搭建hbase1.2.5完全分布式集群
简介
有一段时间,没写博客了,因为公司开发分布式调用链追踪系统,用到hbase,在这里记录一下搭建过程
1、集群如下:
| ip | 主机名 | 角色 |
| 192.168.6.130 | node1.jacky.com | maser |
| 192.168.6.131 | node2.jacky.com | slave |
| 192.168.6.132 | node3.jacky.com | slave |
2、文件如下:
[root@node1 software]# ll
总用量
-rw-r--r--. root root 9月 : hadoop-2.7..tar.gz
-rw-r--r--. root root 9月 : hbase-1.2.-bin.tar.gz
-rwxr-xr-x. root root 9月 : jdk-8u11-linux-x64.rpm
-rw-r--r--. root root 10月 zookeeper-3.4..tar.gz
说明:安装hbase之前,需要安装hadoop环境(hbase用到hadoop的hdfs),需要zookeeper环境,需要jdk环境
3、安装hadoop、centos7.0环境配置
3.1、修改3台机器的hosts文件,配置ip和主机名映射
[root@node1 jacky]# vim /etc/hosts
在文件后面添加内容为:
192.168.6.130 node1.jacky.com
192.168.6.131 node2.jacky.com
192.168.6.132 node3.jacky.com
3.2、修改3台机器hostname文件
在192.168.6.130机器中修改,修改hostname为
[root@node1 jacky]# cat /etc/hostname
node1.jacky.com
很显然另外两台技术设置的主机名分别为node2.jacky.com和node3.jacky.com
3.3、配置192.168.6.130可以免密码登录192.168.6.131和192.168.6.132
步骤:
- 生成公钥和私钥
- 修改公钥名称为authorized_keys
[root@node1 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:pvR6iWfppGPSFZlAqP35/6DEtGTvaMY64otThWoBTuk root@localhost.localdomain
The key's randomart image is:
+---[RSA ]----+
| . o. |
|.o . . |
|+. o . . o |
| Eo o . + |
| o o..S. |
| o ..oO.o |
| . . ..=*oo |
| ..o *=@+ . |
| .oo=+@+.o.. |
+----[SHA256]-----+
[root@node1 .ssh]# cp id_rsa.pub authorized_keys
[root@node1 .ssh]# chmod 777 authorized_keys #修改文件权限
说明:
authorized_keys:存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥
id_rsa : 生成的私钥文件
id_rsa.pub : 生成的公钥文件
know_hosts : 已知的主机公钥清单
[root@node1 .ssh]# ssh-copy-id -i root@node1.jacky.com 到自己
[root@node1 .ssh]# ssh-copy-id -i root@node2.jacky.com
[root@node1 .ssh]# ssh-copy-id -i root@node3.jacky.com
3.4、配置hadoop的环境变量
[root@node1 software]# vim /etc/profile
