Machine Learning笔记整理 ------ (五)决策树、随机森林
1. 决策树
一般的,一棵决策树包含一个根结点、若干内部结点和若干叶子结点,叶子节点对应决策结果,其他每个结点对应一个属性测试,每个结点包含的样本集合根据属性测试结果被划分到子结点中,而根结点包含样本全集,从根结点到每个叶子结点的路径对应了一个判定测试序列。其基本流程如下所示:
输入:训练集D={(x1,y1), (x2, y2), ......, (xm, ym)}
属性集A={a1, a2, ......, ad}
过程:函数TreeGenerate(D, A),传入参数为训练集D与属性集A
1: 生成结点node;
2: if D中样本全部属于同一类别C then
3: 将node标记为C类叶子结点;return
4: end if
5: if A=∅ OR D中样本在A上的取值相同 then
6: 将node标记为叶子结点,其类别标记为D中样本数量最多的类;return
7: end if
8: 从A中选择最优划分属性a*;
9: for a*的每一个值av* do
10: 为node生成一个分支;令Dv表示D在a*上取值为av*的样本子集;
11: if Dv为空 then
12: 将分支结点标记为叶子结点,其类别标记为D中样本最多的类;return
13: else
14: 以TreeGenerate(Dv,A\{a*})为分支结点
15: end if
16: end for

所以,决策树的生成是一个递归过程,在决策树基本算法中,有三种情形会导致递归,它们分别是:
- 当前结点包含的样本全部属于同一个类别,无需划分(1-3行)
- 当前属性集合为∅,或者所有样本在所有属性上的取值是相同的,无法划分(4-6行)
- 当前结点包含的样本集合为∅,无法划分(样本集合为∅当然无法划分)
综上所述,决策树算法的关键点在于第8行:选择最优划分属性a*。一般而言,我们希望达到的效果是随着划分的不断进行,结点的纯度(purity)越来越高。
2. 划分选择
(1) 信息增益 (Information Gain)
信息熵(information entropy)是用于度量样本集合纯度最常用的一种指标,假定当前样本集合D中第k类样本所占的比例为pk(k=1, 2, ..., |y|),则D的信息熵定义为:
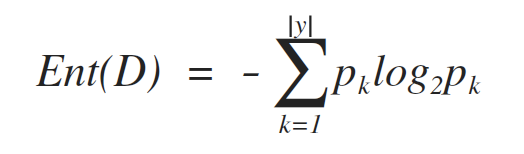
其中,y是分类的数量,即标签label的数量,也就是有多少个pk。Ent(D)的值越小,则D的纯度越高。
