Python中PyQuery库的使用总结
介绍
pyquery库是jQuery的Python实现,可以用于解析HTML网页内容,官方文档地址是:http://packages.python.org/pyquery/
pyquery 可让你用 jQuery 的语法来对 xml 进行操作。这I和 jQuery 十分类似。如果利用 lxml,pyquery 对 xml 和 html 的处理将更快。
这个库不是(至少还不是)一个可以和 JavaScript交互的代码库,它只是非常像 jQuery API 而已。
安装
pip install pyquery
或下载安装:https://pypi.python.org/pypi/pyquery/#downloads
初始化
引入库:from pyquery import PyQuery as pq
1、直接字符串
doc = pq("<html></html>") pq 参数可以直接传入 HTML 代码,doc 现在就相当于 jQuery 里面的 $ 符号了
2、lxml.etree
doc = pq(etree.fromstring("<html></html>"))
可以首先用 lxml 的 etree 处理一下代码,这样如果你的 HTML 代码出现一些不完整或者疏漏,都会自动转化为完整清晰结构的 HTML代码。
3、直接传URL
doc = pq('http://www.baidu.com')
这里就像直接请求了一个网页一样,类似用 urllib2 来直接请求这个链接,得到 HTML 代码
4、传文件
doc = pq(filename='hello.html')
可以直接传某个路径的文件名。
快速体验
现在我们以本地文件为例,传入一个名字为 hello.html 的文件,文件内容为:

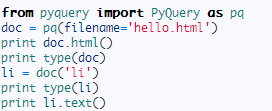
运行结果:
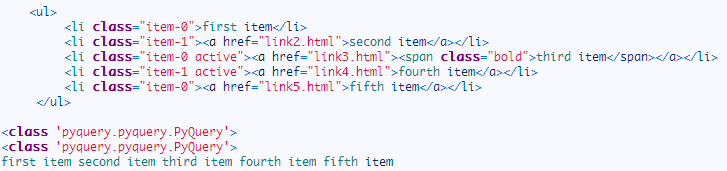
在这里我们注意到了一点,PyQuery 初始化之后,返回类型是 PyQuery,利用了选择器筛选一次之后,返回结果的类型依然还是 PyQuery,这简直和 jQuery 如出一辙,不能更赞!
然而想一下 BeautifulSoup 和 XPath 返回的是什么?列表!一种不能再进行二次筛选(在这里指依然利用 BeautifulSoup 或者 XPath 语法)的对象!
属性操作
你可以完全按照 jQuery 的语法来进行 PyQuery 的操作
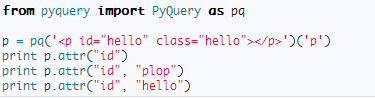
运行结果
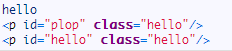
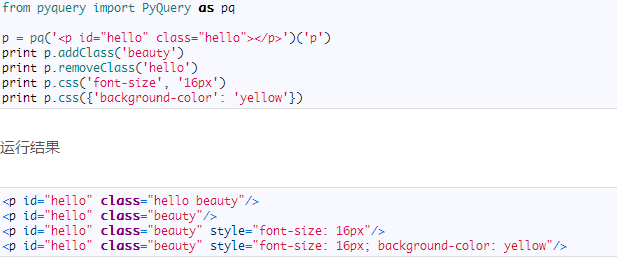
DOM操作

遍历
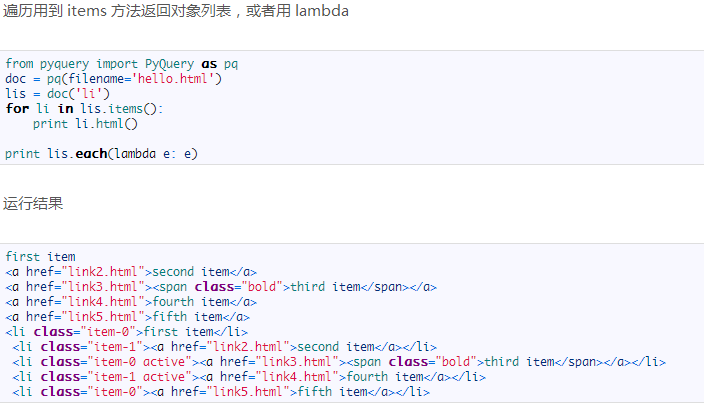
网页请求

pyquery – PyQuery complete API
https://pythonhosted.org/pyquery/api.html
1.可加载一段HTML字符串,或一个HTML文件,或是一个url地址,
d=pq("<html><title>hello</title></html>")
d=pq(filename=path_to_html_file)
d=pq(url='http://www.baidu.com')注意:此处url似乎必须写全
2.html()和text() ——获取相应的HTML块或文本块,
p=pq("<head><title>hello</title></head>")
p('head').html()#返回<title>hello</title>
p('head').text()#返回hello
3.根据HTML标签来获取元素,
d=pq('<div><p>test 1</p><p>test 2</p></div>')
d('p')#返回[<p>,<p>]
print d('p')#返回<p>test 1</p><p>test 2</p>
print d('p').html()#返回test 1
注意:当获取到的元素不只一个时,html()、text()方法只返回首个元素的相应内容块
4.eq(index) ——根据给定的索引号得到指定元素
接上例,若想得到第二个p标签内的内容,则可以:
print d('p').eq(1).html() #返回test 2
5.filter() ——根据类名、id名得到指定元素,例:
d=pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('p').filter('#1') #返回[<p#1>]
d('p').filter('.2') #返回[<p.2>]
6.find() ——查找嵌套元素
d=pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('div').find('p')#返回[<p#1>, <p.2>]
d('div').find('p').eq(0)#返回[<p#1>]
7.直接根据类名、id名获取元素
d=pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('#1').html()#返回test 1
d('.2').html()#返回test 2
