第7章 YARN HA配置
ResourceManager (RM)负责跟踪集群中的资源,以及调度应用程序(例如,MapReduce作业)。在Hadoop 2.4之前,集群中只有一个ResourceManager,当其中一个宕机时,将影响整个集群。高可用性特性增加了冗余的形式,即一个主动/备用的ResourceManager对,以便可以进行故障转移。
YARN HA的架构如下图所示:
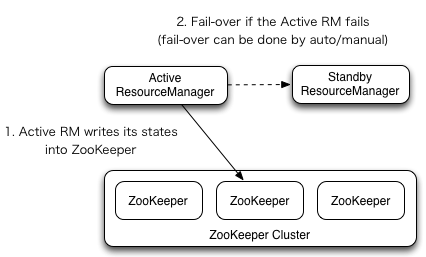
本例中,各节点的角色分配如下表所示:
| 节点 | 角色 |
|---|---|
| centos01 | ResourceManager NodeManager |
| centos02 | ResourceManager NodeManager |
| centos03 | NodeManager |
下面将逐步讲解YARN HA的配置步骤。
7.1 yarn-site.xm文件配置
(1)修改yarn-site.xm文件,加入以下内容:
点击展开内容
<!--YARN HA配置-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>centos01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>centos02</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>centos01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>centos02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>centos01:2181,centos02:2181,centos03:2181</value>
</property>
<property><!--启用RM重启的功能,默认为false-->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
上述配置参数解析:
yarn.resourcemanager.ha.enabled:开启RM HA功能。
yarn.resourcemanager.cluster-id:标识集群中的RM。如果设置该选项,需要确保所有的RMs在配置中都有自己的id。
yarn.resourcemanager.ha.rm-ids:RMs的逻辑id列表。可以自定义,此处设置为“rm1,rm2”。后面的配置将引用该id。
yarn.resourcemanager.hostname.rm1:指定RM对应的主机名。另外,可以设置RM的每个服务地址。
yarn.resourcemanager.webapp.address.rm1:指定RM的Web端访问地址。
yarn.resourcemanager.zk-address:指定集成的ZooKeeper的服务地址。
yarn.resourcemanager.recovery.enabled:启用RM重启的功能,默认为false。
yarn.resourcemanager.store.class:用于状态存储的类,默认为org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore,基于Hadoop文件系统的实现。还可以为org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore,该类为基于ZooKeeper的实现。此处指定该类。
(2)yarn-site.xm文件配置好后,需要将其发送到集群中其它节点。
(3)接着上一章启动好的HDFS,继续进行启动YARN。
分别在centos01、centos02节点上执行以下命令,启动ResourceManager:
[hadoop@centos01 hadoop-2.7.1]$ sbin/yarn-daemon.sh start resourcemanager
分别在centos01、centos02、centos03节点上执行以下命令,启动nodemanager:
[hadoop@centos01 hadoop-2.7.1]$ sbin/yarn-daemon.sh start nodemanager
(4)YARN启动后,查看各节点Java进程:
[hadoop@centos01 hadoop-2.7.1]$ jps
3360 QuorumPeerMain
4080 DFSZKFailoverController
4321 NodeManager
4834 Jps
3908 JournalNode
3702 DataNode
4541 ResourceManager
3582 NameNode
[hadoop@centos02 hadoop-2.7.1]$ jps
4486 Jps
3815 DFSZKFailoverController
4071 NodeManager
4359 ResourceManager
3480 NameNode
3353 QuorumPeerMain
3657 JournalNode
3563 DataNode
[hadoop@centos03 hadoop-2.7.1]$ jps
3496 JournalNode
4104 Jps
3836 NodeManager
3293 QuorumPeerMain
3390 DataNode
此时浏览器输入地址http://centos01:8088 访问活动状态的ResourceManager,查看YARN的启动状态。如下图所示。
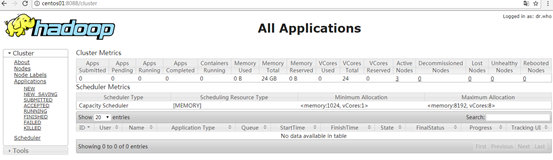
如果访问备份ResourceManager地址:http://centos02:8088 发现自动跳转到了地址http://centos01:8088。这是因为此时活动状态的ResourceManager在centos01节点上。访问备份节点的ResourceManager会自动跳转到活动节点。
7.2 测试YARN自动故障转移
在centos01节点上执行MapReduce默认的WordCount程序,当正在执行map阶段时,新开一个SSH Shell窗口,杀掉centos01的ResourceManager进程,观察程序执行过程。执行MapReduce默认的WordCount程序的命令如下:
[hadoop@centos01 hadoop-2.7.1]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output
执行结果如下:
[hadoop@centos01 hadoop-2.7.1]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output
18/03/16 10:48:22 INFO input.FileInputFormat: Total input paths to process : 1
18/03/16 10:48:22 INFO mapreduce.JobSubmitter: number of splits:1
18/03/16 10:48:23 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1521168402181_0001
18/03/16 10:48:23 INFO impl.YarnClientImpl: Submitted application application_1521168402181_0001
18/03/16 10:48:23 INFO mapreduce.Job: The url to track the job: http://centos01:8088/proxy/application_1521168402181_0001/
18/03/16 10:48:23 INFO mapreduce.Job: Running job: job_1521168402181_0001
18/03/16 10:48:56 INFO mapreduce.Job: Job job_1521168402181_0001 running in uber mode : false
18/03/16 10:48:57 INFO mapreduce.Job: map 0% reduce 0%
18/03/16 10:50:21 INFO mapreduce.Job: map 100% reduce 0%
18/03/16 10:50:32 INFO mapreduce.Job: map 100% reduce 100%
18/03/16 10:50:36 INFO mapreduce.Job: Job job_1521168402181_0001 completed successfully