样本的某离散属性a有个V个可能的取值 {a1, a2, ......, av},使用属性a对数据集D进行划分,则可以产生V个分支结点,其中,第x个分支结点包含了D中所有在属性a上取值为ax的样本,记为Dx,即可根据 Ent(D) 计算出信息熵,再考虑到不同的分支结点包含的样本数量不同,为分支结点赋予权重|Dx|/|D|,即样本数量越多的分支结点影响越大,于是便可以计算出属性a对样本集D划分所获的的信息增益(information gain):
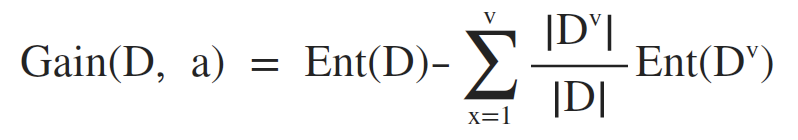
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,可以表示为:

ID3决策树算法(Quinlan,1986)就是使用信息增益为准则来选择划分属性。
E.g. 西瓜数据集2.0如下:
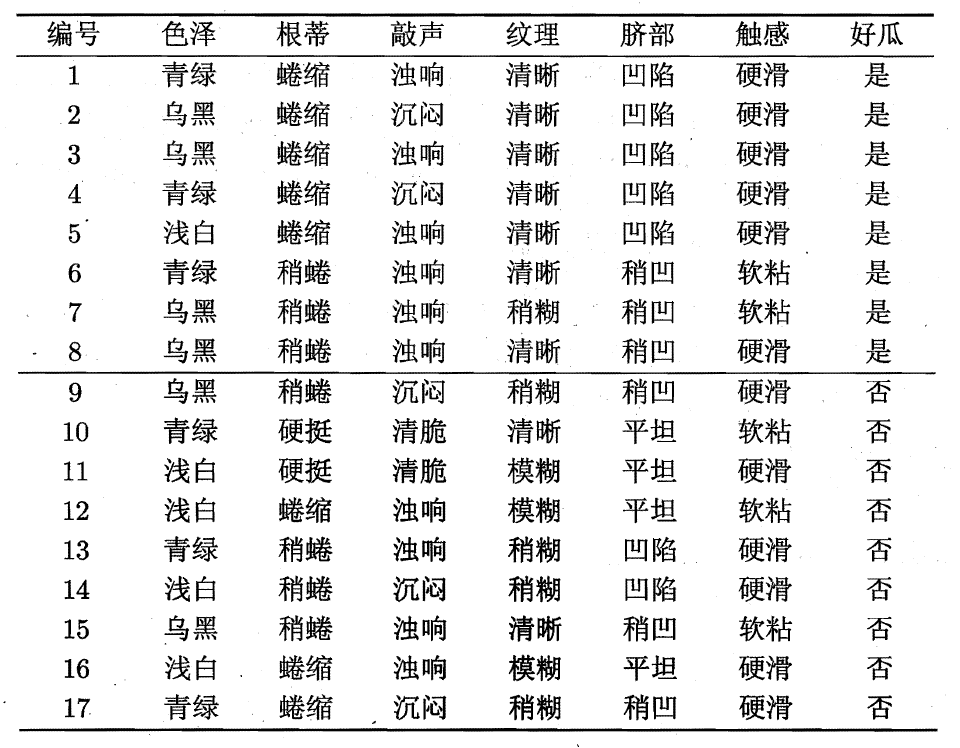
可以看到,整个数据集D包含的样本数量为17,其中8个正例(好瓜),9个反例(坏瓜),由于是二分类,标记Label的数量为2,故 |y|=2。
根节点包含所有样本,计算根节点的信息熵:
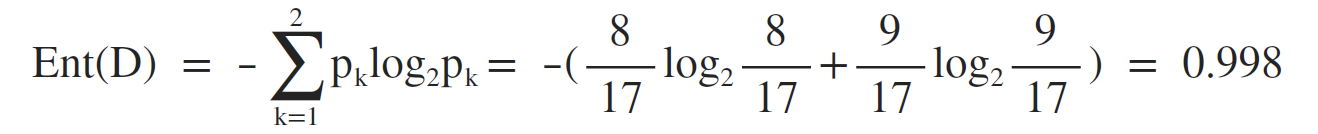
接下来需要计算出当前属性集合,即 A = {色泽,根蒂,敲声,纹理,脐部,触感} 中每个属性的信息增益。
以属性“色泽”为例,该属性有3个取值{青绿,乌黑,浅白},如果使用“色泽”属性对数据集D进行划分,则可以得到3个子集,也就是对应的在决策树上有3个分支,分别记为:D1(青绿),D2(乌黑),D3(浅白),如下所示:

故可以计算出每一个属性值对应的信息熵:
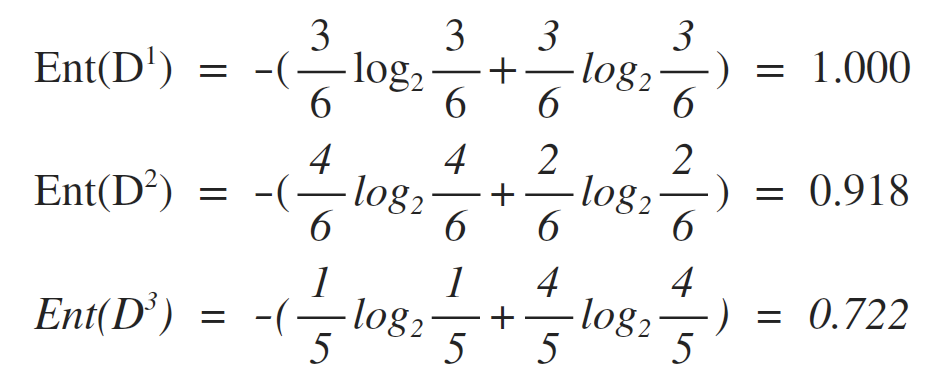
最后可以计算出属性“色泽”的信息增益为:
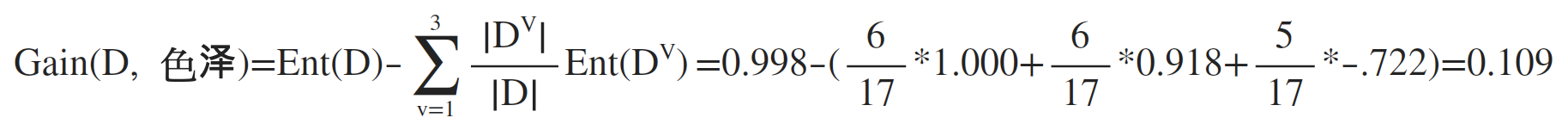
类似的,重复上述步骤,可以计算出其他属性的信息增益:
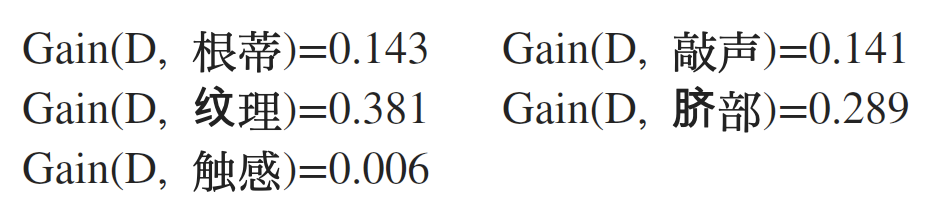
可以看到,如果使用属性“纹理”作为划分结点,我们获得的信息增益是最大的,所以选择“纹理”作为当前结点的划分属性。
选择划分结点的步骤总结:
- 计算根节点的信息熵
- 对于属性集合中的每个属性,分别计算它们的信息增益
- 根据该属性的取值,将数据集划分为属性值对应的子集,故子集的数量应该与该属性的取值数量一致
- 计算出每个属性值对应的信息熵
- 计算出该属性的信息增益
- 在获得所有属性的信息增益后,找到信息增益最大的属性,即为当前结点的划分属性
接下来剩余的结点的进一步划分,则先要找到当前结点样本中可用的属性集合,再重复之前的步骤分别计算出每个属性对应的信息增益,取最大者为下游结点的划分属性。
(2) 增益率 (Gain ratio)
