第四模块:网络编程进阶&数据库开发 第1章·网络编程进阶
- 01-进程与程序的概念
- 02-操作系统介绍
- 03-操作系统发展历史-第一代计算机
- 04-操作系统发展历史-批处理系统
- 05-操作系统发展历史-多道技术
- 06-操作系统发展历史-分时操作系统
- 07-总结操作系统功能与多道技术
- 08-进程理论
- 09-开启子进程的两种方式
- 10-查看进程的pid与ppid
- 11-僵尸进程与孤儿进程
- 12-Process对象的其他属性或方法
- 13-练习题讲解
- 14-守护进程
- 15-互斥锁
- 16-模拟抢票
- 17-互斥锁与join的区别
- 18-队列的使用
- 19-生产者消费者模型
- 20-JoinableQueue的使用
- 21-什么是线程
- 22-开启线程的两种方式
- 23-进程与线程的区别
- 24-Thread对象的其他属性或方法
- 25-守护线程
- 26-互斥锁
- 27-GIL的基本概念
- 28-GIL与互斥锁的区别
- 29-GIL与多线程
- 30-死锁与递归锁
- 31-信号量
- 32-Event事件
- 33-定时器
- 34-线程queue
- 35-多线程实现并发的套接字通信
- 36-进程池线程池
- 37-异步调用与回调机制
- 38-进程池线程池小练习
- 39-协程介绍
- 40-greenlet模块
- 41-greenlet模块
- 42-gevent模块
- 43-gevent异步提交任务
- 44-基于gevent模块实现并发的套接字通信
- 45-IO模型介绍
- 46-阻塞IO模型
- 47-非阻塞IO模型
- 48-多路复用IO模型
- 49-异步IO模型
01-进程与程序的概念
1、进程,即正在执行的一个过程,是一个抽象的概念,起源于操作系统,是操作系统的核心概念,也是操作系统提供的最古老也是最为重要的抽象概念之一;
2、操作系统的其他所有内容都是围绕进程的概念展开的;
02-操作系统介绍
1、操作系统的作用;
- 隐藏丑陋的硬件接口,提供良好的抽象接口;
- 管理、调度进程,并且将多个进程对硬件的竞争变得有序;

03-操作系统发展历史-第一代计算机
1、操作系统发展史;
1)第一代计算机(1940~1955)
- 特点:没有操作系统的概念;也没有编程语言的概念;所有的程序设计都是直接操作硬件;
- 优点:程序员在申请的时间段内独享整个资源,可以即时地调试自己的程序(有Bug可以及时处理)
- 缺点:浪费计算资源,一个时间段里只能有一个人用;注意:同一时刻只有一个程序在内存中,被CPU调用执行,比方说10个程序的执行,都是串行的;
04-操作系统发展历史-批处理系统
1、第二代计算机(1955~1965):晶体管和批处理系统
05-操作系统发展历史-多道技术
06-操作系统发展历史-分时操作系统
07-总结操作系统功能与多道技术
08-进程理论
09-开启子进程的两种方式
1、multiprocessing模块介绍;
2、Process类的介绍;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 4:14 PM
""
"""
开启子进程的两种方式
"""
#开启进程的方式1:
from multiprocessing import Process
import time def task(name):
"""
任务函数
:param name:
:return:
"""
print('%s is running'%name)
time.sleep(3)
print('%s is done'%name) if __name__ == '__main__':
#Process(target= task, kwargs={'name':'子进程1'})
p = Process(target = task, args = ('子进程1',))
p.start()#仅仅只是给操作系统发送了一个信号;
print('主')
"""
主
子进程1 is running
子进程1 is done
""" """
开启进程的方式2:
"""
from multiprocessing import Process
import time class MyProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name def run(self):#默认必须叫做run
print('%s in running'%self.name)
time.sleep(3)
print('%s is done'%self.name) if __name__ == '__main__':
p = MyProcess('子进程1')
p.start()
print('主')
"""
主
子进程1 in running
子进程1 is done
"""
10-查看进程的pid与ppid
1、pid即process id(进程号)
2、ppid即parent process id(父进程号)
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 4:52 PM
""
"""
10-查看进程的pid与ppid
操作系统管理进行,使用pid号,类似人类的身份证号;
"""
from multiprocessing import Process
import time
import os def task():
print('%s is running,partent id is <%s>'%(os.getpid(),os.getppid()))
time.sleep(3)
print('%s is done,partent id is <%s>'%(os.getpid(),os.getppid())) if __name__ == '__main__':
#p = Process(target= task, args=('子进程1'))#TypeError: task() takes 0 positional arguments but 4 were given
p = Process(target= task,)
p.start() print('主%s,partent id is <%s>'%(os.getpid(),os.getppid()))
"""
主 12040
16924 is running
16924 is done
----------------------
主888,partent id is <14600>
19400 is running,partent id is <888>
19400 is done,partent id is <888>
-----------------------------------
C:\\Users\\TQTL911>tasklist |findstr pycharm
pycharm64.exe 14600 Console 6 823,488 K C:\\Users\\TQTL911>
"""
11-僵尸进程与孤儿进程
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 5:07 PM
""
"""
11-僵尸进程与孤儿进程;
此内容了解为主;
