Tesseract-OCR的简单使用与训练
Tesseract,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
源码地址为:https://github.com/tesseract-ocr/tesseract;
EXE可执行文件地址:http://download.csdn.net/download/whatday/7740469;
接下来,我们将在Windows环境下安装Tesseract并实现简单的转换和训练:
1、Tesseract实现
大体流程:Tesseract安装 -> 打开命令行 -> 生成目标文件
Tesseract安装
下载tesseract-ocr-setup-3.02.02.exe安装包,安装成功后会在相应磁盘下有Tesseract-OCR文件夹,如图

打开命令行
打开命令行,输入tesseract,回车;以下便是tesseract的大体面貌:
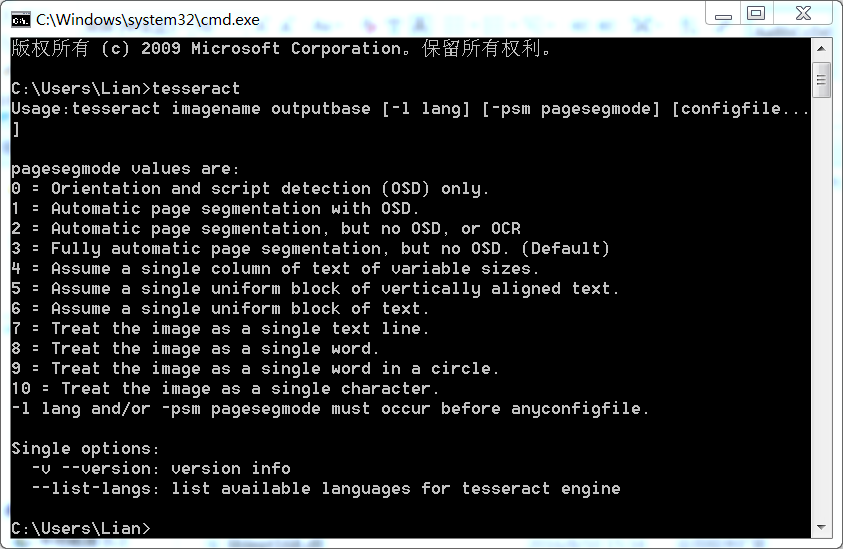
生成目标文件
先准备一张图片文件,如test.png
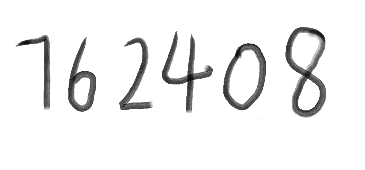
将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。

打开文件output_1.txt,发现tesseract成功的将图像转换成。
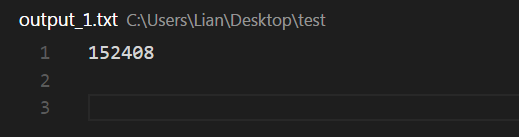
可喜可贺,说明老牌名将tesseract还是很强的!但是还是有点不够准确,那么我们有没有什么办法能提高tesseract识别字符准确率呢?接下来,我们将使用配套训练工具jTessBoxEditor来训练样本,来提高我们的准确率!
2、Tesseract训练:
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
安装jTessBoxEditor
下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)。
获取样本文件
我们可以用画图工具绘制样本文件,数量越多越好,我自己画了5张图,如图:
【注意】:样本图像文件格式必须为tif\tiff格式,否则在Merge样本文件的过程中会出现 Couldn’t Seek 的错误。
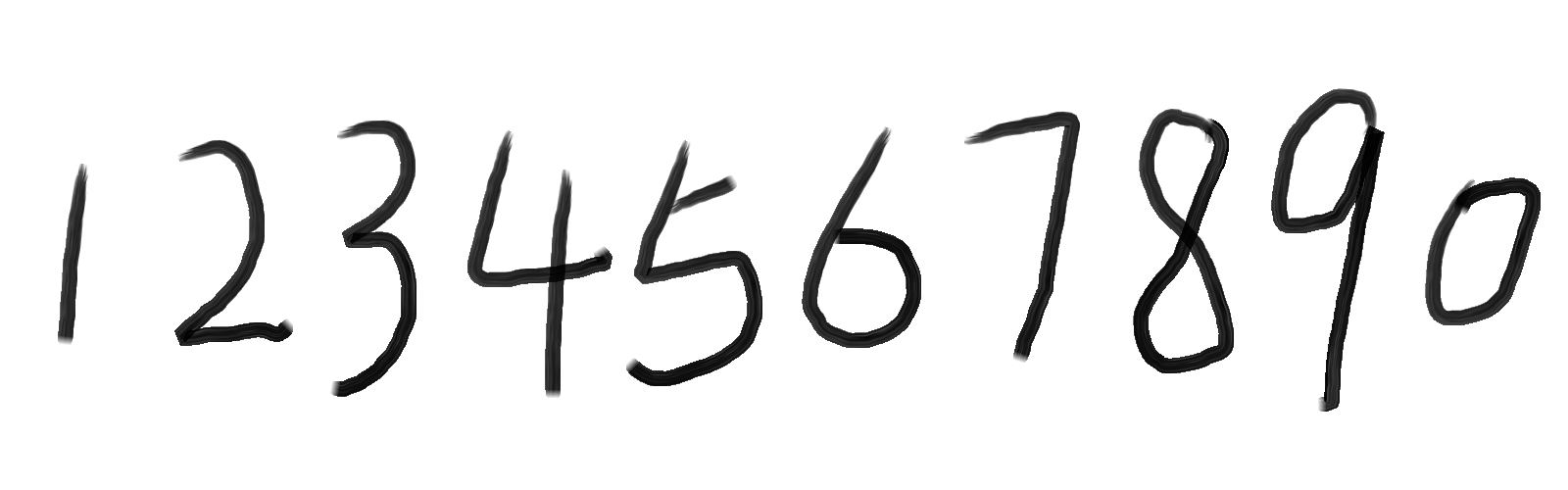



