ELK学习笔记之基于kakfa (confluent)搭建ELK
0x00 概述
测试搭建一个使用kafka作为消息队列的ELK环境,数据采集转换实现结构如下:
F5 HSL–>logstash(流处理)–> kafka –>elasticsearch
测试中的elk版本为6.3, confluent版本是4.1.1
希望实现的效果是 HSL发送的日志胫骨logstash进行流处理后输出为json,该json类容原样直接保存到kafka中,kafka不再做其它方面的格式处理。
0x01 测试
192.168.214.138: 安装 logstash,confluent环境
192.168.214.137: 安装ELK套件(停用logstash,只启动es和kibana)
confluent安装调试备忘:
- 像安装elk环境一样,安装java环境先
- 首先在不考虑kafka的情形下,实现F5 HSL—Logstash–ES的正常运行,并实现简单的正常kibana的展现。后面改用kafka时候直接将这里output修改为kafka plugin配置即可。
此时logstash的相关配置
input {
udp {
port => 8514
type => 'f5-dns'
}
}
filter {
if [type] == 'f5-dns' {
grok {
match => { "message" => "%{HOSTNAME:F5hostname} %{IP:clientip} %{POSINT:clientport} %{IP:svrip} %{NUMBER:qid} %{HOSTNAME:qname} %{GREEDYDA
TA:qtype} %{GREEDYDATA:status} %{GREEDYDATA:origin}" }
}
geoip {
source => "clientip"
target => "geoip"
}
}
}
output {
#stdout{ codec => rubydebug }
#elasticsearch {
# hosts => ["192.168.214.137:9200"]
# index => "f5-dns-%{+YYYY.MM.dd}"
#template_name => "f5-dns"
#}
kafka {
codec => json
bootstrap_servers => "localhost:9092"
topic_id => "f5-dns-kafka"
}
}
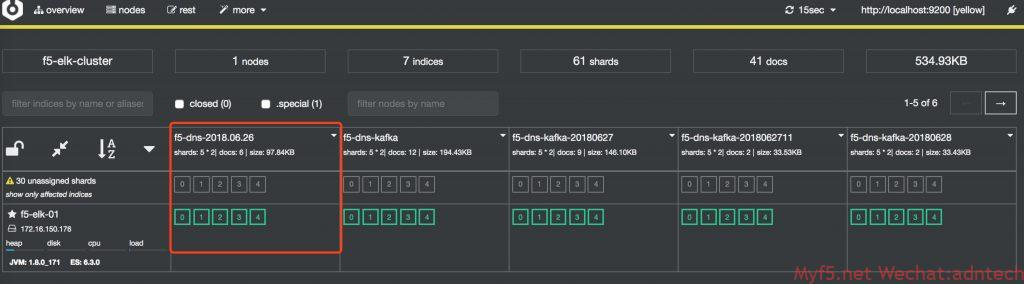
发一些测试流量,确认es正常收到数据,查看cerebro上显示的状态。(截图是调试完毕后截图)
# cd /usr/share/cerebro/cerebro-0.8.1/
# /bin/cerebro -Dhttp.port=9110 -Dhttp.address=0.0.0.0
安装confluent,由于是测试环境,直接confluent官方网站下载压缩包,解压后使用。位置在/root/confluent-4.1.1/下
由于是测试环境,直接用confluent的命令行来启动所有相关服务,发现kakfa启动失败
[root@kafka-logstash bin]# ./confluent start
Using CONFLUENT_CURRENT: /tmp/confluent.dA0KYIWj
Starting zookeeper
zookeeper is [UP]
Starting kafka
/Kafka failed to start
kafka is [DOWN]
Cannot start Schema Registry, Kafka Server is not running. Check your deployment
检查发现由于虚机内存给太少了,导致java无法分配足够内存给kafka
[root@kafka-logstash bin]# ./kafka-server-start ../etc/kafka/server.properties
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12)
扩大虚拟机内存,并将logstash的jvm配置中设置的内存调小
kafka server配置文件
[root@kafka-logstash kafka]# pwd
/root/confluent-4.1.1/etc/kafka
[root@kafka-logstash kafka]# egrep -v "^#|^$" server.properties
broker.id=0
listeners=PLAINTEXT://localhost:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000
confluent.support.metrics.enable=true
confluent.support.customer.id=anonymous
group.initial.rebalance.delay.ms=0
connect 配置文件,此配置中,将原来的avro converter替换成了json,同时关闭了key vlaue的schema识别。因为我们输入的内容是直接的json类容,没有相关schema,这里只是希望kafka原样解析logstash输出的json内容到es
[root@kafka-logstash kafka]# pwd
/root/confluent-4.1.1/etc/kafka
[root@kafka-logstash kafka]# egrep -v "^#|^$" connect-standalone.properties
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
plugin.path=share/java
如果不做上述修改,connect总会在将日志sink到ES时提示无法反序列化,magic byte错误等。如果使用confluent status命令查看,会发现connect会从up变为down
[root@kafka-logstash confluent-4.1.1]# ./bin/confluent status
ksql-server is [DOWN]
connect is [DOWN]
kafka-rest is [UP]
schema-registry is [UP]
kafka is [UP]
zookeeper is [UP]
schema-registry 相关配置
[root@kafka-logstash schema-registry]# pwd
/root/confluent-4.1.1/etc/schema-registry
[root@kafka-logstash schema-registry]# egrep -v "^#|^$"
connect-avro-distributed.properties connect-avro-standalone.properties log4j.properties schema-registry.properties
[root@kafka-logstash schema-registry]# egrep -v "^#|^$" connect-avro-standalone.properties
bootstrap.servers=localhost:9092
key.converter.schema.registry.url=http://localhost:8081