1、僵尸进程,即子进程被杀死后的状态,方便于父进程查看一些状态信息,但他是有害的;
2、孤儿进程,即父进程终止后,保存的子进程,但会交由祖宗进程init(所有进程的起点,即孤儿院)去进行管理,它是无害的;
"""
12-Process对象的其他属性或方法
1、join方法;
2、Process对象的其他属性或方法;terminate与is_alive以及name与pid
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 5:17 PM
""
"""
12-Process对象的其他属性或方法 """
#1、join方法讲解
from multiprocessing import Process
import time
import os
import random def task():
print('%s is running,The parent id is <%s>'%(os.getpid(),os.getppid()))
time.sleep(random.randrange(1,5))
print('%s is down,The parent id is <%s>'%(os.getpid(),os.getppid())) if __name__ == '__main__':
p = Process(target=task,)
p.start() p.join()#保证等待子进程执行结束,父进程才执行
print('主',os.getpid(),os.getppid())
print(p.pid)
#2、引入join方法
from multiprocessing import Process
import time
import os
import random def task(name):
print('%s is running'%name)
time.sleep(random.randrange(1,3)) if __name__ == '__main__':
p1 = Process(target=task,args=('子进程1',))
p2 = Process(target=task,args=('子进程2',))
p3 = Process(target=task,args=('子进程3',))
p4 = Process(target=task,args=('子进程4',))
p1.start()#只是发个信号给操作系统,至于CPU执行的顺序,由操作系统来分配;
p2.start()
p3.start()
p4.start() p1.join()#保证等待子进程执行结束,父进程才执行
p2.join()#保证等待子进程执行结束,父进程才执行
p3.join()#保证等待子进程执行结束,父进程才执行
p4.join()#保证等待子进程执行结束,父进程才执行
print('主',os.getpid(),os.getppid())
"""
1、未曾使用join方法的时候,执行的顺序如下所示:
主 14188 14600
子进程1 is running
子进程3 is running
子进程2 is running
子进程4 is running
2、使用了join方法之后,执行的顺序如下所示:
子进程1 is running
子进程2 is running
子进程3 is running
子进程4 is running
主 2564 14600
""" #3、并行执行程序;
from multiprocessing import Process
import os
import random
import time def task(name,n):
print('%s is runing'%name,10)
time.sleep(n) if __name__ == '__main__':
start = time.time()
p1 = Process(target= task, args=('子进程1',5))
p2 = Process(target= task, args=('子进程2',3))
p3 = Process(target= task, args=('子进程3',2)) p1.start()
p2.start()
p3.start() p1.join()
p2.join()
p3.join()
print('主',(time.time() - start))
"""
子进程1 is runing 10
子进程3 is runing 10
子进程2 is runing 10
主 5.093375205993652
""" #4、变成串行方式执行程序;
from multiprocessing import Process
import os
import time def task(name,n):
print('%s is running'%name,n)
time.sleep(n) if __name__ == '__main__':
start = time.time()
# p1 = Process(target= task,args=('子进程1',5),)
# p2 = Process(target= task,args=('子进程2',1),)
# p3 = Process(target= task,args=('子进程3',2),)
#
# p1.start()
# p1.join()
# p2.start()
# p2.join()
# p3.start()
# p3.join()
#对以上内容的简写
p1 = Process(target=task, args=('子进程1', 5), )
p2 = Process(target=task, args=('子进程2', 1), )
p3 = Process(target=task, args=('子进程3', 2), )
p_l = [p1,p2,p3]
for p in p_l:
p.start()
for p in p_l:
#p.join()#TabError: inconsistent use of tabs and spaces in indentation
p.join()
#print('主',time.time() - start)#NameError: name 'start' is not defined
print('主',time.time() - start)
"""
子进程1 is running 5
子进程2 is running 1
子进程3 is running 2
主 8.224236726760864
""" #小结
from multiprocessing import Process
import os
import time
import random def task():
print('%s is runing,The parent id is <%s>'%(os.getpid(),os.getppid()))
time.sleep(random.randrange(1,3))
print('%s is done,The parent id is <%s>'%(os.getpid(),os.getppid())) if __name__ == '__main__':#尽可能手写,不使用main自动生成,会出现tab != 4个空格的坑呀!
