记录:EM 算法估计混合高斯模型参数
当概率模型依赖于无法观测的隐性变量时,使用普通的极大似然估计法无法估计出概率模型中参数。此时需要利用优化的极大似然估计:EM算法。
在这里我只是想要使用这个EM算法估计混合高斯模型中的参数。由于直观原因,采用一维高斯分布。
一维高斯分布的概率密度函数表示为:
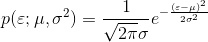
多个高斯分布叠加在一起形成混合高斯分布:
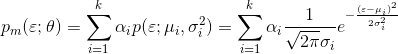
其中:k 表示一共有 k 个子分布,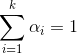 。为什么累加之和为 1?因为哪怕是混合模型也表示一个概率密度,从负无穷到正无穷积分概率为 1,所以只有累加之和为 1才能保证,很简单的推导。
。为什么累加之和为 1?因为哪怕是混合模型也表示一个概率密度,从负无穷到正无穷积分概率为 1,所以只有累加之和为 1才能保证,很简单的推导。
设总体 ξ,总体服从混合高斯分布。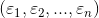 是一个取自总体的样本。罢了,公式编辑实在慢到令人发指,简单记录而已,手写。
是一个取自总体的样本。罢了,公式编辑实在慢到令人发指,简单记录而已,手写。
以下是关于一维混合高斯分布的参数估计推导过程:


参考:周志华《机器学习》
简单代码实现一下,代码很丑:
import numpy as np
import matplotlib.pyplot as plt # 使用 numpy 生成两组符合高斯分布(正态分布)的数据,然后将他们累加成混合模型,使用 EM 算法求解其中参数
# 假设两个分布累加的系数 α1=0.6,α2=0.4
# 假设 N1 分布的均值 μ1=1.7,方差 δ1²=0.57²=0.3249
# 假设 N2 分布的均值 μ2=3.5,方差 δ2²=0.33²=0.1089
np.random.seed(77)
num1 = 6000
num2 = 4000
X1 = np.random.normal(1.7, 0.57, num1).astype(np.float32)
X2 = np.random.normal(3.5, 0.33, num2).astype(np.float32)
X = np.hstack((X1, X2)) # 其中包含两个高斯分布的数据
np.random.shuffle(X) # 混洗数据 re_tuple = plt.hist(X, 300, density=1, facecolor='r')
plt.show() # 设置 EM 算法的初始值,任意设置
modulus = np.array([0.2, 0.8])
mean = np.array([1.1, 2.1])
var = np.array([1.2, 1.5]) # 首先计算每个样本点由每一个独立分布产生的概率,然后通过推导公式去更新参数
gamma_j_i = np.zeros((2, num1 + num2), dtype=np.float32) # 设置迭代次数
epochs = 100
for epoch in range(epochs):
print('开始第 %d 次迭代 ...' % (epoch + 1))
# E 步
part_1 = 1 / np.sqrt(2 * np.pi * var[0])
part_2 = 1 / np.sqrt(2 * np.pi * var[1])
for i in range(2):
part_i = 1 / np.sqrt(2 * np.pi * var[i])
for j in range(num1 + num2):
p_m = (modulus[0] * (part_1 * np.exp(-1 * ((X[j] - mean[0]) ** 2) / (2 * var[0]))) +
modulus[1] * (part_2 * np.exp(-1 * ((X[j] - mean[1]) ** 2) / (2 * var[1]))))
p_i = modulus[i] * (part_i * np.exp(-1 * ((X[j] - mean[i]) ** 2) / (2 * var[i])))
gamma_j_i[i, j] = p_i / p_m # 中间计算步骤
sum_gamma_j_i = np.sum(gamma_j_i, axis=1)
sum_for_mean = np.matmul(gamma_j_i, X)
sum_for_var = np.sum(gamma_j_i * np.square(np.broadcast_to(X, (2, num1 + num2)) - mean.reshape((2, 1))), axis=1) # M 步
for i in range(2):
mean[i] = sum_for_mean[i] / sum_gamma_j_i[i]
modulus[i] = sum_gamma_j_i[i] / (num1 + num2)
var[i] = sum_for_var[i] / sum_gamma_j_i[i] print('迭代 %d 次后得到的 N1 分布的比率、均值和方差分别为:%s %s %s' % (epoch + 1, modulus[0], mean[0], var[0]))
print('迭代 %d 次后得到的 N2 分布的比率、均值和方差分别为:%s %s %s' % (epoch + 1, modulus[1], mean[1], var[1]))
print() # 迭代 100 次后得到的结果是:
# N1: 0.59798 1.69166 0.33037
# N2: 0.40202 3.49959 0.11023
# 总之,结果还不错
记录:EM 算法估计混合高斯模型参数的更多相关文章
- EM算法与混合高斯模型
非常早就想看看EM算法,这个算法在HMM(隐马尔科夫模型)得到非常好的应用.这个算法公式太多就手写了这部分主体部分. 好的參考博客:最大似然预计到EM,讲了详细样例通熟易懂. JerryLead博客非 ...