信息增益准则对取值数目较多的属性有所偏好,为了减轻这种影响,可以使用增益率来选择最优划分属性,信息增益率的定义为:

其中,IV(a) 称为属性a的固有值 (Quinlan, 1993),其意义在于:属性a的可能取值数目越多(即V越大),IV(a)的值通常会越大,定义如下:
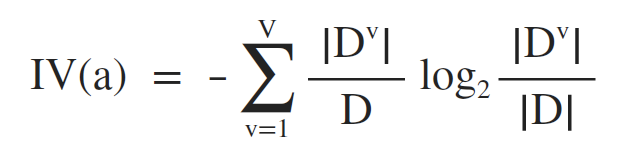
对于上面的西瓜数据集2.0,固有值如下:
IV(触感) = 0.874 V=2
IV(色泽) = 1.580 V=3
IV(编号) = 4.088 V=17
需要注意的是,增益率准则对于可取值数目较少的属性有所偏好,所以,著名的C4.5决策树算法(Quinlan, 1993)并不直接使用增益率最大者作为划分属性,而是先从候选划分属性中找到信息增益高于平均水平的增益,再从中选择增益率最高者。
(3) 基尼指数
CART决策树算法使用基尼指数来选择划分属性,数据集D的纯度可以用基尼指数来进行衡量:
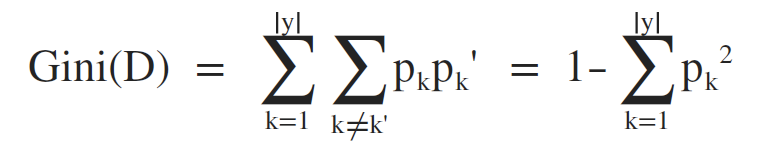
直观来说,Gini(D) 反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D) 越小,则数据集D的纯度越高。
另一方面,属性a的基尼指数定义为:
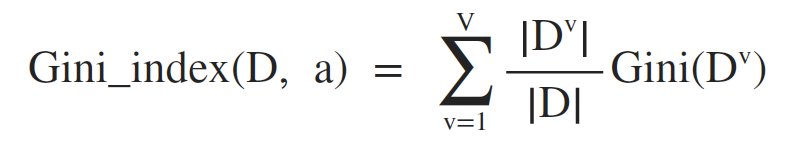 所以,在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优化分属性,即:
所以,在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优化分属性,即:
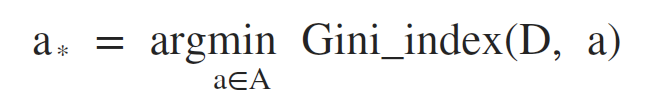
3. 剪枝处理
剪枝(pruning)是决策树算法处理过拟合的主要手段,在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会导致决策树分支过多,因此可以通过主动去掉一些分支来降低过拟合的风险。剪枝的基本策略分为预剪枝(prepruning)和后剪枝(post-pruning)。
(1) 预剪枝(prepruning)
预剪枝是指在决策树生成过程中,对每个结点在划分前进行估计,如果当前结点的划分不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶子节点。
(2) 后剪枝(post-pruning)
后剪枝指的是先从训练集生成一棵完整的决策树,然后自下向上地对非叶子结点进行考察,如果将该结点对应的子树替换为叶子结点能够带来决策树泛化性能的提升,则将该子树替换为叶子结点。
4. 随机森林
(1) 装袋 (Bagging)