# p = Process(target= task,)
# p.start()
# p.join()
# print('主',os.getpid(),os.getppid())
# print(p.pid)
# print(p.is_alive())#布尔值False or True
p = Process(target=task,)
p.start()
p.terminate()
time.sleep(3)#加上时间后,is_alive将会变成False
print(p.is_alive())#True
print('主',os.getpid(),os.getppid())
13-练习题讲解
1、改写下列程序,分别别实现下述打印效果;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 6:53 PM
from multiprocessing import Process
import time
import random def task(n):
time.sleep(random.randrange(1,3))
print('--------->%s'%n) if __name__ == '__main__':
p1 = Process(target=task,args=(1,))
p2 = Process(target=task,args=(2,))
p3 = Process(target=task,args=(3,))
# Req1:最先保证输出--------->4
p1.start()
p2.start()
p3.start()
print('最先保证输出--------->4') #Req2:保证最后输出--------->4
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print('保证最后输出--------->4') #Req3:保证按顺序输出--------->4
#如下写,变成串行,失去并发的意义,没有意义,为了练习join方法的使用;
p1.start()
p1.join()
p2.start()
p1.join()
p3.start()
p1.join()
print('保证按顺序输出--------->4')
2、基于多进程实现并发套接字通信;
1)server端;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 6:37 PM
from socket import *
from multiprocessing import Process def talk(conn):
while True:
try:
data = conn.recv(1024)
if not data:break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close() def server(ip,port):
server = socket(AF_INET,SOCK_STREAM)
server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server.bind((ip,port))#注意此处为元组形式的ip_port:(ip,port)
server.listen(5) while True:
conn,addr = server.accept()
p = Process(target=talk,args=(conn,))
p.start() server.close() if __name__ == '__main__':
server('127.0.0.1',9011)
2)client端;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/18/2018 6:37 PM from socket import * client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',9011)) while True:
msg = input('>>>:').strip()
if not msg:continue client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
14-守护进程
1、守护进程初识;
- 守护进程会在主进程代码执行结束后就终止;
- 守护进程内无法再开启子进程,否则抛出异常;AssertionError: daemonic processes are not allowed to have children
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 8:26 AM
""
"""
守护进程-伴随着父进程而消失;
"""
from multiprocessing import Process
import time
import random def task(name):
print('%s is running'%name)
time.sleep(random.randrange(1,3)) # p = Process(target=time.sleep,args=(3,))
# p.start()#AssertionError: daemonic processes are not allowed to have children if __name__ == '__main__':
p = Process(target=task,args=('子进程1',))
p.daemon = True
p.start() p.join()
print('主进程') #练习题;
from multiprocessing import Process import time
def foo():
print(123)
time.sleep(1)
print("end123") def bar():
print(456)
time.sleep(3)
print("end456") if __name__ == '__main__':
p1=Process(target=foo)
p2=Process(target=bar) p1.daemon=True#一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行
p1.start()
p2.start()
print("main-------")
"""
main-------#只要碰到main,就不会出现123和end123;
456
end456
"""
15-互斥锁
1、互斥锁初识;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 8:44 AM
""
"""
互斥锁-互相排斥,比如生活中去卫生间,关上门,其他人必须等待;
互斥锁的原理-把并发改成串行,降低了效率,但是保证了数据安全不错乱;
"""
from multiprocessing import Process,Lock
import time
import random """
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,
或同一个打印终端,是没有问题的,而共享带来的是竞争,
竞争带来的结果就是错乱,如下:
"""
def task(name,mutex):#mutex互斥的意思;
mutex.acquire()#获取锁;
print('%s 1'%name)
time.sleep(random.randrange(1,2))
print('%s 2'%name)
time.sleep(random.randrange(1,2))
print('%s 3'%name)
mutex.release()#释放锁; if __name__ == '__main__':
mutex = Lock()#生成锁
for i in range(3):
p = Process(target=task,args=('进程%s'%i,mutex))
p.start()
"""
1、未引入互斥锁
进程0 1
进程1 1
进程2 1
进程0 2
进程1 2
进程2 2
进程0 3
进程1 3
进程2 3
2、引入互斥锁
进程0 1
进程0 2
进程0 3
进程1 1
进程1 2
进程1 3
进程2 1
进程2 2
进程2 3
"""
16-模拟抢票
1、初次模拟抢票程序;(多个进程共享同一文件,我们可以把文件当数据库,用多个进程模拟多个人执行抢票任务)
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 8:55 AM
""
"""
16-模拟抢票
"""
from multiprocessing import Process,Lock
import time
import random
import json def search(name):
time.sleep(random.randrange(1,2))