- <转>与EM相关的两个算法-K-mean算法以及混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- EM相关两个算法 k-mean算法和混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- 机器学习3_EM算法与混合高斯模型
①EM算法: http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html 李航 <统计学习方法>9.1节 ②混合高斯模 ...
- [zz] 混合高斯模型 Gaussian Mixture Model
聚类(1)——混合高斯模型 Gaussian Mixture Model http://blog.csdn.net/jwh_bupt/article/details/7663885 聚类系列: 聚类( ...
- 混合高斯模型:opencv中MOG2的代码结构梳理
/* 头文件:OurGaussmix2.h */ #include "opencv2/core/core.hpp" #include <list> #include&q ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
- 混合高斯模型(Mixtures of Gaussians)和EM算法
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类别标签用表示 ...
- PRML读书会第九章 Mixture Models and EM(Kmeans,混合高斯模型,Expectation Maximization)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:10:56 今天的主要内容有k-means.混合高斯模型. EM算法.对于k-me ...
随机推荐
- 安装VisualSVN Server 报"Service 'VisualSVN Server' failed to start. Please check VisualSVN Server log in Event Viewer for more details"错误.原因是启动"VisualSVN Server"失败
安装VisualSVN Server 报"Service 'VisualSVN Server' failed to start. Please check VisualSVN Server ...
- [JSON_01] JSON 解析
0. 说明 介绍 && 测试 JSON 1. 介绍 XML 指可扩展标记语言(eXtensible Markup Language). XML 被设计用来传输和存储数据. JSON: ...
- 学生与部门管理app-产品功能与界面的简单设计
学生与部门管理app-产品功能与界面的简单设计 1. 结对成员学号 我:********* 大佬:*******10 2. 需求分析(NABCD模型) 2.1 N-需求 各个部门在开学初占据学校青春广 ...
- 这不是我想要的ABAP开发者
原文在此: These Aren’t the Developers You’re Looking for 在吃饼干的过程中偶然看到这篇文章,立刻被UC化的标题吸引到了. 全文读完,感觉作者还是有点刻薄 ...
- 780. Reaching Points
idea: 1.从后向前找 2.while (tx > ty) tx -= ty; 替为 % 操作 3.经过循环后,必定只有两种情况才true sx == tx && sy &l ...
- $Matrix-Tree$定理-题目
$Matrix-Tree$ 其实矩阵树的题挺好玩的,一些是套班子求答案的,也有一些题目是靠观察基尔霍夫矩阵性质推式子的. 文艺计算姬:https://www.lydsy.com/JudgeOnline ...
- Vue:渲染、指令、事件、组件、Props
每天学习一点点 编程PDF电子书免费下载: http://www.shitanlife.com/code 如果要我用一句话描述使用 Vue 的经历,我可能会说“它如此合乎常理”或者“它提供给我需要的工 ...
- redis命令大全参考手册
redis功能强大,支持数据类型丰富,以下是redis操作命令大全,基本上涵盖了redis所有的命令,并附有解释说明,大家可以收藏.参考,你一定要知道的是:redis的key名要区分大小写,在redi ...
- 卡尔曼滤波跟踪 opencv
0 卡尔曼OPENCV 预测鼠标位置 卡尔曼滤波不要求信号和噪声都是平稳过程的假设条件.对于每个时刻的系统扰动和观测误差(即噪声),只要对它们的统计性质作某些适当的假定,通过对含有噪声的观测信号进行处 ...
- 转 一个web项目web.xml的配置中<context-param>配置作用
一个web项目web.xml的配置中<context-param>配置作用 <context-param>的作用:web.xml的配置中<context-param& ...