# hadoop
export HADOOP_HOME=/usr/local/hadoop-2.7.
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
输入 source /etc/profile 使配置文件生效。
[root@node1 software]# source /etc/profile
4、hadoop配置
4.1、上传hadoop文件
[root@node1 software]# ll
总用量
-rw-r--r--. root root 9月 : hadoop-2.7..tar.gz
-rw-r--r--. root root 9月 : hbase-1.2.-bin.tar.gz
-rwxr-xr-x. root root 9月 : jdk-8u11-linux-x64.rpm
-rw-r--r--. root root 10月 zookeeper-3.4..tar.gz
[root@node1 software]# pwd
/usr/software
[root@node1 software]#
说明:我把hadoop-2.7.3.tar.gz上传到/usr/software
4.2、配置hadoop-env.sh文件
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1..0_11
4.3、配置yarn-env.sh文件
export JAVA_HOME=/usr/java/jdk1..0_11
4.4、修改slaves文件,指定master的小弟,在master机器上,sbin目录下只执行start-all.sh,能够启动所有slave的DataNode和NodeManager
[root@node1 hadoop]# cat slaves
node2.jacky.com
node3.jacky.com
4.5、修改hadoop核心配置文件core-site.xml
<configuration>
<!--配置hadoop使用的文件系统,配置hadoop内置的文件系统-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1.jacky.com:9000</value>
</property>
<!--配置hadoop数据目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7./tmp</value>
</property>
</configuration>
说明:目录/usr/local/hadoop-2.7.3/tmp,是自己新建的
4.6、修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1.jacky.com:</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop-2.7./hadoop/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop-2.7./hadoop/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4.7、修改mapred-site.xml文件
<configuration>
<!--mapreduce配置在yarn集群上跑-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1.jacky.com:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1.jacky.com:</value>
</property>
</configuration>
4.8、修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置yarn的master-->
<property>
<name>yarn.resourcemanager.address</name>