dic = json.load(open('db.txt','r',encoding='utf-8'))
print('<%s> 查看到剩余票数[%s]'%(name,dic['count'])) def get(name):
time.sleep(random.randrange(1,2))#模拟读取数据的网络延迟:
dic = json.load(open('db.txt','r',encoding = 'utf-8'))
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(2)
json.dump(dic,open('db.txt','w',encoding='utf-8'))
print('<%s>购票成功'%name) def task(name):
search(name)
get(name) if __name__ == '__main__':
for i in range(10):
p = Process(target = task,args=('路人%s'%i,))
p.start()
"""
<路人0> 查看到剩余票数[1]
<路人1> 查看到剩余票数[1]
<路人2> 查看到剩余票数[1]
<路人4> 查看到剩余票数[1]
<路人3> 查看到剩余票数[1]
<路人6> 查看到剩余票数[1]
<路人5> 查看到剩余票数[1]
<路人7> 查看到剩余票数[1]
<路人8> 查看到剩余票数[1]
<路人9> 查看到剩余票数[1]
<路人0>购票成功
<路人1>购票成功
<路人2>购票成功
<路人4>购票成功
<路人3>购票成功
<路人6>购票成功
<路人5>购票成功
<路人7>购票成功
<路人8>购票成功
<路人9>购票成功
""" #加锁处理:购票行为由并发变成了串行,牺牲了运行效率,但保证了数据安全
from multiprocessing import Process,Lock
import time
import random
import json def search(name):
time.sleep(random.randrange(1,2))
dic = json.load(open('db.txt','r',encoding='utf-8'))
print('<%s> 查看到剩余票数[%s]'%(name,dic['count'])) def get(name):
time.sleep(random.randrange(1,2))#模拟读取数据的网络延迟:
dic = json.load(open('db.txt','r',encoding = 'utf-8'))
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(2)
json.dump(dic,open('db.txt','w',encoding='utf-8'))
print('<%s>购票成功'%name) def task(name,mutex):
#mutex.acquire()#此处,注意加锁的顺序;
search(name)
mutex.acquire()
get(name)
mutex.release()
"""
<路人0> 查看到剩余票数[1]
<路人0>购票成功
<路人1> 查看到剩余票数[0]
<路人2> 查看到剩余票数[0]
<路人3> 查看到剩余票数[0]
<路人4> 查看到剩余票数[0]
<路人5> 查看到剩余票数[0]
<路人8> 查看到剩余票数[0]
<路人7> 查看到剩余票数[0]
<路人6> 查看到剩余票数[0]
<路人9> 查看到剩余票数[0]
""" if __name__ == '__main__':
mutex = Lock()
for i in range(10):
p = Process(target = task,args=('路人%s'%i,mutex))
p.start()
"""
<路人2> 查看到剩余票数[1]
<路人0> 查看到剩余票数[1]
<路人3> 查看到剩余票数[1]
<路人7> 查看到剩余票数[1]
<路人1> 查看到剩余票数[1]
<路人6> 查看到剩余票数[1]
<路人5> 查看到剩余票数[1]
<路人8> 查看到剩余票数[1]
<路人9> 查看到剩余票数[1]
<路人4> 查看到剩余票数[1]
<路人2>购票成功
"""
17-互斥锁与join的区别
1、互斥锁与join均可以将并发变成串行,为何还要使用互斥锁呢?
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 9:49 AM
from multiprocessing import Process,Lock
import time
import random
import json def search(name):
time.sleep(random.randrange(1,2))
dic = json.load(open('db.txt','r',encoding='utf-8'))
print('<%s> 查看到剩余票数[%s]'%(name,dic['count'])) def get(name):
time.sleep(random.randrange(1,2))#模拟读取数据的网络延迟:
dic = json.load(open('db.txt','r',encoding = 'utf-8'))
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(2)
json.dump(dic,open('db.txt','w',encoding='utf-8'))
print('<%s>购票成功'%name)
else:
print('<%s>购票失败'%name) def task(name,):
#mutex.acquire()
search(name)
#mutex.acquire()
get(name)
#mutex.release()
if __name__ == '__main__':
#mutex = Lock()
for i in range(10):
p = Process(target = task,args=('路人%s'%i,))#args传值为元组,带有逗号
p.start()
p.join()
"""
<路人0> 查看到剩余票数[1]
<路人0>购票成功
<路人1> 查看到剩余票数[0]
<路人1>购票失败
<路人2> 查看到剩余票数[0]
<路人2>购票失败
<路人3> 查看到剩余票数[0]
<路人3>购票失败
<路人4> 查看到剩余票数[0]
<路人4>购票失败
<路人5> 查看到剩余票数[0]
<路人5>购票失败
<路人6> 查看到剩余票数[0]
<路人6>购票失败
<路人7> 查看到剩余票数[0]
<路人7>购票失败
<路人8> 查看到剩余票数[0]
<路人8>购票失败
<路人9> 查看到剩余票数[0]
<路人9>购票失败
""" #小结:
"""
1、发现使用join方法后,将并发改为串行,确实能保证数据安全,但问题连查票操作也
变成只能一个一个去查了,很明显,大家查票的时候应该是并发地去查询
而无需考虑数据正确与否,此时join与互斥锁的区别就显而易见了。
2、join是将一个任务整体串行,而互斥锁的好处则是将一个任务中的某一行代码串行,比如只让
task函数的get任务串行; def task(name,):
search(name)#并发执行 Lock.acquire()
get(name)#串行执行
Lock.release()
"""
18-队列的使用
1、队列初识;
进程彼此之间互相隔离,要实现进程间通信(IPC),multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的;
1)创建队列的类(底层就是以管道和锁定的方式实现的)
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
2)Queue的参数介绍;
maxsize是队列中允许最大项数,省略则无大小限制。
但需要明确:
1、队列内存放的是消息而非大数据
2、队列占用的是内存空间,因而maxsize即便是无大小限制也受限于内存大小
3)主要方法介绍
q = Queue(n)
q.put方法用以插入数据到队列中。
q.get方法可以从队列读取并且删除一个元素。
4)队列的使用
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 10:04 AM
""
"""
掌握队列的使用-先进先出的原则
"""
from multiprocessing import Queue q = Queue(3)#设置队列数为3,注意:队列中不能放置大文件,而应该是精简的消息;
q.put('hello')
q.put({'a':1})
q.put([1,2,3,4])
#q.put(4)
print(q.get())
print(q.get())
print(q.get()) print(q.empty())#清空队列操作;返回值为True;
#print(q.get())#当队列中的数据被取空之后,再次get,程序将一直停留在这里;
19-生产者消费者模型
1、为什么要使用生产者消费者模型?
