Hadoop2.7.6_02_HDFS常用操作
1. HDFS常用操作
1.1. 查询
1.1.1. 浏览器查询
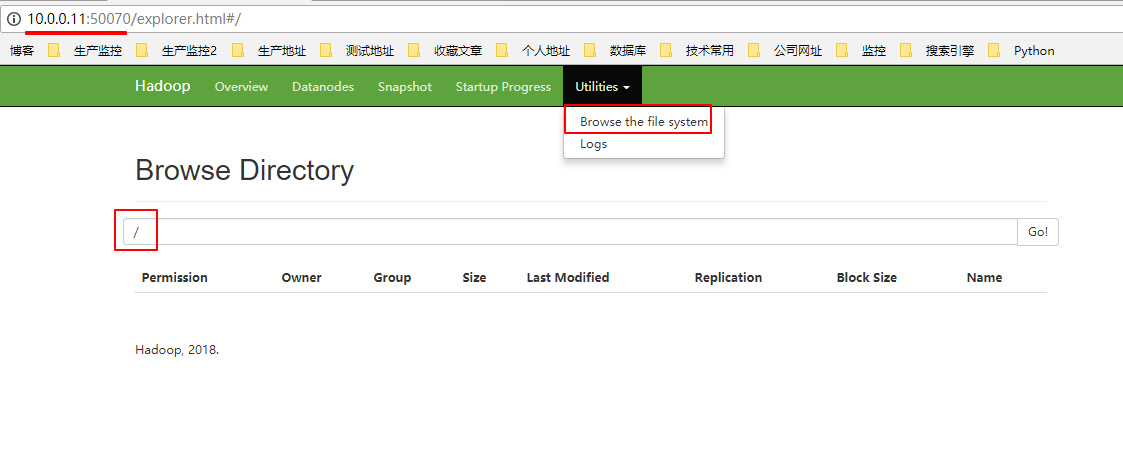
1.1.2. 命令行查询
[yun@mini04 bin]$ hadoop fs -ls /
1.2. 上传文件
[yun@mini05 zhangliang]$ cat test.info [yun@mini05 zhangliang]$ hadoop fs -put test.info / # 上传文件
[yun@mini05 software]$ ll -h
total 641M
-rw-r--r-- yun yun 190M Jun : CentOS-.4_hadoop-2.7..tar.gz
[yun@mini05 software]$ hadoop fs -put CentOS-.4_hadoop-2.7..tar.gz / # 上传文件
[yun@mini05 software]$ hadoop fs -ls /
Found items
-rw-r--r-- yun supergroup -- : /CentOS-.4_hadoop-2.7..tar.gz
-rw-r--r-- yun supergroup -- : /test.info
1.2.1. 文件存放位置
[yun@mini04 subdir0]$ pwd # 根据之前的配置,总共3份相同的文件
/app/hadoop/tmp/dfs/data/current/BP--10.0.0.11-/current/finalized/subdir0/subdir0
[yun@mini04 subdir0]$ ll -h # 默认128M 切片
total 192M
-rw-rw-r-- yun yun Jun : blk_1073741825
-rw-rw-r-- yun yun Jun : blk_1073741825_1001.meta
-rw-rw-r-- yun yun 128M Jun : blk_1073741826
-rw-rw-r-- yun yun 1.1M Jun : blk_1073741826_1002.meta
-rw-rw-r-- yun yun 62M Jun : blk_1073741827
-rw-rw-r-- yun yun 493K Jun : blk_1073741827_1003.meta
[yun@mini04 subdir0]$ cat blk_1073741825 [yun@mini04 subdir0]$
1.2.2. 浏览器访问
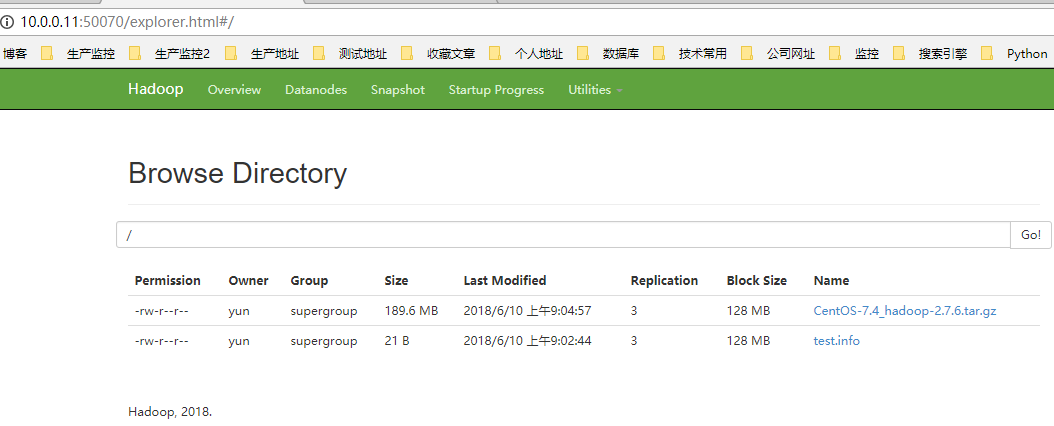
1.3. 文件下载
[yun@mini04 zhangliang]$ pwd
/app/software/zhangliang
[yun@mini04 zhangliang]$ ll
total
[yun@mini04 zhangliang]$ hadoop fs -ls /
Found items
-rw-r--r-- yun supergroup -- : /CentOS-.4_hadoop-2.7..tar.gz
-rw-r--r-- yun supergroup -- : /test.info
[yun@mini04 zhangliang]$ hadoop fs -get /test.info
[yun@mini04 zhangliang]$ hadoop fs -get /CentOS-.4_hadoop-2.7..tar.gz
[yun@mini04 zhangliang]$ ll
total
-rw-r--r-- yun yun Jun : CentOS-.4_hadoop-2.7..tar.gz
-rw-r--r-- yun yun Jun : test.info
[yun@mini04 zhangliang]$ cat test.info [yun@mini04 zhangliang]$
2. 简单案例
2.1. 准备数据
[yun@mini05 zhangliang]$ pwd
/app/software/zhangliang
[yun@mini05 zhangliang]$ ll
total
-rw-rw-r-- yun yun Jun : test.info
-rw-rw-r-- yun yun Jun : zhang.info
