ELK(elasticsearch+kibana+logstash)搜索引擎(二): elasticsearch基础教程
1.elasticsearch的结构
首先elasticsearch目前的结构为 /index/type/id id对应的就是存储的文档ID,elasticsearch一般将数据以JSON格式存储。我们可以将elasticsearch和关系型数据库进行比较,index相当于关系型数据库中的database,type相当于table,而id就相当于表中的主键,elasticsearch中一个文档存储的一个json则能视为是关系型数据库中一张表的一行数据,而ID就是他的主键,在理解了es的存储结构后我们就可以对elasticsearch的一些基本使用进行了解了。
2.映射
elasticsearch在导入数据到索引时会按照固定的模板去导入数据,模板中可以设置字段的数据类型,以及设置数据的分词策略,注意es会在数据导入时就对数据做分词,然后在搜索数据的时候,会按照存入时的分词策略查询数据
{"settings":{
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik_max_word"
}
}
},
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
},
"mappings": {
"doc": {
"dynamic": "false",
"properties": {
"brand": {
"type": "string",
"analyzer": "ik_max_word"
},
"product_name": {
"type": "string",
"analyzer": "ik_max_word"
}
}
}
}
}
关于分词,elasticsearch中默认的标准分词器基本只能将一句话只能分成一个个的字,所以我们要用到ik分词器,切记版本问题。
下载地址》》:https://github.com/medcl/elasticsearch-analysis-ik
下载完成直接解压到es的pulgin目录下就行,ik分词器默认有两种分词方式:
(1) ik_max_word,该模式的分词策略为最大化词汇搜索,既会递归整个词条,将词条中所有的语句列出,允许重复。
(2) ik_smart,该策略不允许词汇重复,词条中如果有没有匹配到词典的字直接忽略
关于ik分词器这里就不再详细叙述了,有一些关于词典的知识请大家自行百度,这里只对elasticsearch重点讲述!
3.搜索
①query组件
好了,到了正式介绍es的时候,搜索引擎不用多说搜索肯定是最重要的一点,下面给出一个最简单的例子

首先看到 红色箭头1 ,整个语句意思从前至后 分别为 GET 方式对es请求, /catalogue 为请求的索引地址,可以具体到/type甚至id,/_search代表发起查询请求,而后面的则是请求的json体,毫无疑问json体是搜索的关键也是今天的主要讲解内容。
再看到红色剪头2,es中所有的查询都要包含在query组件中,query后面则跟着一个JSON,JSON的内容也就是红色剪头3,match_all代表无条件的查询即搜索所有,同样的还有match代表有条件的查询,查询条件放在match后面的json中,记住整个查询体都按照json格式来写。
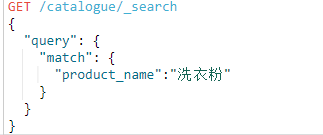
如上队商品名进行查询,查出所有名字包含洗衣粉的商品,搜索结果如下:

可以看到返回hits的其实是个json数组,每个json中包含着该数据的index、type、id以及匹配的分数_score以及数据_source
好了,这样就介绍完了最基本的单条件搜索
②bool组件
上面是单条件查询,那么多条件怎么查询呢,可以看到如下图:
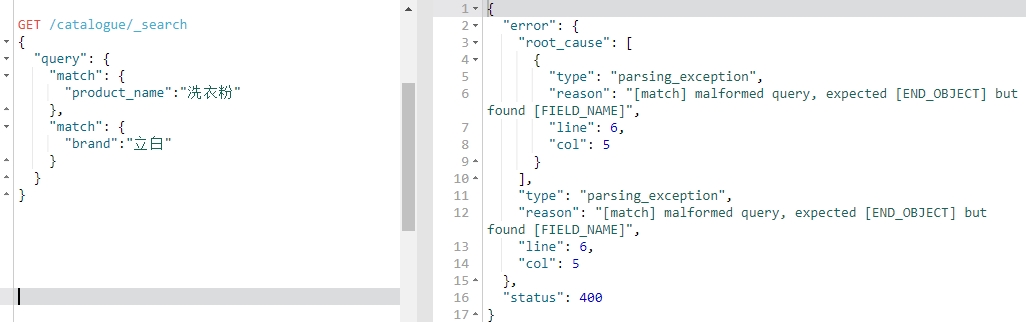
可以看到直接在query里面是不能进行多条件查找的,这里需要用到bool组件
使用bool组件进行复杂的查询:

可以看到使用bool组件后多条件搜索就没有报错,那么bool的结构是怎么样呢?
bool表达式包含三个jsonArray:
(1)must 包含了所有必须匹配的条件,如果有一项不匹配则排除,类似于逻辑且
(2) should包含的条件必须满足至少一个,类似于逻辑或
(3)must_not 包含了所有排除的条件,类似于逻辑非
整个结构如下:
{
"query":{
"bool":{
"must":[],
"should":[],
"must_not":[]
}
}
}
并且bool直接多重嵌套使用,所以想做出复杂的搜索功能,可以在bool上多下功夫
还有如上图中的range范围控制,和size查询的大小就不细说,看图应该就明白了
③分页查询
这里再讲一下es中怎么做到分页查询
es中和size并列还有from属性,size是一次查询的数量,from则是从第几个开始查,搭配使用即可达到分页查询的目的

④排序
es中可以使用sort对数据进行排序,sort为一个jsonArray,可以按照多个字段对数据进行排序,说明一下,如果不使用sort排序,es则默认按照_score匹配分数进行降序排序,当使用sort并且sort中没有_score时,_score会变成null从而达到排除按照_score排序,按照多个条件进行排序时,按照jsonArray中json的排序顺序进行先排和后排,关于升序降序学过数据库的童鞋应该很清楚!什么?没学过数据库?那你现在还不去学数据库?