<value>node1.jacky.com:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1.jacky.com:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1.jacky.com:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1.jacky.com:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1.jacky.com:</value>
</property>
</configuration>
4.9、然后把在master的配置拷贝到node2.jacky.com和node3.jacky.com节点上
[root@node1 hadoop-2.7.3]# scp -r hadoop-2.7. root@node2.jacky.com:/usr/local/
[root@node1 hadoop-2.7.3]# scp -r hadoop-2.7. root@node3.jacky.com:/usr/local/
5、启动hadoop
5.1、格式化hadoop
[root@node1 hadoop-2.7.]# hdfs namenode -format
5.2、启动hadoop
[root@node1 sbin]# start-all.sh
5.3、用jps命令查看三台机器上hadoop有没起来
192.168.6.130
[root@node1 sbin]# jps
QuorumPeerMain
NameNode
ResourceManager
Jps
SecondaryNameNode
192.168.6.131
[root@node2 jacky]# jps
Jps
DataNode
QuorumPeerMain
NodeManager
192.168.6.132
[root@node2 jacky]# jps
Jps
DataNode
QuorumPeerMain
NodeManager
5.4、界面查看验证
http://192.168.6.130:8088/cluster/nodes
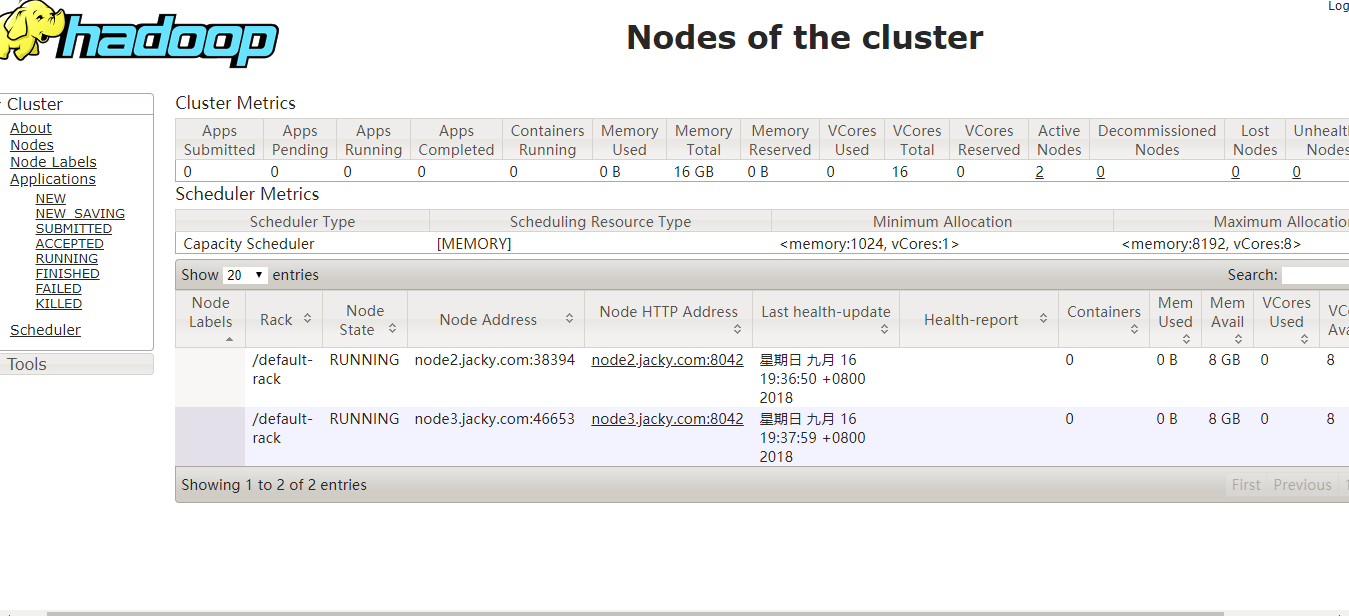
查看dataNode是否启动
http://192.168.6.130:50070/
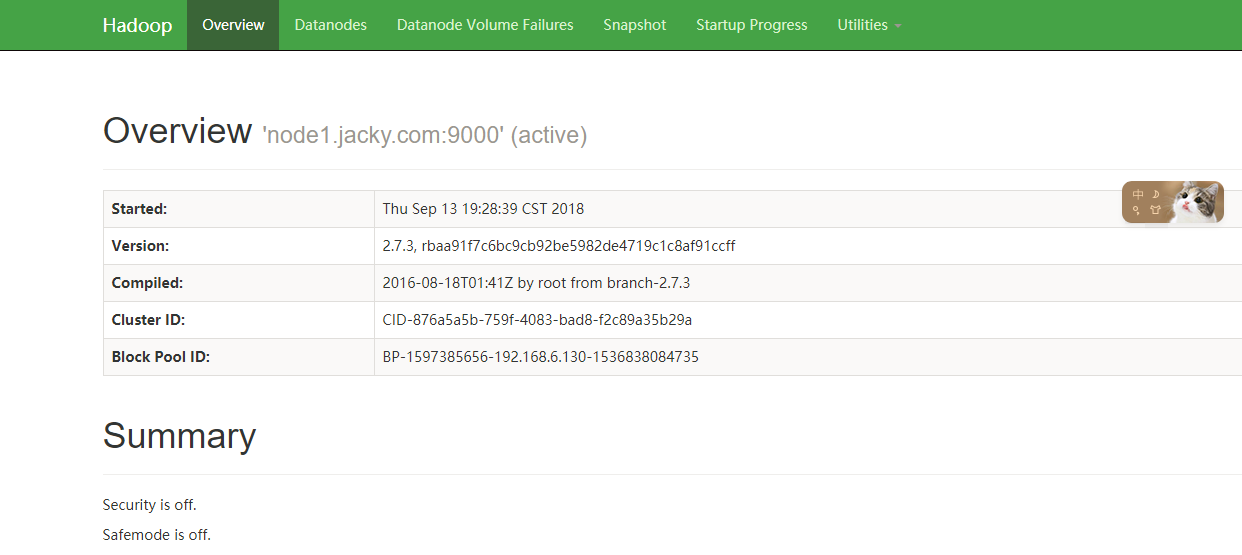
好了,到这里,hadoop-2.7.3完全分布式集群搭建成功了,接下来我们将进入hbase搭建
6、hbase完全分布式集群搭建
6.1、上传到文件到/usr/software目录下,解压到/usr/local目录下
[root@node2 software]# ll
总用量
-rw-r--r--. root root 9月 : hadoop-2.7..tar.gz
-rw-r--r--. root root 9月 : hbase-1.2.-bin.tar.gz
-rw-r--r--. root root 10月 zookeeper-3.4..tar.gz
[root@node2 software]# pwd
/usr/software
[root@node2 software]# tar -xvzf hbase-1.2.5-bin.tar.gz -C /usr/local/
6.2、配置hbase环境变量vim /etc/profile
#hbase
export HBASE_HOME=/usr/local/hbase-1.2.
export PATH=$HBASE_HOME/bin:$PATH
执行 source /etc/profile,让配置生效
6.3、创建目录tmp
[root@node2 hbase-1.2.]# /usr/local/hbase-1.2./tmp
6.4、配置hbase-env.sh
export JAVA_HOME=/usr/java/jdk1..0_11 # Extra Java CLASSPATH elements. Optional.
