Batch Normalization--介绍
思考
YJango的前馈神经网络--代码LV3的数据预处理中提到过:在数据预处理阶段,数据会被标准化(减掉平均值、除以标准差),以降低不同样本间的差异性,使建模变得相对简单。
我们又知道神经网络中的每一层都是一次变换,而上一层的输出又会作为下一层的输入继续变换。如下图中, 经过第一层
的变换后,所得到的
; 而
经过第二层
的变换后,得到
。
在第二层所扮演的角色就是
在第一层所扮演的角色。 我们将
进行了标准化,那么,为什么不对
也进行标准化呢?
Batch Normalization论文便首次提出了这样的做法。
Batch Normalization(BN)就是将每个隐藏层的输出结果(如 )在batch上也进行标准化后再送入下一层(就像我们在数据预处理中将
进行标准化后送入神经网络的第一层一样)。
优点
那么Batch Normalization(BN)有什么优点?BN的优点是多个并存,但这里只提一个最容易理解的优点。
训练时的问题
尽管在讲解神经网络概念的时候,神经网络的输入指的是一个向量 。
但在实际训练中有:
- 随机梯度下降法(Stochastic Gradient Descent):用一个样本的梯度来更新权重。
- 批量梯度下降法(Batch Gradient Descent):用多个样本梯度的平均值来更新权重。
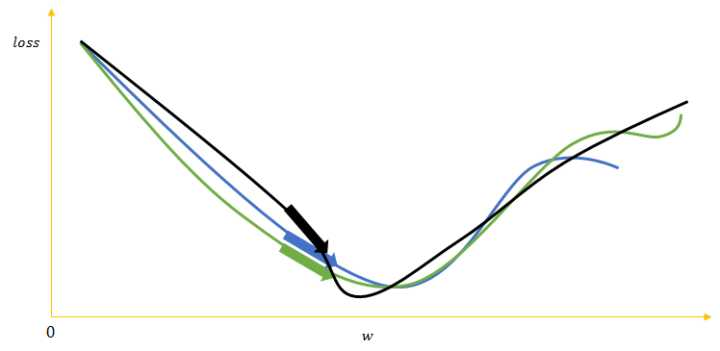
如下图所示,绿、蓝、黑的箭头表示三个样本的梯度更新网络权重后loss的下降方向。
若用多个梯度的均值来更新权重的批量梯度下降法可以用相对少的训练次数遍历完整个训练集,其次可以使更新的方向更加贴合整个训练集,避免单个噪音样本使网络更新到错误方向。

然而也正是因为平均了多个样本的梯度,许多样本对神经网络的贡献就被其他样本平均掉了,相当于在每个epoch中,训练集的样本数被缩小了。batch中每个样本的差异性越大,这种弊端就越严重。
一般的解决方法就是在每次训练完一个epoch后,将训练集中样本的顺序打乱再训练另一个epoch,不断反复。这样重新组成的batch中的样本梯度的平均值就会与上一个epoch的不同。而这显然增加了训练的时间。
同时因为没办法保证每次更新的方向都贴合整个训练集的大方向,只能使用较小的学习速率。这意味着训练过程中,一部分steps对网络最终的更新起到了促进,一部分steps对网络最终的更新造成了干扰,这样“磕磕碰碰”无数个epoch后才能达到较为满意的结果。
注:一个epoch是指训练集中的所有样本都被训练完。一个step或iteration是指神经网络的权重更新一次。
为了解决这种“不效率”的训练,BN首先是把所有的samples的统计分布标准化,降低了batch内不同样本的差异性,然后又允许batch内的各个samples有各自的统计分布。所以,
BN的优点自然也就是允许网络使用较大的学习速率进行训练,加快网络的训练速度(减少epoch次数),提升效果。
做法
设,每个batch输入是 (其中每个
都是一个样本,
是batch size) 假如在第一层后加入Batch normalization layer后,
的计算就倍替换为下图所示的那样。
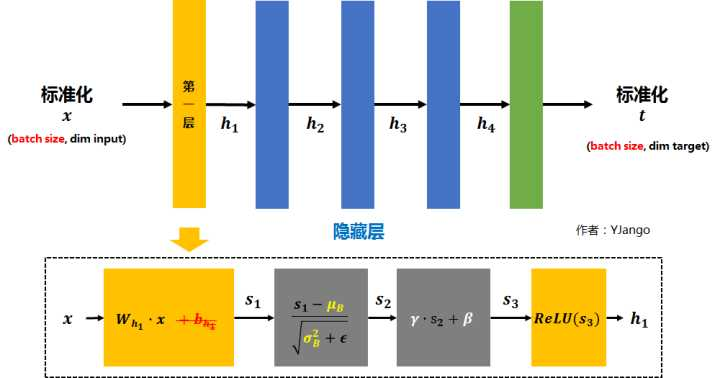
- 矩阵
先经过
的线性变换后得到
- 注:因为减去batch的平均值
后,
的作用会被抵消掉,所以没必要加入
- 将
再减去batch的平均值
得到
。
是为了避免除数为0的情况所使用的微小正数。
- 注:但
和
。
- 将
。
- 为加入非线性能力,
- 最终得到的
会被送到下一层作为输入。
需要注意的是,上述的计算方法用于在训练。因为测试时常会只预测一个新样本,也就是说batch size为1。若还用相同的方法计算 ,
就会是这个新样本自身,
就会成为0。
所以在测试时,所使用的 和
是整个训练集的均值
和方差
。
而整个训练集的均值和方差
的值通常也是在训练的同时用移动平均法来计算,会在下一篇代码演示中介绍
Batch Normalization--介绍的更多相关文章
- 使用TensorFlow中的Batch Normalization
问题 训练神经网络是一个很复杂的过程,在前面提到了深度学习中常用的激活函数,例如ELU或者Relu的变体能够在开始训练的时候很大程度上减少梯度消失或者爆炸问题.但是却不能保证在训练过程中不出现该问题, ...