8.获取属性值
d=pq("<p id='my_id'><a href='http://hello.com'>hello</a></p>")
d('a').attr('href')#返回http://hello.com
d('p').attr('id')#返回my_id
9.修改属性值
d('a').attr('href', 'http://baidu.com')把href属性修改为了baidu
10.addClass(value) ——为元素添加类
d=pq('<div></div>')
d.addClass('my_class')#返回[<div.my_class>]
11.hasClass(name) #返回判断元素是否包含给定的类
d=pq("<div class='my_class'></div>")
d.hasClass('my_class')#返回True
12.children(selector=None) ——获取子元素
d=pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d.children()#返回[<p#1>, <p#2>]
d.children('#2')#返回[<p#2>]
13.parents(selector=None)——获取父元素
d=pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d('p').parents()#返回[<span>]
d('#1').parents('span')#返回[<span>]
d('#1').parents('p')#返回[]
14.clone() ——返回一个节点的拷贝
15.empty() ——移除节点内容
16.nextAll(selector=None) ——返回后面全部的元素块
d=pq("<p id='1'>hello</p><p id='2'>world</p><img scr='' />")
d('p:first').nextAll()#返回[<p#2>, <img>]
d('p:last').nextAll()#返回[<img>]
17.not_(selector) ——返回不匹配选择器的元素
d=pq("<p id='1'>test 1</p><p id='2'>test 2</p>")
d('p').not_('#2')#返回[<p#1>]
jQuery的文档
可以参考query的文档来明白pyquery的使用方式
jQuery 遍历函数
jQuery 遍历函数包括了用于筛选、查找和串联元素的方法。
函数 描述
.add() 将元素添加到匹配元素的集合中。
.andSelf() 把堆栈中之前的元素集添加到当前集合中。
.children() 获得匹配元素集合中每个元素的所有子元素。
.closest() 从元素本身开始,逐级向上级元素匹配,并返回最先匹配的祖先元素。
.contents() 获得匹配元素集合中每个元素的子元素,包括文本和注释节点。
.each() 对 jQuery 对象进行迭代,为每个匹配元素执行函数。
.end() 结束当前链中最近的一次筛选操作,并将匹配元素集合返回到前一次的状态。
.eq() 将匹配元素集合缩减为位于指定索引的新元素。
.filter() 将匹配元素集合缩减为匹配选择器或匹配函数返回值的新元素。
.find() 获得当前匹配元素集合中每个元素的后代,由选择器进行筛选。
.first() 将匹配元素集合缩减为集合中的第一个元素。
.has() 将匹配元素集合缩减为包含特定元素的后代的集合。
.is() 根据选择器检查当前匹配元素集合,如果存在至少一个匹配元素,则返回 true。
.last() 将匹配元素集合缩减为集合中的最后一个元素。
.map() 把当前匹配集合中的每个元素传递给函数,产生包含返回值的新 jQuery 对象。
.next() 获得匹配元素集合中每个元素紧邻的同辈元素。
.nextAll() 获得匹配元素集合中每个元素之后的所有同辈元素,由选择器进行筛选(可选)。
.nextUntil() 获得每个元素之后所有的同辈元素,直到遇到匹配选择器的元素为止。
.not() 从匹配元素集合中删除元素。
.offsetParent() 获得用于定位的第一个父元素。
.parent() 获得当前匹配元素集合中每个元素的父元素,由选择器筛选(可选)。
.parents() 获得当前匹配元素集合中每个元素的祖先元素,由选择器筛选(可选)。
.parentsUntil() 获得当前匹配元素集合中每个元素的祖先元素,直到遇到匹配选择器的元素为止。
.prev() 获得匹配元素集合中每个元素紧邻的前一个同辈元素,由选择器筛选(可选)。
.prevAll() 获得匹配元素集合中每个元素之前的所有同辈元素,由选择器进行筛选(可选)。
.prevUntil() 获得每个元素之前所有的同辈元素,直到遇到匹配选择器的元素为止。
.siblings() 获得匹配元素集合中所有元素的同辈元素,由选择器筛选(可选)。
.slice() 将匹配元素集合缩减为指定范围的子集。
Python中PyQuery库的使用总结的更多相关文章
- Python中PyQuery库的使用
pyquery库是jQuery的Python实现,可以用于解析HTML网页内容,我个人写过的一些抓取网页数据的脚本就是用它来解析html获取数据的. 它的官方文档地址是:http://packages ...
