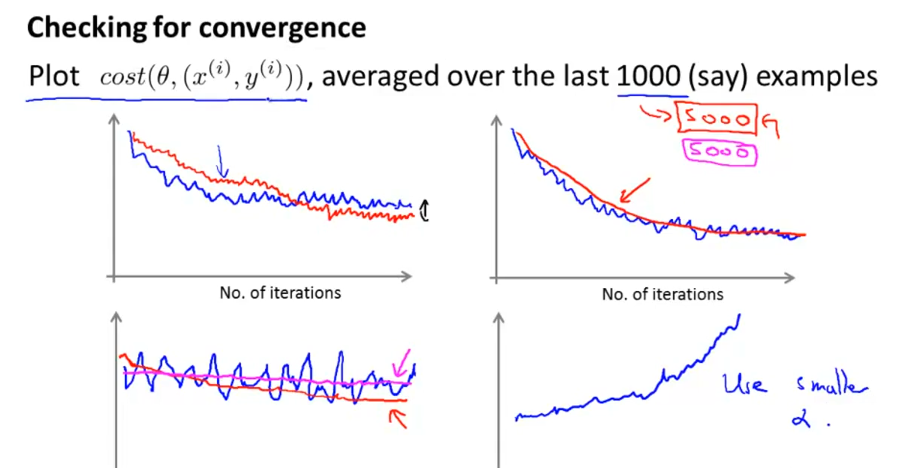
如何判断随着迭代进行,模型在收敛呢?每隔1000或5000个样本,计算这些样本的J值一个总体平均值,然后画出来,如下图所示。从图形走势看模型迭代过程中是不是在下降收敛。如第四张图,走势是上升的,则应调小学习速率α。
五、在线机器学习
以物流运输为例,当用户登陆网站,选择包裹起始地与目的地后,网站据此提供一个服务价格,用户可能接受,也可能拒绝。一个用户完成后,我们就得到了一个样本(x,y),这样我们就可以用随机梯度下降法来学习了。当有用户源源不断进来时,模型就不断地学习调整参数Θ。即便随着经济发展,用户可以接受更高价格了,模型也能根据用户选择,动态调整参数Θ。在线机器学习的前提是,网站能源源不断地获取大量样本数据。

另一个应用例子就是用户搜索商品时,根据用户的点击情况来动态调整参数,尽量将点击率高的产品推荐给用户。
Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)的更多相关文章
- [C12] 大规模机器学习(Large Scale Machine Learning)
大规模机器学习(Large Scale Machine Learning) 大型数据集的学习(Learning With Large Datasets) 如果你回顾一下最近5年或10年的机器学习历史. ...
- 斯坦福第十七课:大规模机器学习(Large Scale Machine Learning)
17.1 大型数据集的学习 17.2 随机梯度下降法 17.3 微型批量梯度下降 17.4 随机梯度下降收敛 17.5 在线学习 17.6 映射化简和数据并行 17.1 大型数据集的学习
- Ng第十七课:大规模机器学习(Large Scale Machine Learning)
17.1 大型数据集的学习 17.2 随机梯度下降法 17.3 微型批量梯度下降 17.4 随机梯度下降收敛 17.5 在线学习 17.6 映射化简和数据并行 17.1 大型数据集的学习 ...
- Coursera在线学习---第六节.构建机器学习系统
备: High bias(高偏差) 模型会欠拟合 High variance(高方差) 模型会过拟合 正则化参数λ过大造成高偏差,λ过小造成高方差 一.利用训练好的模型做数据预测时,如果效果不好 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 大规模机器学习(Large Scale Machine Learning)
本博客是针对Andrew Ng在Coursera上的machine learning课程的学习笔记. 目录 在大数据集上进行学习(Learning with Large Data Sets) 随机梯度 ...
- 吴恩达机器学习笔记(十一) —— Large Scale Machine Learning
主要内容: 一.Batch gradient descent 二.Stochastic gradient descent 三.Mini-batch gradient descent 四.Online ...
- Coursera在线学习---第五节.Logistic Regression
一.假设函数与决策边界 二.求解代价函数 这样推导后最后发现,逻辑回归参数更新公式跟线性回归参数更新方式一摸一样. 为什么线性回归采用最小二乘法作为求解代价函数,而逻辑回归却用极大似然估计求解? 解答 ...
- Coursera在线学习---第四节.过拟合问题
一.解决过拟合问题方法 1)减少特征数量 --人为筛选 --靠模型筛选 2)正则化(Regularization) 原理:可以降低参数Θ的数量级,使一些Θ值变得非常之小.这样的目的既能保证足够的特征变 ...
随机推荐
- zabbix概念
Zabbix是一个企业级的.开源的.分布式监控解决方案. Zabbix可以监控网络和服务的监控状况. Zabbix利用灵活的告警机制,允许用户对事件发送基于Email的告警. 这样可以保证快速的对问题 ...
- jenkins部署springboot多项目
war包的部署问题不大,这里记录jar包的部署过程: 1:jar包的体积过大问题 pom.xml参考以下配置(依赖包会分离到target/lib/,jar包体积由几十M缩小到几k) <build ...
- MyBatis原理简介
1.什么是 MyBatis ? MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyB ...
- 第20天:京东nav、footer部分制作
一.鼠标的4种状态 cursor:pointer; 鼠标变成小手cursor:default;小白cursor:move;移动cursor:text;文本输入 二.网页布局:1.input.butto ...
- CodeChef LEMOVIE
题意:给你n个数字(下标不同数值相同的数字应当被认为是不同的数字),有n!种排列方式.每种排列方式的价值定义为:第一次出现时比前面的所有数字都大的数值个数. 比如1,2,2,3这个排列中,1,2,3这 ...
- python的if语句、while循环、for循环
if语句 计算机又被称作电脑,意指计算机可以像人脑一样,根据周围环境条件(即expession)的变化做出不同的反应(即执行代码)if语句就是来控制计算机实现这一功能 语法: 1.单分支,单个条件判断 ...
- bzoj3709: [PA2014]Bohater 贪心
~~~题面~~~ 题解: 首先有一个比较明显的策略,肯定先要把能带给自己受益的先选完,然后再以最佳状态去打那些会给自己带来损失的怪. 对于前一部分(可以带来受益的怪),显然我们需要先从代价小的打起,因 ...
- Shell编程语法
创建shell程序的步骤: 第一步:创建一个脚本文件.sh. 第二步:授予权限使它可以执行chmod u+x .sh 第三步:执行 ./example 或者 sh example 脚本调试: ...
- 清华大学计算机系大二 java 小学期考试题(摘自知乎)
public class Main { public void test(Object o) { System.out.println("Object"); } public vo ...
- Balanced Sequence(毒瘤啊)排序贪心 HDU多校
Problem Description Chiaki has n strings s1,s2,…,sn consisting of '(' and ')'. A string of this type ...