export HBASE_CLASSPATH=/usr/local/hadoop-2.7./etc/hadoop
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false 默认是true
6.5、配置hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1.jacky.com:9000/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>node1.jacky.com</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase-1.2./tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value></value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1.jacky.com,node2.jacky.com,node3.jacky.com</value>
</property>
<property>
<name>hbase.zoopkeeper.property.dataDir</name>
<value>/usr/local/zookeeper-3.4./data</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value></value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
6.6、配置regionservers,其实就是配置master的小弟
node2.jacky.com
node3.jacky.com
6.7、用scp 命令把配置好的hbase程序分发到各个机器上
scp hbase-1.2. root@node2.jacky.com:/usr/local
scp hbase-1.2. root@node3.jacky.com:/usr/local
7、启动hbase,只需要在master机器上执行
[root@node1 bin]# ./start-hbase.sh
node3.jacky.com: starting zookeeper, logging to /usr/local/hbase-1.2./bin/../logs/hbase-root-zookeeper-node3.jacky.com.out
node2.jacky.com: starting zookeeper, logging to /usr/local/hbase-1.2./bin/../logs/hbase-root-zookeeper-node2.jacky.com.out
node1.jacky.com: starting zookeeper, logging to /usr/local/hbase-1.2./bin/../logs/hbase-root-zookeeper-node1.jacky.com.out
starting master, logging to /usr/local/hbase-1.2./logs/hbase-jacky-master-node1.jacky.com.out
node2.jacky.com: starting regionserver, logging to /usr/local/hbase-1.2./bin/../logs/hbase-root-regionserver-node2.jacky.com.out
node3.jacky.com: starting regionserver, logging to /usr/local/hbase-1.2./bin/../logs/hbase-root-regionserver-node3.jacky.com.out
node2.jacky.com: Java HotSpot(TM) -Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node2.jacky.com: Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
[root@node1 bin]#
7.1、通过jps查看hbase进程
192.168.6.130
[root@node1 bin]# jps
QuorumPeerMain
HMaster
NameNode
ResourceManager
SecondaryNameNode
Jps
192.168.131
[root@node2 local]# jps
DataNode
QuorumPeerMain
HRegionServer
NodeManager
Jps
192.168.6.132
[root@node2 local]# jps
DataNode
QuorumPeerMain
HRegionServer
NodeManager
Jps
7.2、通过打开页面验证
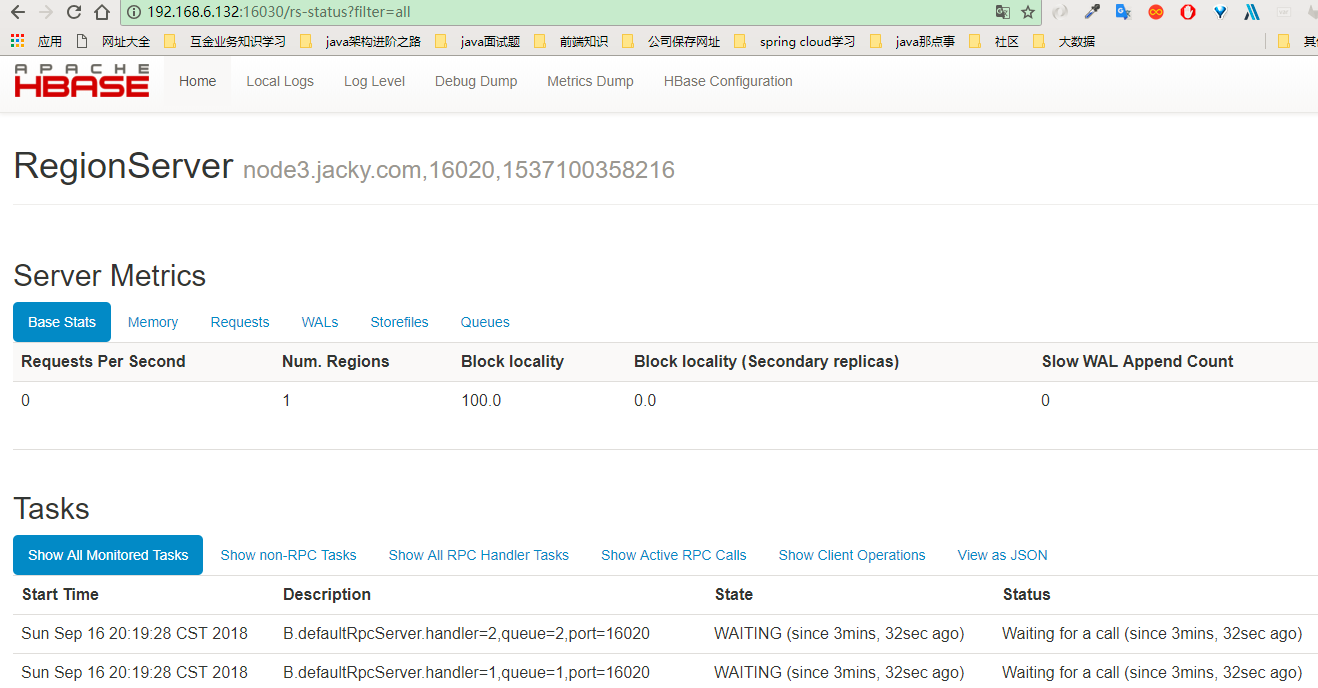
到这里hbase完全分布式集群就搭建完成了
欢迎关注
搭建hbase1.2.5完全分布式集群的更多相关文章
- 基于hadoop2.6.0搭建5个节点的分布式集群
1.前言 我们使用hadoop2.6.0版本配置Hadoop集群,同时配置NameNode+HA.ResourceManager+HA,并使用zookeeper来管理Hadoop集群 2.规划 1.主 ...