[yun@mini05 zhangliang]$ cat test.info [yun@mini05 zhangliang]$ cat zhang.info
zxcvbnm
asdfghjkl
qwertyuiop
qwertyuiop qwertyuiop
[yun@mini05 zhangliang]$ hadoop fs -mkdir -p /wordcount/input
[yun@mini05 zhangliang]$ hadoop fs -put test.info zhang.info /wordcount/input
[yun@mini05 zhangliang]$ hadoop fs -ls /wordcount/input
Found items
-rw-r--r-- yun supergroup -- : /wordcount/input/test.info
-rw-r--r-- yun supergroup -- : /wordcount/input/zhang.info
2.1. 运行分析
[yun@mini04 mapreduce]$ pwd
/app/hadoop/share/hadoop/mapreduce
[yun@mini04 mapreduce]$ ll
total
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-app-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-common-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-core-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-hs-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-hs-plugins-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-jobclient-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-jobclient-2.7.-tests.jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-client-shuffle-2.7..jar
-rw-r--r-- yun yun Jun : hadoop-mapreduce-examples-2.7..jar
drwxr-xr-x yun yun Jun : lib
drwxr-xr-x yun yun Jun : lib-examples
drwxr-xr-x yun yun Jun : sources
[yun@mini04 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7..jar wordcount /wordcount/input /wordcount/output
// :: INFO client.RMProxy: Connecting to ResourceManager at mini02/10.0.0.12:
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528589937101_0002
// :: INFO impl.YarnClientImpl: Submitted application application_1528589937101_0002
// :: INFO mapreduce.Job: The url to track the job: http://mini02:8088/proxy/application_1528589937101_0002/
// :: INFO mapreduce.Job: Running job: job_1528589937101_0002
// :: INFO mapreduce.Job: Job job_1528589937101_0002 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1528589937101_0002 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[yun@mini05 zhangliang]$ hadoop fs -ls /wordcount/output