生产者指的是生产数据的任务,消费者指的是处理数据的任务,在并发编程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
2、什么是生产者和消费者模式?
这里强调:生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。 注意:这个阻塞队列就是用来给生产者和消费者解耦的
3、生产者消费者模型实现;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 10:11 AM
""
"""
19-生产者消费者模型
"""
import time def producter():
for i in range(3):
res = '包子%s'%i
print('生产者生产了%s'%res)
consumer(res) def consumer(res):
time.sleep(1)
print('消费者吃了%s'%res)
producter()
"""
生产者生产了包子0
消费者吃了包子0
生产者生产了包子1
消费者吃了包子1
生产者生产了包子2
消费者吃了包子2
"""
"""
#生产者与消费者之间彼此可能等待对方;
#引入生产者消费者模型,在生产者与消费者之间引入一个“容器”,类似于缓存的作用;
#好处之一:解耦合;
#好处之二平衡了消费者和生产者之间的不对等的能力:
""" from multiprocessing import Process,Queue
import time def producter(q):
for i in range(10):
res = '包子%s'%i
time.sleep(0.5)#模拟生产消耗的时间
print('生产者生产了%s'%res)
q.put(res) def consumer(q):
while True:
res = q.get()
time.sleep(1)
print('消费者吃了%s'%res) if __name__ == '__main__':
#中间的容器
q = Queue()
#生产者
p1 = Process(target=producter,args=(q,))
#消费者们
c1 = Process(target=consumer,args=(q,))
p1.start()
c1.start()
print('主')
"""
主
生产者生产了包子0
生产者生产了包子1
生产者生产了包子2
消费者吃了包子0
生产者生产了包子3
消费者吃了包子1
生产者生产了包子4
生产者生产了包子5
消费者吃了包子2
生产者生产了包子6
生产者生产了包子7
消费者吃了包子3
生产者生产了包子8
生产者生产了包子9
消费者吃了包子4
消费者吃了包子5
消费者吃了包子6
消费者吃了包子7
消费者吃了包子8
消费者吃了包子9 引入了队列的概念,生产者与消费者之间互不影响;但以上会出现消费者持续等待的情景
""" """
生产者生产了包子0
生产者生产了包子1
消费者吃了包子0
生产者生产了包子2
生产者生产了包子3
生产者生产了包子4
消费者吃了包子1
生产者生产了包子5
消费者吃了包子2
生产者生产了包子6
生产者生产了包子7
消费者吃了包子3
生产者生产了包子8
生产者生产了包子9
主
消费者吃了包子4
消费者吃了包子5
消费者吃了包子6
消费者吃了包子7
消费者吃了包子8
消费者吃了包子9 Process finished with exit code 0
"""
#生产者有多个;
from multiprocessing import Process,Queue
import time def producter(q):
for i in range(10):
res = '包子%s'%i
time.sleep(0.5)#模拟生产消耗的时间
print('生产者生产了%s'%res)
q.put(res) def consumer(q):
while True:
res = q.get()
if res is None:break
time.sleep(1)
print('消费者吃了%s'%res) if __name__ == '__main__':
#中间的容器
q = Queue()
#生产者
p1 = Process(target=producter,args=(q,))
p2 = Process(target=producter,args=(q,))
p3 = Process(target=producter,args=(q,))
p4 = Process(target=producter,args=(q,))
#消费者们
c1 = Process(target=consumer,args=(q,))
c2 = Process(target=consumer,args=(q,))
c3 = Process(target=consumer,args=(q,)) p1.start()
p2.start()
p3.start()
p4.start()
c1.start()
c2.start()
c3.start() p1.join()
p2.join()
p3.join()
p4.join()
q.put(None)
q.put(None)
q.put(None)
print('主')
20-JoinableQueue的使用
1、引入JoinableQueue([maxsize]);
这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
2、JoinableQueue方法介绍;
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
3、基于JoinableQueue实现生产者消费者模型;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 11:24 AM
from multiprocessing import Process,JoinableQueue,Queue
import time
import random def producer(q):
for i in range(3):
res = '包子%s'%i
time.sleep(0.5)
print('生产了%s'%res)
q.put(res)
q.join()
def consumer(q):
while True:
res = q.get()
if res is None:break
time.sleep(1)
print('消费者吃了%s'%res)
q.task_done() if __name__ == '__main__':
#容器
q = JoinableQueue() p1 = Process(target=producer,args=(q,))
p2 = Process(target=producer,args=(q,))
p3 = Process(target=producer,args=(q,)) c1 = Process(target=consumer,args=(q,))
c2 = Process(target=consumer,args=(q,))
c1.daemon = True
c2.daemon = True
p1.start()
p2.start()
p3.start() c1.start()
c2.start() p1.join()
p2.join()
p3.join()
print('主')
"""
生产了包子0
生产了包子0
生产了包子0
生产了包子1
生产了包子1
生产了包子1
消费者吃了包子0
生产了包子2
消费者吃了包子0
生产了包子2
生产了包子2
消费者吃了包子0
消费者吃了包子1
消费者吃了包子1
消费者吃了包子1
消费者吃了包子2
消费者吃了包子2
消费者吃了包子2
主 Process finished with exit code 0
"""
21-什么是线程
1、什么是线程?