Merge样本文件
打开jTessBoxEditor,Tools->Merge TIFF,将样本文件全部选上,并将合并文件保存为num.font.exp0.tif
生成BOX文件
打开命令行并切换至num.font.exp0.tif所在目录,输入,生成文件名为num.font.exp0.box
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式。
定义字符配置文件
在目标文件夹内生成一个名为font_properties的文本文件,内容为
font
【语法】:<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
字符矫正
打开jTessBoxEditor,BOX Editor -> Open,打开num.font.exp0.tif;矫正<Char>上的字符,记得<Page>有好多页噢!

修改后记得保存。
执行批处理文件
在目标目录下生成一个批处理文件
rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr echo Clustering..
cntraining.exe num.font.exp0.tr echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
保存后执行即可,执行结果如图:

最终文件夹内会有以下文件,如图:

将生成的traineddata放入tessdata中
最后将num.trainddata复制到Tesseract-OCR中tessdata文件夹即可。
3、最后的测试
按照之前步骤,使用命令行输入
tesseract test.png output_2 -l num
我们可以看到新生成的文件output_2的内容为,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的eng语言匹配库。

我们可以看到,经过简单的训练,我们对于数字数据的转换准确率提高了很多。Tesseract的优点除了可以不断学习以外,还因为是使用C++写的开源程序,可以使用C#或者C++调用以及修改,很关键!
关于Tesseract,关于OCR,关于计算机,还有太多值得自己去学习,希望以后可以在这里记录下来。
如有错误或者建议,请尽情指教!
大二暑期实习
2016/8/12
Tesseract-OCR的简单使用与训练的更多相关文章
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- Tesseract OCR简单实用介绍
做字符识别,不能不了解google的Tesseract-OCR,但是如何在自己的工程中使用其API倒是语焉不详,官网上倒是很详尽地也很啰嗦地介绍如何重新编译生成适合自己平台的lib和dll,经过近些天 ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Tesseract–OCR 库原理探索
一,简介: Tesseract is probably the most accurate open source OCR engine available. Combined with the Le ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- tesseract ocr训练 pt验证码
识别率有问题A大概率识别为n,因此需要训练,这里讲一下 如何训练 参考 java代码里边直接使用tess4j,是对tesseract的封装,但是如果要训练,还是需要在进行安装tesseract-ocr ...
随机推荐
- 第二周例行报告psp
此作业要求详见https://edu.cnblogs.com/campus/nenu/2018fall/homework/2127 (1)psp表 本周进度条 累计进度图 本周PSP饼状图
- 外网ssh内网Linux服务器holer实现
外网ssh访问内网linux 内网的主机上安装了Linux系统,只能在局域网内访问,怎样从公网也能ssh访问本地Linux服务器? 本文将介绍使用holer实现的具体步骤. 1. 准备工作 1.1 安 ...
- LocalDate常用技巧
LocalDate是Java8新增的处理日期的类,使用起来比java.utils.date方便了许多.记录一些常用技巧: // 取当前日期: LocalDate today = LocalDate.n ...
- 王者荣耀交流协会第5次Scrum立会
开会时间:2017年10月31日下午18:00-18:31 共计31分钟 开会地点:一食堂二楼靠近窗户倒数第四排 今日完成工作进度: 王超同学完成了将生成饼状图原型整合到程序中 立会内容: 添加了新 ...
- python rtree包查找三维空间下的最近设备
rtree模块有2个常用的类:rtree.index.Index和rtree.index.Property.其中rtree.index.Index用于进行数据操作,rtree.index.Proper ...
- python 查找目录下 文件名中含有某字符串的文件
有坑的地方: 如果代码写成这样: [( os.path.abspath(x)) for x in os.listdir(startPath) ] 此代码只能用于当前目录下,listdir列出的都只是文 ...
- linux 怎么上传下载-- 文件
https://www.cnblogs.com/lynn-li/p/6078595.html yum install lrzsz rz:从本地上传文件至服务器 sz filename:从服务器下载文件 ...
- HTML文本元素标签
<b></b>表示关键字和产品名称如:<b>查看效果</b> 效果:加粗 查看效果 <strong></strong>表示重要的 ...
- 使用mysqlproxy实现mysql读写分离
先说一下什么是读写分离吧. 以三台虚拟机为例,搭建一主一从一代理,全部配置好之后,当从proxy插入数据时,该数据会同时插入主数据库,因为主从关系,从数据库也会有数据.当把从数据库执行slave st ...
- Python3之set, frozenset记录
set1 = set([1, 2, 3, 4]) set2 = frozenset([1, 2, 3, 4]) print(set1, set2, sep='|||') set1.add(" ...