- 在tensorflow中使用batch normalization
问题 训练神经网络是一个很复杂的过程,在前面提到了深度学习中常用的激活函数,例如ELU或者Relu的变体能够在开始训练的时候很大程度上减少梯度消失或者爆炸问题,但是却不能保证在训练过程中不出现该问题, ...
- Feature Extractor[batch normalization]
1 - 背景 摘要:因为随着前面层的参数的改变会导致后面层得到的输入数据的分布也会不断地改变,从而训练dnn变得麻烦.那么通过降低学习率和小心地参数初始化又会减慢训练过程,而且会使得具有饱和非线性模型 ...
- 论文笔记:Batch Normalization
在神经网络的训练过程中,总会遇到一个很蛋疼的问题:梯度消失/爆炸.关于这个问题的根源,我在上一篇文章的读书笔记里也稍微提了一下.原因之一在于我们的输入数据(网络中任意层的输入)分布在激活函数收敛的区域 ...
- 神经网络之 Batch Normalization
知乎 csdn Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ...
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
- 《RECURRENT BATCH NORMALIZATION》
原文链接 https://arxiv.org/pdf/1603.09025.pdf Covariate 协变量:在实验的设计中,协变量是一个独立变量(解释变量),不为实验者所操纵,但仍影响实验结果. ...
- 【转载】 详解BN(Batch Normalization)算法
原文地址: http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ------------------------------- ...
- Batch Normalization 学习笔记
原文:http://blog.csdn.net/happynear/article/details/44238541 今年过年之前,MSRA和Google相继在ImagenNet图像识别数据集上报告他 ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
随机推荐
- windows清空电脑的DNS缓存
清空电脑的DNS缓存 按"Win+R"系统热键打开"运行"窗口,进入terminal终端 输入"ipconfig /flushdns"命令后 ...
- kettle实现同构单表增量同步
job如下: 如下转换:获取区服列表,将id列表保存到结果(内存) job: 同构数据库单表抽取(每个输入执行一次) 同构数据库单表抽取(job) 的具体实现如下: 转换:获取数据库连接ID 从结果获 ...
- BOM (字节顺序标记)
BOM(Byte Order Mark):字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码. 注:计算机内部数据存储都是二进制的,只有知道一段数据的二进制存储 ...
- Oracle,cast函数
cast(要转换的值 AS 转换的类型): 问题:' ' as FSubBillNo 若用此法 oracle 默认字段类型为char型 且字段长度度为输入空格的长度,会导致字符串 ...
- [C语言]进阶|图形库
---------------------------------------------------------------------- // main.c // Created by weich ...
- 【原】The Linux Command Line - Manipulation Files And Directories
cp - Copy Files and directories mv - move/rename files and directories mkdir - create directories rm ...
- Object.assign()解释整理
链接:https://blog.csdn.net/wang252949/article/details/79106160 语法 Object.assign(target, ...sources) 参数 ...
- 使用::befor和::after伪元素在网站中添加图标
css3为了区分伪类和伪元素,伪元素采用双冒号写法. 常见伪类——:hover,:link,:active,:target,:not(),:focus. 常见伪元素——::first-letter,: ...
- yum方面的知识
修改CentOS默认yum源为国内yum镜像源 1.mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bac ...
- FortiGate防火墙HA下联堆叠交换机
1.拓扑图 2.防火墙配置 3.交换机配置 interface GigabitEthernet1/0/47 switchport access vlan 30 switchport mode acce ...