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于cpu),而一条流水线必须属于一个车间,一个车间的工作过程是一个进程,车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一条流水线。
小结:所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
2、什么是多线程?
多线程(即多个控制线程)的概念是,在一个进程中存在多个线程,多个线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
3、线程与进程的区别?
1) 来点儿英文范儿吧!
1、Threads share the address space of the process that created it; processes have their own address space.
2、Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
3、Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
4、New threads are easily created; new processes require duplication of the parent process.
5、Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
5、Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
2)算了,还是别装13了,直接上中文吧!
- 同一个进程内的多个线程共享该进程内的地址资源;
- 创建线程的开销要远小于创建进程的开销(创建一个进程,就是创建一个车间,涉及到申请空间,而且在该空间内建至少一条流水线,但创建线程,就只是在一个车间内造一条流水线,无需申请空间,所以创建开销小);
4、多线程应用举例:
1、开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。
2、只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
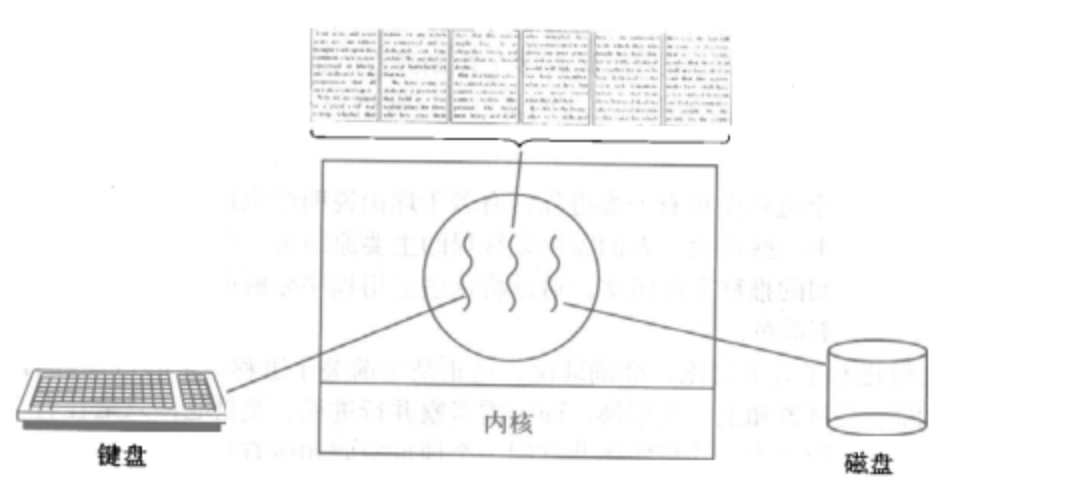
22-开启线程的两种方式
1、threading模块介绍;
threading与multiprocessing模块非常相似,具体见后者的用法章节;
2、开启线程的两种方式;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 11:53 AM
""
"""
22-开启线程的两种方式
"""
#回顾开进程的方式;
import time
import random
from multiprocessing import Process def piao(name):
print('%s piaoing'%name)
time.sleep(random.randrange(1,3))
print('%s piao ended'%name) if __name__ == '__main__':
p1 = Process(target=piao,args=('cuixiaozhao',))#必须加上,号
#调用对象下的方法,开启四个进程
p1.start()
print('主') #开启线程的方式1: import time
import random
from threading import Thread def piao(name):
print('%s piaoing'%name)
time.sleep(random.randrange(1,3))
print('%s piao ended'%name) if __name__ == '__main__':
t1 = Thread(target=piao,args=('cuixiaozhao',))#必须加上,号 t1.start()
print('主线程1') #开启线程的方式2
from threading import Thread
import time class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name = name def run(self):#默认必须叫做run
print('%s in running'%self.name)
time.sleep(3)
print('%s is done'%self.name) if __name__ == '__main__':
t = MyThread('子线程2')
t.start()
print('主线程2') """
小结:
1、起线程的两种方式与起进程的两种非常非常相似,几乎一模一样,就是把multiprocessing换成threading即可
2、明确清楚进程与线程的概念区别:
同一个进程内的多线线程共享该进程内的地址资源
创建线程的开销要远小于创建进程的开销(创建一个进程,就是创建一个车间,设计到申请空间,而且在该空间内建立至少与一条流水线(即默认开启一个线程);
但是创建线程,就是在一个车间内造出一个新的流水线,无需申请基础空间,所以创建开销小)
"""
23-进程与线程的区别
1、进程Process与线程Thread的区别;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 12:05 PM
""
"""
23-进程与线程的区别:
1、开进程的开销远大于开线程;
2、同一进程内的多个线程共享该进程的地址空间
"""
#区别1;
import time
import random
from threading import Thread
from multiprocessing import Process
def piao(name):
print('%s piaoing'%name)
time.sleep(random.randrange(1,3))
print('%s piao ended'%name) if __name__ == '__main__':
# p1 = Process(target=piao, args=('cuixiaozhao',))
# p1.start()
"""
主线程1
cuixiaozhao piaoing
cuixiaozhao piao ended
"""
t1 = Thread(target= piao,args=('cuitianqing',))
t1.start()
print('主线程1')
"""
cuitianqing piaoing
主线程1
cuitianqing piao ended
""" #区别2;
from threading import Thread
from multiprocessing import Process n = 100
def task2():
global n
n = 0 if __name__ == '__main__':
# p1 = Process(target=task2,)
# p1.start()
# p1.join()#等待子进程运行完成,结果为:主线程 100 t1 = Thread(target= task2,)
t1.start()#主线程 0
t1.join()
print('主线程',n) #区别3,瞅一眼pid
from threading import Thread
from multiprocessing import Process,current_process
import os def task3():