Found items
-rw-r--r-- yun supergroup -- : /wordcount/output/_SUCCESS
-rw-r--r-- yun supergroup -- : /wordcount/output/part-r-
[yun@mini05 zhangliang]$ hadoop fs -cat /wordcount/output/part-r- asdfghjkl
qwertyuiop
zxcvbnm
3. 案例:开发shell采集脚本
3.1. 需求说明
点击流日志每天都10T,在业务应用服务器上,需要准实时上传至数据仓库(Hadoop HDFS)上
3.2. 需求分析
一般上传文件都是在凌晨24点操作,由于很多种类的业务数据都要在晚上进行传输,为了减轻服务器的压力,避开高峰期。
如果需要伪实时的上传,则采用定时上传的方式。比如每小时上传一次。
3.3. web日志模拟
运行jar包模拟web日志
# 必要的目录
# 模拟web服务器目录 /app/webservice
# 模拟web日志目录 /app/webservice/logs
# 模拟待上传文件存放的目录 /app/webservice/logs/up2hdfs # 在这个目录上传到HDFS
[yun@mini01 webservice]$ pwd
/app/webservice
[yun@mini01 webservice]$ ll
total
drwxrwxr-x yun yun Jun : logs
-rw-r--r-- yun yun Jun : testlog.jar
# 运行jar包,打印日志
[yun@mini01 webservice]$ java -jar testlog.jar &
……………………
# 生成web日志查看
[yun@mini01 logs]$ pwd
/app/webservice/logs
[yun@mini01 logs]$ ll -hrt
total 460K
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun 11K Jun : access.log.
-rw-rw-r-- yun yun .6K Jun : access.log
3.4. Shell脚本执行
# 脚本测试
[yun@mini01 hadoop]$ pwd
/app/yunwei/hadoop
[yun@mini01 hadoop]$ ll
-rwxrwxr-x yun yun Jun : uploadFile2Hdfs.sh
[yun@mini01 hadoop]$ ./uploadFile2Hdfs.sh
………………
3.5. 查看结果
3.5.1. 脚本执行结果查看
Web日志转移与上传查看
# web日志转移查看
[yun@mini01 logs]$ pwd
/app/webservice/logs
[yun@mini01 logs]$ ll -hrt
total 28K
-rw-rw-r-- yun yun .3K Jun : access.log ### 表明日志已经转移
drwxrwxr-x yun yun 16K Jun : up2hdfs # 待上传文件存放的目录
[yun@mini01 up2hdfs]$ pwd
/app/webservice/logs/up2hdfs
[yun@mini01 up2hdfs]$ ll -hrt
-rw-rw-r-- yun yun 11K Jun : access.log.7_20180614174001_DONE
-rw-rw-r-- yun yun 11K Jun : access.log.6_20180614174001_DONE
-rw-rw-r-- yun yun 11K Jun : access.log.5_20180614174001_DONE
-rw-rw-r-- yun yun 11K Jun : access.log.4_20180614174001_DONE
-rw-rw-r-- yun yun 11K Jun : access.log.3_20180614174001_DONE
-rw-rw-r-- yun yun 11K Jun : access.log.2_20180614174001_DONE
-rw-rw-r-- yun yun 11K Jun : access.log.1_20180614174001_DONE
## 文件以 DONE 结尾,表明已上传到HDFS
脚本日志查看