- 摘要: CentOS 6.5搭建Redis3.2.8伪分布式集群
from https://my.oschina.net/ososchina/blog/856678 摘要: CentOS 6.5搭建Redis3.2.8伪分布式集群 前言 最近在服务器上搭建了 ...
- 搭建Hadoop2.7.1的分布式集群
Hadoop 2.7.1 (2015-7-6更新),hadoop的环境配置不是特别的复杂,但是确实有很多细节需要注意,不然会造成许多配置错误的情况.尽量保证一次配置正确防止反复修改. 网上教程有很多关 ...
- Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群(单点) Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.1防火墙,静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略,参考 ...
- # 从零開始搭建Hadoop2.7.1的分布式集群
Hadoop 2.7.1 (2015-7-6更新),Hadoop的环境配置不是特别的复杂,可是确实有非常多细节须要注意.不然会造成很多配置错误的情况.尽量保证一次配置正确防止重复改动. 网上教程有非常 ...
- CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群搭建 Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.2 关闭防火墙,设置静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略 ...
- Nginx之搭建反向代理实现tomcat分布式集群
参考博文: Nginx反向代理实现Tomcat分布式集群 1. jdk 安装 jdk 下载网址: http://www.oracle.com/technetwork/java/javase/downl ...
- 搭建基于docker 的redis分布式集群在docker for windows
https://blog.csdn.net/xielinrui123/article/details/85104446 首先在docker中下载使用 docker pull redis:3.0.7do ...
- mac 下搭建Elasticsearch 5.4.3分布式集群
一.集群角色 多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点.Zen发现是ES自带的默认发现机制,使 ...
随机推荐
- re模块、hashlib模块
一.re模块 1.什么是正则? 正则就是用一系列具有特殊含义的字符组成一套规则,该规则用来描述具有某一特征的字符串,正则就是用来去一个大的字符串中匹配出符合规则的子字符串 2.为何要用正则? 用户注册 ...
- 初窥Java--2(下载Eclipse,安装tomcat插件)
一.软件下载 Eclipse3.6 IDE for Java EE Developers: 下载地址:http://eclipse.org/downloads/ Tomcat Eclipse Plug ...
- error :expected initializer before
很可能头文件或者前面的某个定义少了个:
- [P1034][NOIP2001]一元三次方程求解 (二分)
二分 #include<bits/stdc++.h> using namespace std; double a,b,c,d; double fc(double x) { )+b*pow( ...
- 3ds max学习笔记(三)--视点显示控制
显示模式:1.模型一般是以实体方式显示的,若想看线框方式,摁F3:返回实体,摁F3:2.实体加线框模式显示,摁F4:返回,摁F4:3.透明效果:ALT+X,透明显示,之后F4,显示线框:程序内的其他显 ...
- PAT基础6-2
6-2 多项式求值 (15 分) 本题要求实现一个函数,计算阶数为n,系数为a[0] ... a[n]的多项式f(x)=∑i=0n(a[i]×xi) 在x点的值. 函数接口定义: dou ...
- std::lock_guard/std::unique_lock
C++多线程编程中通常会对共享的数据进行写保护,以防止多线程在对共享数据成员进行读写时造成资源争抢导致程序出现未定义的行为.通常的做法是在修改共享数据成员的时候进行加锁--mutex.在使用锁的时候通 ...
- ACM-ICPC 2018 南京赛区网络预赛 E题
ACM-ICPC 2018 南京赛区网络预赛 E题 题目链接: https://nanti.jisuanke.com/t/30994 Dlsj is competing in a contest wi ...
- log4j2发送消息至Kafka
title: 自定义log4j2发送日志到Kafka tags: log4j2,kafka 为了给公司的大数据平台提供各项目组的日志,而又使各项目组在改动上无感知.做了一番调研后才发现log4j2默认 ...
- WordPress主题开发:按分类调用文章
调用catid为2的分类下的文章,就是后台分类链接的tag_ID <?php $cat_query = new WP_Query(array( 'cat' => '2' )); ?> ...