#print(current_process().pid)#7428
print('子进程PID:%s 父进程的PPID:%s'%(os.getpid(),os.getppid()))#子进程PID:7760 父进程的PPID:19624 if __name__ == '__main__':
# p1 = Process(target= task3,)
# p1.start()
t1 = Thread(target=task1,)
t1.start()
#print('主线程',current_process().pid)#主线程 19664
print('主进程',os.getpid())#主进程 7760 #区别4,瞅一眼pid
from threading import Thread
import os def task4():
print('子线程PID:%s '%(os.getpid()))#子线程PID:12248 if __name__ == '__main__':
t1 = Thread(target=task4,)
t1.start()
print('主线程',os.getpid())#主线程 12248 #注意:其实没有子线程PID,线程都是相同级别的,大家地位相等,为了便于理解,才在此处称之为:子线程;
24-Thread对象的其他属性或方法
1、方法介绍;
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。 threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
2、方法验证;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 5:12 PM
from threading import Thread,current_thread,active_count,enumerate
import time def task():
print('%s is runing'%current_thread().getName())
time.sleep(2)
print('%s is done'%current_thread().getName()) if __name__ == '__main__':
t = Thread(target= task,name='子线程1')
t.start()
#t.setName('儿子线程1')
#current_thread().setName('主线程')
#print(t.is_alive())#返回值为True或者False
#print(t.isAlive())#返回值为True或者False
#print(t.getName())
#print('主线程',current_thread().getName())
#t.join()
print(active_count())
print(enumerate())#[<_MainThread(MainThread, started 10096)>, <Thread(子线程1, started 14432)>]
25-守护线程
1、守护线程初识;
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁;
1)需要强调的是:运行完毕并非终止运行;
1、对主进程来说,运行完毕指的是主进程代码运行完毕; 2、对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕;
2)详细解释;
1、主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束; 2、主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束;
3)验证一下吧!
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 5:27 PM
""
"""
25-守护线程
"""
from threading import Thread
import time def sayhi(name):
time.sleep(1)
print('%s say hello'%name) if __name__ == '__main__':
t = Thread(target= sayhi,args= ('cuixiaozhao',))
#t.setDaemon(True)#必须在t.start()之前设置;
t.daemon = True #作用同上;
t.start() print('主线程')
#print(t.isAlive())
print(t.is_alive())#作用同上; from threading import Thread
import time def foo():
print(123)
time.sleep(1)
print('end123') def bar():
print(456)
time.sleep(3)
print('end456')
"""
123
456
--------main--------
end123
end456
""" if __name__ == '__main__':
t1 = Thread(target= foo)
t2 = Thread(target=bar) t1.daemon = True
t1.start()
t2.start()
print('main'.center(20,'-'))
26-互斥锁
1、互斥锁概念再次初识;
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __Author__:TQTL911
# Version:python3.6.6
# Time:7/20/2018 5:47 PM
""
"""
26-互斥锁-由并行改为串行,牺牲了性能,保证了数据安全; """
#mutex
from threading import Thread,Lock
import time n = 100
def task():
global n
mutex.acquire()
temp = n
time.sleep(0.1)
n = temp -1
mutex.release() if __name__ == '__main__':
mutex = Lock()#局部加锁
t_l = []
for i in range(100):
t = Thread(target= task,)
t_l.append(t)
t.start() for t in t_l:
t.join()
print('主',n)
"""
小结:
1、牺牲了效率;
2、保证了数据安全;
"""
27-GIL的基本概念
28-GIL与互斥锁的区别
29-GIL与多线程
30-死锁与递归锁
31-信号量
32-Event事件
33-定时器
34-线程queue
35-多线程实现并发的套接字通信
36-进程池线程池
37-异步调用与回调机制
38-进程池线程池小练习
39-协程介绍
40-greenlet模块
41-greenlet模块
42-gevent模块
43-gevent异步提交任务
44-基于gevent模块实现并发的套接字通信
45-IO模型介绍
46-阻塞IO模型
47-非阻塞IO模型
48-多路复用IO模型
49-异步IO模型
第四模块:网络编程进阶&数据库开发 第1章·网络编程进阶的更多相关文章
- 第四模块:网络编程进阶&数据库开发 第2章·MySQL数据库开发
01-MySQL开篇 02-MySQL简单介绍 03-不同平台下安装MySQL 04-Windows平台MySQL密码设置与破解 05-Linux平台MySQL密码设置与破解 06-Mac平台MySQ ...