- python中requests库使用方法详解
目录 python中requests库使用方法详解 官方文档 什么是Requests 安装Requests库 基本的GET请求 带参数的GET请求 解析json 添加headers 基本POST请求 ...
- Python中第三方库Requests库的高级用法详解
Python中第三方库Requests库的高级用法详解 虽然Python的标准库中urllib2模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人实在感觉不好.它已经不适合现在的时代, ...
- Python爬虫-- PyQuery库
PyQuery库 PyQuery库也是一个非常强大又灵活的网页解析库,PyQuery 是 Python 仿照 jQuery 的严格实现.语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪 ...
- Python中cv2库和matplotlib库色彩空间排布不一致
今天在python中读如图片时发现以下问题: 1.在from matplotlib import pyplot as plt之后,再import cv2 cv2.imshow()不能正常使用,还不知道 ...
- Python 中拼音库 PyPinyin 的用法【华为云技术分享】
[摘要] 最近碰到了一个问题,项目中很多文件都是接手过来的中文命名的一些素材,结果在部署的时候文件名全都乱码了,导致项目无法正常运行. 后来请教了一位大佬怎么解决文件名乱码的问题,他说这个需要正面解决 ...
- python中pyperclip库的功能
python3中pyperclip库的功能 作用就是复制.粘贴 例子 import pyperclip pyperclip.copy('Hello world!') pyperclip.paste() ...
- Python中msgpack库的使用
msgpack用起来像json,但是却比json快,并且序列化以后的数据长度更小,言外之意,使用msgpack不仅序列化和反序列化的速度快,数据传输量也比json格式小,msgpack同样支持多种语言 ...
- Python中datetime库的用法
datetime模块用于是date和time模块的合集,datetime有两个常量,MAXYEAR和MINYEAR,分别是9999和1. datetime模块定义了5个类,分别是 1.datetime ...
随机推荐
- redis之(八)redis的有序集合类型的命令
[一]增加元素 --->命令:ZADD key score member [score member] --->向有序集合放入一个分数为score的member元素 --->元素存在 ...
- 亲测能用的mysqli类,挺好用的
<?php header('content-type:text/html;charset=utf-8'); /* 掌握满足单例模式的必要条件 (1)私有的构造方法-为了防止在类外使用new关键字 ...
- Interllij IDEA 使用Git工具
1.git简介 git是目前流行的分布式版本管理系统.它拥有两套版本库,本地库和远程库,在不进行合并和删除之类的操作时这两套版本库互不影响.也因此其近乎所有的操作都是本地执行,所以在断网的情况下任然可 ...
- YII2 源码阅读 综述
如何阅读源码呢? 我的方法是,打开xdebug的auto_trace [XDebug] ;xdebug.profiler_append = 0 ;xdebug.profiler_enable = 1 ...
- destoon 部署到服务器如何修改密码使网站能正常访问登录
1.根目录的config.inc.php 修改 db_pass 2.缓存文件 根目录/file/cache/module-2.php 修改 uc_dbpwd PS:不一定都在module-2.p ...
- 主元素 II
主元素 II 给定一个整型数组,找到主元素,它在数组中的出现次数严格大于数组元素个数的三分之一. 样例 给出数组[1,2,1,2,1,3,3] 返回 1 注意 数组中只有唯一的主元素 挑战 要求时间复 ...
- 洛谷——P1104 生日
P1104 生日 题目描述 cjf君想调查学校OI组每个同学的生日,并按照从大到小的顺序排序.但cjf君最近作业很多,没有时间,所以请你帮她排序. 输入输出格式 输入格式: 有2行, 第1行为OI组总 ...
- Sd - 数据库开发调优
尤其是Sql写法上的技巧,以及常见Sql的写法
- sum nowcode
时间限制:1秒 空间限制:131072K 题目描述 考虑维护一个这样的问题:(1) 给出一个数组A,标号为1~n(2) 修改数组中的一个位置.(3) 询问区间[l,r]中所有子集的位运算and之和mo ...
- 【POJ】1089Intervals
Intervals Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 8276 Accepted: 3270 Descrip ...