18/03/16 10:50:37 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1321
FILE: Number of bytes written=239335
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1094
HDFS: Number of bytes written=971
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=14130
Total time spent by all reduces in occupied slots (ms)=7851
Total time spent by all map tasks (ms)=14130
Total time spent by all reduce tasks (ms)=7851
Total vcore-seconds taken by all map tasks=14130
Total vcore-seconds taken by all reduce tasks=7851
Total megabyte-seconds taken by all map tasks=14469120
Total megabyte-seconds taken by all reduce tasks=8039424
Map-Reduce Framework
Map input records=29
Map output records=109
Map output bytes=1368
Map output materialized bytes=1321
Input split bytes=101
Combine input records=109
Combine output records=86
Reduce input groups=86
Reduce shuffle bytes=1321
Reduce input records=86
Reduce output records=86
Spilled Records=172
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=188
CPU time spent (ms)=1560
Physical memory (bytes) snapshot=278478848
Virtual memory (bytes) snapshot=4195344384
Total committed heap usage (bytes)=140480512
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=993
File Output Format Counters
Bytes Written=971
从上述结果中可以看出,虽然ResourceManager进程被杀掉了,但是YARN仍然能够流畅的执行,说明自动故障转移功能生效了,ResourceManager遇到故障后,自动切换到了centos02节点上继续执行。此时浏览器访问备用ResourceManager的Web端地址http://centos02:8088发现可以成功访问了。显示任务成功执行完毕。
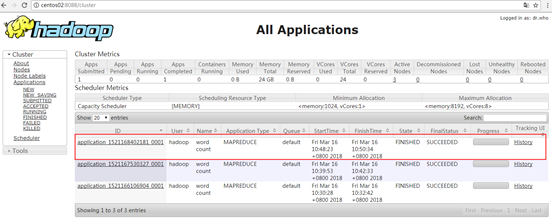
到此,YARN HA集群搭建完毕。
第7章 YARN HA配置的更多相关文章
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- Hadoop2.4.1 64-Bit QJM HA and YARN HA + Zookeeper-3.4.6 + Hbase-0.98.8-hadoop2-bin HA Install
Hadoop2.4.1 64-Bit QJM HA and YARN HA Install + Zookeeper-3.4.6 + Hbase-0.98.8-hadoop2-bin HA(Hadoop ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置HA配置
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置及HA配置(待)
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
- CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- Hadoop 管理工具HUE配置-Yarn Resource Manager HA配置
安装HUE之后,需要配置很多东西才能将这个系统的功能发挥出来,因为Yarn是配置的HA模式,所以在配置HUE的时候,会有些不用,下面一段文字是官网拿来的 # Configuration for YAR ...
- 第九章 搭建Hadoop 2.2.0版本HDFS的HA配置
Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作.在hadoop1时代,只有一个NameNode.如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了.这是 ...
- 企业级hbase HA配置
1 HBase介绍HBase是一个分布式的.面向列的开源数据库,就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类 ...
- HAWQ集成Yarn HA作为资源管理服务
一.第一步当然是配置YARN HA,这在使用ambari管理时很简单,这里不在赘述. 二.建立HAWQ的专用资源队列queue 不要手工编辑scheduler设置,最方便的当然是使用queue man ...
随机推荐
- Linux ->> Chmod命令改变文件/文件夹属性
简介 chmod命令用于改变linux系统文件或目录的访问权限,控制用户/用户组对文件或目录的访问权限. 用法: 两种用法:1)用字母r(读).w(写).x(执行)表示权限类型:2)用数字表示,4代表 ...
- 安装Access Database Engine后,提示未注册Microsoft.ACE.OLEDB.12.0
未注册Microsoft.ACE.OLEDB.12.0 ,下载安装 Microsoft Access Database Engine:https://www.microsoft.com/en-us/d ...
- ASPNET MVC Error 500.19
今天创建了一个新的ASPNET MVC 项目部署到本地, 生成成功后在浏览器中输入URL却发现报这个错 参照下面的文章我给IIS_IUSRS和IUSR(我比较懒直接everyone)赋予虚拟目录读写权 ...
- Linux文件系统检查错误
我们的Linux系统在无法启动时候,通常需要进入单用户模式下进行修改一些配置文件,或调整一些参数方可.但是在进入单用户模式后,我们的/文件系统是只读模式,无法进行修改,那么这个时候我们就需要用到一条命 ...
- tree结构统一修改属性名(递归)
1 //data为需要修改的tree,这里主要是为antd design 里面select规范数据 const ass = (data) => { let item = []; data.map ...
- GO语言(八) defer注意点
package main import ( "net" "os" "fmt" "io/ioutil" ) func Cl ...
- 移动端适配插件(flexible.js)
;(function(win, lib) { var doc = win.document; var docEl = doc.documentElement; var metaEl = doc.que ...
- 洛谷 P3175 [HAOI2015]按位或
题目分析 与hdu4336 Card Collector相似,使用min-max容斥. 设\(\max(S)\)表示集合\(S\)中最后一位出现的期望时间. 设\(\min(S)\)表示集合\(S\) ...
- xalan\xalan\2.7.2\xercesImpl.jar (系统找不到指定的文件)问题
本文转自:http://blog.csdn.net/lveliu/article/details/77772828 环境搭建为:maven+tomcat tomcat 8.5.2 以上会出现改问题(包 ...
- 2019.1.2 Spring管理事务的方式
Spring管理事务的方式 1.编码式 1.将核心事务管理器配置到Spring容器 2.配置TransactionTemplate模版 3.将事务模版注入service 4.在Service中调用模版 ...