- 第四模块:网络编程进阶&数据库开发 考核实战
1.什么是进程?什么是线程? 什么是协程? 进程:正在进行的一个过程或者说一个任务.而负责执行任务则是cpu. 线程:在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 协程是一种用 ...
- Java开发工程师(Web方向) - 03.数据库开发 - 第5章.MyBatis
第5章--MyBatis MyBatis入门 Abstract: 数据库框架的工作原理和使用方法(以MyBatis为例) 面向对象的世界与关系型数据库的鸿沟: 面向对象世界中的数据是对象: 关系型数据 ...
- 第四模块:网络编程进阶&数据库开发 练习
练习题 基于queue模块实现线程池 import threading from multiprocessing import Queue class A(threading.Thread): def ...
- 第四模块:网络编程进阶&数据库开发 口述
进程即正在执行的一个过程.进程是对正在运行程序的一个抽象. 子进程死了之后 ,父进程关闭的时候要清理掉子进程的僵尸进程(收尸),孤儿进程是指父进程先死掉了的,交给init管理. join() 等待子进 ...
- 《python核心编程》读书笔记--第16章 网络编程
在进行网络编程之前,先对网络以及互联网协议做一个了解. 推荐阮一峰的博客:(感谢) http://www.ruanyifeng.com/blog/2012/05/internet_protocol_s ...
- Java开发工程师(Web方向) - 03.数据库开发 - 第2章.数据库连接池
第2章--数据库连接池 数据库连接池 一般而言,在实际开发中,往往不是直接使用JDBC访问后端数据库,而是使用数据库连接池的机制去管理数据库连接,来实现对后端数据库的访问. 建立Java应用程序到后端 ...
- Java开发工程师(Web方向) - 03.数据库开发 - 第1章.JDBC
第1章--JDBC JDBC基础 通过Java Database Connectivity可以实现Java程序对后端数据库的访问 一个完整的数据库部署架构,通常是由客户端和服务器端两部分组成 客户端封 ...
- Java开发工程师(Web方向) - 03.数据库开发 - 第4章.事务
第4章--事务 事务原理与开发 事务Transaction: 什么是事务? 事务是并发控制的基本单位,指作为单个逻辑工作单元执行的一系列操作,且逻辑工作单元需满足ACID特性. i.e. 银行转账:开 ...
随机推荐
- Linux关于压缩和解压缩实例
在谈到压缩和解压缩,我想说说它们的应用场景,其实它们主要的应用场景是有这么几个方面? (1)备份(几十个数据库每天进行备份,即包含数据又包含脚本,还有其他十分重要的日志文件等等); (2)降低服务器存 ...
- iPhone 耳机在PC电脑上使用方法
把主声道(Master)从正中间调整到最左或者最右就行了
- 安装jdk1.7
1.压缩文件放到/usr文件夹里 2.解压到 /usr里,tar -zxvf jdk-7u71-linux-i586.tar.gz 3.配置jdk环境变量,打开/etc/profile配置文件,将下面 ...
- React Native IOS ---基础环境搭建(前端架构师)
React Native -IOS 开发环境搭建 web架构(基础) 安装依赖 * 必须安装的依赖有:Node.Watchman 和 React Native 命令行工具以及 Xcode. npm 镜 ...
- ASP.NET WebApi 中使用swagger 构建在线帮助文档
1 在Visual Studio 中创建一个Asp.NET WebApi 项目,项目名:Com.App.SysApi(本例创建的是 .net 4.5 框架程序) 2 打开Nuget 包管理软件,查 ...
- 【译】2分钟介绍Rx
原文地址:https://medium.com/@andrestaltz/2-minute-introduction-to-rx-24c8ca793877 翻译去掉了一些口水话(⊙o⊙) 诸位应该已经 ...
- Unity 游戏框架搭建 (十八) 静态扩展 + 泛型实现transform的链式编程
本篇文章介绍如何实现如下代码的链式编程: C# this.Position(Vector3.one) .LocalScale(1.0f) .Rotation(Quaternion.identity); ...
- jQuery 属性操作 - addClass() 和 removeClass() 方法
实例 向第一个 p 元素添加一个类: $("button").click(function(){ $("p:first").addClass("int ...
- 个人免签即时到账收款接口 bufpay.com 支持多账号收款
有很多 bufpay 的用户反馈,单个手机收款有些时候不太方便,切换手机太麻烦:或者是营业额比较多,希望分摊到多个账号上面. 基于以上的问题,bufpay 开发了多手机收款的功能:每个收款的手机安装 ...
- ubuntu查找端口和kill
查看 : netstat -anp | grep 8080 结束: kill -9 进程号