Bagging(Breiman,1996)是并行式集成学习方法最著名的代表,基于自助采样法(bootstrap sampling),即:给定包含m个样本的数据集,随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样经过m次随机采样操作,可以得到含m个样本的采样集合,依此可以采样出T个含有m个样本的采样集,然后基于每个采样集训练出一个基学习器(模型),再将这些基学习器进行结合,这就是Bagging的基本流程。在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。如下所示:
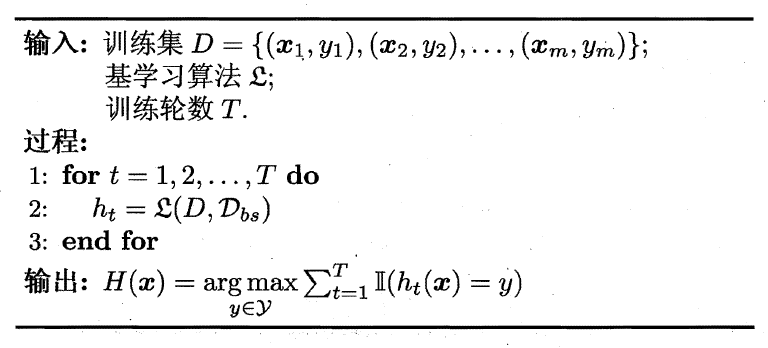
假定基学习器的计算复杂度为O(m),则Bagging的复杂度大致为T(O(m)+O(s)),考虑到采样与投票/平均过程的复杂度O(s)很小,而T通常是一个不太大的常数,因此,训练一个Bagging集成与直接使用基学习算法训练一个模型的复杂度同阶,因此Bagging是一个很高效的集成学习算法。
从偏差-方差分解的角度看,Bagging主要关注降低方差,因此在不剪枝决策树、神经网络等容易受到样本扰动的模型上效果更佳明显。
(2) 随机森林(Random Forest)
随机森林(Breiman,2001)是Bagging的一个扩展变体,RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体而言,传统决策树在选择划分属性时,是在当前节点的属性集合(假设有d个属性)中选择一个最优属性进行划分,而在随机森林中,对于基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制流随机性的引入程度:若k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分。一般情况下,推荐k=log2d。值得一提的是,随机森林的起始性能往往相对较差,尤其是在集成中只包含一个基学习器时,这是因为通过引入了属性扰动,随机森林中个体模型的性能往往有所降低,但是随着个体模型数量的增加,随机森林通常会收敛到更低的泛化误差。
Machine Learning笔记整理 ------ (五)决策树、随机森林的更多相关文章
- Machine Learning笔记整理 ------ (一)基本概念
机器学习的定义:假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E,使其在T中任务获得了性能改善,我们则说关于任务类T和P,该程序对经验E进行了学习(Mitchell, 1997) ...