# shell脚本日志查看
[yun@mini01 log]$ pwd
/app/yunwei/hadoop/log
[yun@mini01 log]$ ll
total
-rw-rw-r-- yun yun Jun : uploadFile2Hdfs.sh.log
[yun@mini01 log]$ cat uploadFile2Hdfs.sh.log
-- :: uploadFile2Hdfs.sh access.log.1_20180614174001 ok
-- :: uploadFile2Hdfs.sh access.log.2_20180614174001 ok
-- :: uploadFile2Hdfs.sh access.log.3_20180614174001 ok
-- :: uploadFile2Hdfs.sh access.log.4_20180614174001 ok
-- :: uploadFile2Hdfs.sh access.log.5_20180614174001 ok
-- :: uploadFile2Hdfs.sh access.log.6_20180614174001 ok
-- :: uploadFile2Hdfs.sh access.log.7_20180614174001 ok
3.5.2. HDFS命令行上传文件查看
[yun@mini01 ~]$ hadoop fs -ls /data/webservice/
Found items
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.1_20180614174001
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.2_20180614174001
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.3_20180614174001
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.4_20180614174001
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.5_20180614174001
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.6_20180614174001
-rw-r--r-- yun supergroup -- : /data/webservice//access.log.7_20180614174001
3.5.3. 浏览器查看看
http://10.0.0.11:50070/explorer.html#/data/webservice/20180614 路径 : /data/webservice/20180614
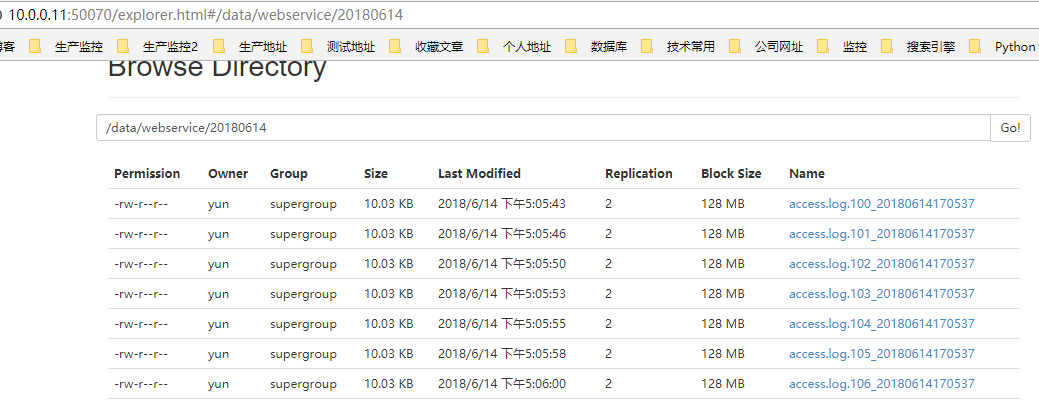
3.6. 脚本加入定时任务
[yun@mini01 hadoop]$ crontab -l # WEB日志上传HDFS 每小时执行一次
*/ * * * /app/yunwei/hadoop/uploadFile2Hdfs.sh >/dev/null >&
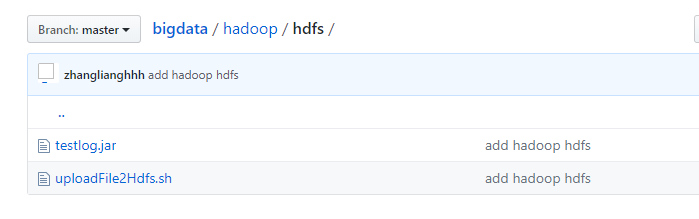
3.7. 相关的脚本和jar包
在Git上,路径如下:
https://github.com/zhanglianghhh/bigdata/tree/master/hadoop/hdfs
Hadoop2.7.6_02_HDFS常用操作的更多相关文章
- Hadoop HDFS文件常用操作及注意事项
Hadoop HDFS文件常用操作及注意事项 1.Copy a file from the local file system to HDFS The srcFile variable needs t ...
- 【三】用Markdown写blog的常用操作
本系列有五篇:分别是 [一]Ubuntu14.04+Jekyll+Github Pages搭建静态博客:主要是安装方面 [二]jekyll 的使用 :主要是jekyll的配置 [三]Markdown+ ...
- php模拟数据库常用操作效果
test.php <?php header("Content-type:text/html;charset='utf8'"); error_reporting(E_ALL); ...