至此elasticsearch基础教程结束,后面将为大家带来elasticsearch的进阶教程和ELK架构实现电商搜索引擎
ELK(elasticsearch+kibana+logstash)搜索引擎(二): elasticsearch基础教程的更多相关文章
- ELK(elasticsearch+kibana+logstash)搜索引擎(一): 环境搭建
1.ELK简介 这里简单介绍一下elk架构中的各个组件,关于elk的详细介绍的请自行百度 Elasticsearch是个开源分布式搜索引擎,是整个ELK架构的核心 Logstash可以对数据进行收集. ...
- 2018.2最新-Scrapy+elasticSearch+Django打造搜索引擎(二)
请问您今天要来个引擎吗? 工欲善其事必先利其器 最终项目上线演示地址: http://search.mtianyan.cn 第二节:我们搞搞比利,搞搞环境的搭建.Github地址: https://g ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
- Docker安装部署ELK教程(Elasticsearch+Kibana+Logstash+Filebeat)
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等. Logstash 是一个完全开 ...
- elasticsearch kibana logstash(ELK)的安装集成应用
官网关于kibana的学习指导网址是:https://www.elastic.co/guide/en/kibana/current/index.html Kibana是一个开源的分析和可视化平台,设计 ...
- Elasticsearch,Kibana,Logstash,NLog实现ASP.NET Core 分布式日志系统
Elasticsearch - 简介 Elasticsearch 作为核心的部分,是一个具有强大索引功能的文档存储库,并且可以通过 REST API 来搜索数据.它使用 Java 编写,基于 Apac ...
- Elasticsearch+Kibana+Logstash安装
安装环境: [root@node- src]# cat /etc/redhat-release CentOS Linux release (Core) 安装之前关闭防火墙 firewalld 和 se ...
- Elasticsearch(1.1.1)基础教程pdf
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味着, ...
- ELK (elasticsearch+kibana+logstash+elasticsearch-head) 华为云下载地址
https://mirrors.huaweicloud.com/elasticsearch https://mirrors.huaweicloud.com/kibana https://mirrors ...
随机推荐
- Python:每日一题007
题目: 输出 9*9 乘法口诀表. 程序分析: 分行与列考虑,共9行9列,i控制行,j控制列. 个人思路及代码: 第一版: for i in range(1,10): for j in range(1 ...
- druid + spring 事务 + removeAbandonedTimeout 超时回收导致的问题
今天使用上述组合 做项目.. 在做一个需要较长时间使用数据库的 请求时,项目日志没有任何报错,但是数据库也没有插入代码. 初步猜测是 数据库连接超过 removeAbandonedTimeout 时间 ...
- 《C#从现象到本质》读书笔记(四)第4章C#和面向对象
<C#从现象到本质>读书笔记第4章C#和面向对象 面向对象程序设计OOP 面向对象的三大特性是: 1)封装:类可以将它的成员私有化,只暴露它认为应当暴露给外界的成员.通过私有化成员,外界不 ...
- 【Selenium】【BugList3】firefox与Selenium版本不兼容,报: Message: Unsupported Marionette protocol version 2, required 3
环境信息:Windows7 64位 + python 3.6.5 + selenium 3.11.0 +pyCharm 1 #coding=utf-8 2 from selenium import w ...
- IIS7部署网站遇到的问题
1.web.config文件中更改配置项时: 因为 IIS 7 采用了更安全的 web.config 管理机制,默认情况下会锁住配置项不允许更改. 运行命令行 %windir%\system32\ ...
- navicat for mysql安装与破解
Windows系统的电脑 navicat for mysql 的安装软件以及破解包 方法/步骤 从网上下载需要用到的navicat for mysql 的安装软件以及破解包. 双击navi ...
- java 项目的路径详情
title: 项目下的路径问题tags:grammar_cjkRuby: true--- 在javaee的项目中,存取文件,解析xml和properties文件,以及项目中的文件,都需要获取路径,常用 ...
- Android 网络交互之下载断点续传
一.概述 1.概念 断点续传主要用于下载,本文也主要讲述下载时的断点续传的逻辑思路.顾名思义,断点续传就是下载从中断的地方继续下载,一般是因为暂停或者网络故障导致的下载中断,当恢复下载的时候可以从已经 ...
- Elasticsearch 自定义多个分析器
分析器(Analyzer) Elasticsearch 无论是内置分析器还是自定义分析器,都由三部分组成:字符过滤器(Character Filters).分词器(Tokenizer).词元过滤器(T ...
- Testing - 软件测试知识梳理 - 相关词汇
测试策略 描述测试工程的总体方法和目标:根据测试需求,描述在什么测试阶,依据什么测试要素和目标,进行什么种类的测试,使用什么样的测试方法和工具. 测试策略的制定主要包含如下内容: 确定测试过程要使用的 ...