MapReduce机制
1. MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
2. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参是key、value对,表示函数的输入信息。
MapReduce的原理图如图所示:

整个处理过程的流程图:

我们不妨通过一个简单的例子加以说明。
这个例子是统计一堆域名中,每个域名各有多少个。如果放在单机上写程序,处理起来很容易,可以用个HashMap或者在数据库中distinct,但是一旦数据量足够大,单机无法满足的时候,就需要用到集群,即MapReduce进行运行。运行大概思路如下图所示,首先文件里面的内容被分成了若干块,放到了不同的map中,进行相应的统计处理,即变成<qq.com 1>这种形式,注意到这是可以分布运行的,不会影响到最终结果。框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,相同的key为一组,相同的组放到一个reduce中进行运行。所以reduce收到的效果是类似<qq.com {1,1,1,1...}>这种格式,然后reduce再进行一个简单的加和运算就可以了,最终输出类似<qq.com 50000>这种效果。

◆执行步骤:
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.reduce任务处理
2.1 在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。
2.2写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。
任务切片的示意图:
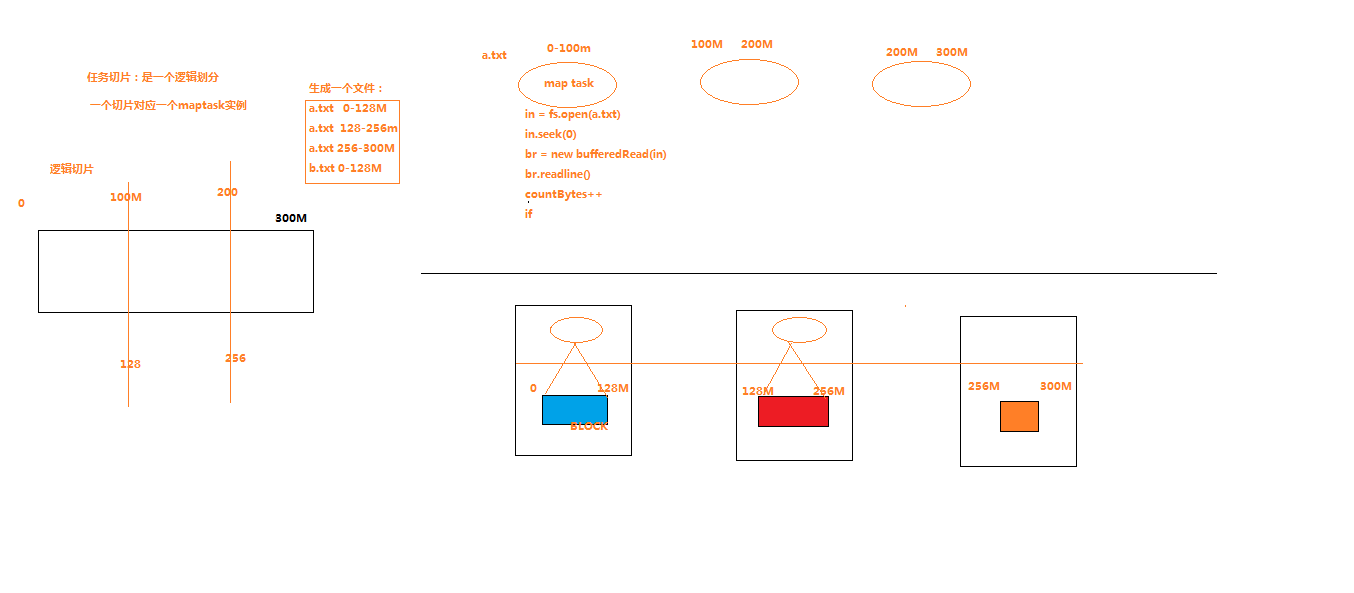
我们用代码进行说明,导入mapreduce所需要的相应包,建立三个文件:

WCMapper.java文件:
package cn.darrenchan.hadoop.mr.wordcount; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
//map 和 reduce 的数据输入输出都是以 key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
//下面这两种类型就相当于Long和String,是hadoop的类型
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ //mapreduce框架每读一行数据就调用一次该方法
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value
//key 是这一行数据的起始偏移量 value 是这一行的文本内容 //将这一行的内容转换成string类型
String line = value.toString(); //对这一行的文本按特定分隔符切分
String[] words = StringUtils.split(line, " "); //遍历这个单词数组输出为kv形式 k:单词 v : 1
for(String word : words){
context.write(new Text(word), new LongWritable(1));
} } }
WCReducer.java文件:
package cn.darrenchan.hadoop.mr.wordcount; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { // 框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,相同的key为一组,调用一次reduce方法
// <hello,{1,1,1,1,1,1.....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException { long count = 0;
// 遍历value的list,进行累加求和
for (LongWritable value : values) {
count += value.get();
} // 输出这一个单词的统计结果
context.write(key, new LongWritable(count)); } }
WCRunner.java文件:
package cn.darrenchan.hadoop.mr.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce
* 还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
* ....
*
*/
public class WCRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包
wcjob.setJarByClass(WCRunner.class); //本job使用的mapper和reducer的类
wcjob.setMapperClass(WCMapper.class);
wcjob.setReducerClass(WCReducer.class); //指定reduce的输出数据kv类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class); //指定mapper的输出数据kv类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放路径
FileInputFormat.setInputPaths(wcjob, new Path("/wc/srcdata/")); //指定处理结果的输出数据存放路径
FileOutputFormat.setOutputPath(wcjob, new Path("/wc/output/")); //将job提交给集群运行 ,将运行状态进行打印
wcjob.waitForCompletion(true); } }
我们可以以集群模式运行:
将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.darrenchan.hadoop.mr.wordcount.WCRunner即可。
我们也可以以本地模式运行:
在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
在运行过程中会打印运行状态,信息如下:
17/02/24 06:21:29 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.230.134:8032
17/02/24 06:21:30 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/02/24 06:21:31 INFO input.FileInputFormat: Total input paths to process : 1
17/02/24 06:21:32 INFO mapreduce.JobSubmitter: number of splits:1
17/02/24 06:21:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1487945579635_0001
17/02/24 06:21:36 INFO impl.YarnClientImpl: Submitted application application_1487945579635_0001
17/02/24 06:21:37 INFO mapreduce.Job: The url to track the job: http://weekend110:8088/proxy/application_1487945579635_0001/
17/02/24 06:21:37 INFO mapreduce.Job: Running job: job_1487945579635_0001
17/02/24 06:21:48 INFO mapreduce.Job: Job job_1487945579635_0001 running in uber mode : false
17/02/24 06:21:48 INFO mapreduce.Job: map 0% reduce 0%
17/02/24 06:21:54 INFO mapreduce.Job: map 100% reduce 0%
17/02/24 06:21:59 INFO mapreduce.Job: map 100% reduce 100%
17/02/24 06:21:59 INFO mapreduce.Job: Job job_1487945579635_0001 completed successfully
17/02/24 06:21:59 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=297
FILE: Number of bytes written=186437
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=208
HDFS: Number of bytes written=87
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3753
Total time spent by all reduces in occupied slots (ms)=3019
Total time spent by all map tasks (ms)=3753
Total time spent by all reduce tasks (ms)=3019
Total vcore-seconds taken by all map tasks=3753
Total vcore-seconds taken by all reduce tasks=3019
Total megabyte-seconds taken by all map tasks=3843072
Total megabyte-seconds taken by all reduce tasks=3091456
Map-Reduce Framework
Map input records=8
Map output records=19
Map output bytes=253
Map output materialized bytes=297
Input split bytes=107
Combine input records=0
Combine output records=0
Reduce input groups=12
Reduce shuffle bytes=297
Reduce input records=19
Reduce output records=12
Spilled Records=38
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=164
CPU time spent (ms)=1460
Physical memory (bytes) snapshot=218402816
Virtual memory (bytes) snapshot=726446080
Total committed heap usage (bytes)=137433088
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=101
File Output Format Counters
Bytes Written=87
最终会生成如下两个文件:

源文件是:
hello chenchi
hello jim
hello jack
hello darren
hello baby
hello dd
baby is my god
hahaha is rubbish
在part-r-0000中会显示相应结果:
baby 2
chenchi 1
darren 1
dd 1
god 1
hahaha 1
hello 6
is 2
jack 1
jim 1
my 1
rubbish 1
附:统计文本中记录条数的代码:
package com.darrenchan.hadoop; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Count {
public static class CountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 封装数据为kv并输出
context.write(new Text("count"), new LongWritable(1));
} } public static class CountReducer extends Reducer<Text, LongWritable, NullWritable, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, NullWritable, LongWritable>.Context context)
throws IOException, InterruptedException {
long sum = 0; for (LongWritable value : values) {
sum += value.get();
}
context.write(NullWritable.get(), new LongWritable(sum));
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(Count.class); job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
MapReduce机制的更多相关文章
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
- MapReduce 常见SQL模型解析
MapReduce应用场景 前一阵子参加炼数成金的MapReduce培训,培训中的作业例子比较有代表性,用于解释问题再好不过了.有一本国外的有关MR的教材,比较实用,点此下载. MR能解决什么问题?一 ...
- 大数据技术 - 通俗理解MapReduce之WordCount(二)
上一章我们搭建了分布式的 Hadoop 集群.本章我们介绍 Hadoop 框架中的一个核心模块 - MapReduce.MapReduce 是并行计算模块,顾名思义,它包含两个主要的阶段,map 阶段 ...
- Hadoop之MapReduce学习笔记(二)
主要内容: mapreduce编程模型再解释: ob提交方式: windows->yarn windows->local : linux->local linux->yarn: ...
- YARN机制
YARN是资源管理调度的机制,之前一直以来和MapReduce机制合在一起,之后才分开.正是因为YARN机制单独独立出来,才使得Hadoop框架更加具有普适性.MapReduce可以处理海量离线数据, ...
- 【MapReduce】经常使用计算模型具体解释
前一阵子參加炼数成金的MapReduce培训,培训中的作业样例比較有代表性,用于解释问题再好只是了. 有一本国外的有关MR的教材,比較有用.点此下载. 一.MapReduce应用场景 MR能解决什么问 ...
- 从零自学Hadoop(10):Hadoop1.x与Hadoop2.x
阅读目录 序 里程碑 Hadoop1.x与Hadoop2.x 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的 ...
- MongoDB学习笔记~环境搭建
回到目录 Redis学习笔记已经告一段落,Redis仓储也已经实现了,对于key/value结构的redis我更愿意使用它来实现数据集的缓存机制,而对于结构灵活,查询效率高的时候使用redis就有点不 ...
- Hadoop :map+shuffle+reduce和YARN笔记分享
今天做了一个hadoop分享,总结下来,包括mapreduce,及shuffle深度讲解,还有YARN框架的详细说明等. v\:* {behavior:url(#default#VML);} o\:* ...
随机推荐
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- JOptionPane的经常使用4种对话框
JOptionPane类有4个用于显示对话框的静态方法: 消息.选项.确认,输入对话框 showMessageDialog://显示一条消息并等待用户OK showConfirmDialog://显示 ...
- redis3.0.6安装配置
运行linux客户端 1 安装依赖 yum install gcc-c++ -y(安装gcc) 2 创建安装目录.编译.安装 mkdir -p /usr/local/redis(创建安 ...
- java中运算符与表达式
运算符是用来完成一个动作的特定语言的语法记号. –赋值运算符 –增减运算符 –算术运算符 –关系运算符 –逻辑运算符 -位运算符 运算符 Java 加 + 减 - 乘 * 除 / 取模 % 1.整数运 ...
- 【一步一步走(1)】远程桌面软件VNC的安装与配置
近期在VPS上搭建Python Web环境.走了非常多弯路,借此记下. 先说说购买的VPS(PhotonVPS),我可不是打广告.仅仅是感觉这个VPS服务提供商还不错推荐给你大家,我之前也是体验过阿里 ...
- vue1.0 的过滤器
vue1.0 自带的过滤器: 一 .过滤器写法 {{ message | Filter}} 二. Vue自带的过滤器:capitalize 功能:首字母大写 <!DOCTYPE html> ...
- TX2 ROS IDE开发环境配置
参考资料: http://www.mamicode.com/info-detail-1663827.html 基于Qt搭建ROS开发环境 https://blog.csdn.net/sbtxg/ ...
- 08-session详解
如何获取session对象? 1,openSession 2,getCurrentSession 如果使用getCurrentSession需要在hibernate.cfg.xml文件中进行配置: 如 ...
- java基础讲解01-----简单了解一下java
2017-4-12(晚) 闲来无事,静静把自己了解的java,好好回忆一次.如果能帮助别人也好.会不断补充 java有关的书籍真的很多,我也不过多的介绍了. 1.什么是java 2.java的语言特 ...
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
来源:NIPS 2013 作者:DeepMind 理解基础: 增强学习基本知识 深度学习 特别是卷积神经网络的基本知识 创新点:第一个将深度学习模型与增强学习结合在一起从而成功地直接从高维的输入学习控 ...