- Mac OS X常用操作入门指南
前两天入手一个Macbook air,在装软件过程中摸索了一些基本操作,现就常用操作进行总结, 1关于触控板: 按下(不区分左右) =鼠标左键 control+按下 ...
- mysql常用操作语句
mysql常用操作语句 1.mysql -u root -p 2.mysql -h localhost -u root -p database_name 2.列出数据库: 1.show datab ...
- nodejs配置及cmd常用操作
一.cmd常用操作 1.返回根目录cd\ 2.返回上层目录cd .. 3.查找当前目录下的所有文件dir 4.查找下层目录cd window 二.nodejs配置 Node.js安装包及源码下载地址为 ...
- Oracle常用操作——创建表空间、临时表空间、创建表分区、创建索引、锁表处理
摘要:Oracle数据库的库表常用操作:创建与添加表空间.临时表空间.创建表分区.创建索引.锁表处理 1.表空间 ■ 详细查看表空间使用状况,包括总大小,使用空间,使用率,剩余空间 --详细查看表空 ...
- python 异常处理、文件常用操作
异常处理 http://www.jb51.net/article/95033.htm 文件常用操作 http://www.jb51.net/article/92946.htm
- byte数据的常用操作函数[转发]
/// <summary> /// 本类提供了对byte数据的常用操作函数 /// </summary> public class ByteUtil { ','A','B',' ...
随机推荐
- Dockerfile指令详解
Dockerfile中包括FROM.MAINTAINER.RUN.CMD.EXPOSE.ENV.ADD.COPY.ENTRYPOINT.VOLUME.USER.WORKDIR.ONBUILD等13个指 ...
- Maven的assembly插件实现自定义打包部署(包含依赖jar包)
微服务必备 优点: 1.可以直接导入依赖jar包 2.可以添加插件启动 .sh 文件 3.插件的配置以及微服务的统一打包方式 1.首先我们需要在pom.xml中配置maven的assembly插件 & ...
- C# GDI+编程之Graphics类
GDI+是GDI的后继者,它是.NET Framework为操作图形提供的应用程序编程接口,主要用在窗体上绘制各种图形图像,可以用于绘制各种数据图像.数学仿真等. Graphics类是GDI+的核心, ...
- [java]我的数据在哪里?——数据的内存模型
在编写程序时,我们也许会有这样一个问题,我们编写的程序中的数据运行时,会保存在哪里呢?简单直接的回答可能是——内存.这个回答在多数情况下可能都是对的,但事实上并不准确,我们都知道内存,即随机访问存储器 ...
- SQL 游标的存储过程示例
注意事项:两个小数运算的时候都是一种类型! USE [FoodMedicineExam] GO /****** Object: StoredProcedure [dbo].[P_DrugExamAna ...
- vuex学习及使用
什么是vuex? 在SPA单页面组件的开发中vuex称为状态管理:简单的理解就是你在state中定义了一个数据之后,你可以在所在项目中的任何一个组件里进行获取.进行修改,并且你的修改可以得到全局的响应 ...
- C#实现微信AES-128-CBC加密数据的解密
小程序登录时,获得用户的信息,只是昵称,无法用作ID.而有用的数据,都加密着,腾讯给出了解密的方法: 加密数据解密算法 接口如果涉及敏感数据(如wx.getUserInfo当中的 openId 和un ...
- c# 获取客户端文件
/// <summary> /// 获取有效客户端文件控件集合,文件控件必须上传了内容,为空将被忽略, /// 注意:Form标记必须加入属性 enctype="multipar ...
- c# 获取本机IP
/// <summary> /// 获取本机IP /// </summary> /// <returns></returns> public stati ...
- 【原】通过BeanNameAutoProxyCreator改变臃肿代码
前言: 最近接手了一个项目,大概过了下需求,然后打开项目准备开搞的时候发现一个问题,这个项目是提供rest服务的一个web项目,其中很多旧系统由于还没改成微服务,所以只能通过HttpClient发起调 ...