- Machine Learning笔记整理 ------ (三)基本性能度量
1. 均方误差,错误率,精度 给定样例集 (Example set): D = {(x1, y1), (x2, y2), (x3, y3), ......, (xm, ym)} 其中xi是对应属性的值 ...
- Machine Learning笔记整理 ------ (二)训练集与测试集的划分
在实际应用中,一般会选择将数据集划分为训练集(training set).验证集(validation set)和测试集(testing set).其中,训练集用于训练模型,验证集用于调参.算法选择等 ...
- Machine Learning笔记整理 ------ (四)线性模型
1. 线性模型 基本形式:给定由d个属性描述的样本 x = (x1; x2; ......; xd),其中,xi是x在第i个属性上的取值,则有: f(x) = w1x1 + w2x2 + ...... ...
- 第五周(web,machine learning笔记)
2019/11/2 1. 表现层状态转换(REST, representational state transfer.)一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相 ...
- bootstrap && bagging && 决策树 && 随机森林
看了一篇介绍这几个概念的文章,整理一点点笔记在这里,原文链接: https://machinelearningmastery.com/bagging-and-random-forest-ensembl ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
- AI学习---分类算法[K-近邻 + 朴素贝叶斯 + 决策树 + 随机森林 ]
分类算法:对目标值进行分类的算法 1.sklearn转换器(特征工程)和预估器(机器学习) 2.KNN算法(根据邻居确定类别 + 欧氏距离 + k的确定),时间复杂度高,适合小数据 ...
- 决策树&随机森林
参考链接: https://www.bilibili.com/video/av26086646/?p=8 <统计学习方法> 一.决策树算法: 1.训练阶段(决策树学习),也就是说:怎么样构 ...
随机推荐
- RESTful 开发风格介绍
REST(英文:Representational State Transfer,简称REST)描述了一个架构样式的网络系统.在目前主流的三种Web服务交互方案中,REST相比于SOAP(Simple ...
- oracle cascade用法
原文地址:https://www.cnblogs.com/moyijian/p/9940323.html#4111551 级联删除,比如你删除某个表的时候后面加这个关键字,会在删除这个表的同时删除和该 ...
- Crash for small compressed texture on some Android device
I created a full white texture with 4x4 size. Unity requires that compressed texture size should be ...
- 微信小程序中的app文件介绍
[app] 一.app.json 1.对当前小程序的全局配置 2.页面路径.界面表现.网络超时时间.底部 tab 等 { "pages":[ "pages/index/i ...
- 上白泽慧音(tarjan,图的染色)
题目描述 在幻想乡,上白泽慧音是以知识渊博闻名的老师.春雪异变导致人间之里的很多道路都被大雪堵塞,使有的学生不能顺利地到达慧音所在的村庄.因此慧音决定换一个能够聚集最多人数的村庄作为新的教学地点.人间 ...
- 03.安装jdk8作为系统环境
博客为日常工作学习积累总结: 1.安装JDK8 创建安装目录:mkdir /application/java8 解压-安装包自行下载:tar -zxf jdk-8u202-linux-x64.tar. ...
- vue使用axios调用豆瓣API跨域问题
最近做了一个vue小demo,使用了豆瓣开源的API,通过ajax请求时需要跨域才能使用. 封面.jpg 一.以下是豆瓣常用的开源接口: 正在热映 :https://api.douban.com/ ...
- Linux及FL2440使用过程遇到的各种问题和小技巧
原文链接:http://www.cnblogs.com/NickQ/p/8900474.html ## Linux及FL2440使用过程遇到的各种问题和小技巧 关于移植linux根文件系统中的问题 在 ...
- ruby基础知识之 class&module
以下分别介绍了class方法和module方法,还有最简单的def方法. 其中module和class的区别下面会说,这里首先声明,def定义的方法,需要定义对象后才能调用,而class和module ...
- VMWare共享文件
windows与虚拟机的linux共享windows下的一个文件夹 1.重新安装VMware Tools,在VMware面板上选择“虚拟机-重新安装VMware tools…” 2.使用命令 Ctrl ...