value.converter.schema.registry.url=http://localhost:8081
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
plugin.path=share/java
[root@kafka-logstash schema-registry]# egrep -v "^#|^$" schema-registry.properties
listeners=http://0.0.0.0:8081
kafkastore.connection.url=localhost:2181
kafkastore.topic=_schemas
debug=false
es-connector的配置文件
[root@kafka-logstash kafka-connect-elasticsearch]# pwd
/root/confluent-4.1.1/etc/kafka-connect-elasticsearch
[root@kafka-logstash kafka-connect-elasticsearch]# egrep -v "^#|^$" quickstart-elasticsearch.properties
name=f5-dns
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=f5-dns-kafka
key.ignore=true
value.ignore=true
schema.ignore=true
connection.url=http://192.168.214.137:9200
type.name=doc
transforms=MyRouter
transforms.MyRouter.type=org.apache.kafka.connect.transforms.TimestampRouter
transforms.MyRouter.topic.format=${topic}-${timestamp}
transforms.MyRouter.timestamp.format=yyyyMMdd
上述配置中topics配置是希望传输到ES的topic,通过设置transform的timestamp router来实现将topic按天动态映射为ES中的index,这样可以让ES每天产生一个index。注意需要配置schema.ignore=true,否则kafka无法将受收到的数据发送到ES上,connect的 connect.stdout 日志会显示:
[root@kafka-logstash connect]# pwd
/tmp/confluent.dA0KYIWj/connect Caused by: org.apache.kafka.connect.errors.DataException: Cannot infer mapping without schema.
at io.confluent.connect.elasticsearch.Mapping.inferMapping(Mapping.java:84)
at io.confluent.connect.elasticsearch.jest.JestElasticsearchClient.createMapping(JestElasticsearchClient.java:221)
at io.confluent.connect.elasticsearch.Mapping.createMapping(Mapping.java:66)
at io.confluent.connect.elasticsearch.ElasticsearchWriter.write(ElasticsearchWriter.java:260)
at io.confluent.connect.elasticsearch.ElasticsearchSinkTask.put(ElasticsearchSinkTask.java:162)
at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:524)
配置修正完毕后,向logstash发送数据,发现日志已经可以正常发送到了ES上,且格式和没有kafka时是一致的。
没有kafka时:
{
"_index": "f5-dns-2018.06.26",
"_type": "doc",
"_id": "KrddO2QBXB-i0ay0g5G9",
"_version": 1,
"_score": 1,
"_source": {
"message": "localhost.lan 202.202.102.100 53777 172.16.199.136 42487 www.test.com A NOERROR GTM_REWRITE ",
"F5hostname": "localhost.lan",
"qid": "42487",
"clientip": "202.202.102.100",
"geoip": {
"region_name": "Chongqing",
"location": {
"lon": 106.5528,
"lat": 29.5628
},
"country_code2": "CN",
"timezone": "Asia/Shanghai",
"country_name": "China",
"region_code": "50",
"continent_code": "AS",
"city_name": "Chongqing",
"country_code3": "CN",
"ip": "202.202.102.100",
"latitude": 29.5628,
"longitude": 106.5528
},
"status": "NOERROR",
"qname": "www.test.com",
"clientport": "53777",
"@version": "1",
"@timestamp": "2018-06-26T09:12:21.585Z",
"host": "192.168.214.1",
"type": "f5-dns",
"qtype": "A",
"origin": "GTM_REWRITE ",
"svrip": "172.16.199.136"
}
}
有kafka时:
{
"_index": "f5-dns-kafka-20180628",
"_type": "doc",
"_id": "f5-dns-kafka-20180628+0+23",
"_version": 1,
"_score": 1,
"_source": {
"F5hostname": "localhost.lan",
"geoip": {
"city_name": "Chongqing",
"timezone": "Asia/Shanghai",
"ip": "202.202.100.100",
"latitude": 29.5628,
"country_name": "China",
"country_code2": "CN",
"continent_code": "AS",
"country_code3": "CN",
"region_name": "Chongqing",
"location": {
"lon": 106.5528,
"lat": 29.5628
},
"region_code": "50",
"longitude": 106.5528
},
"qtype": "A",
"origin": "DNSX ",
"type": "f5-dns",
"message": "localhost.lan 202.202.100.100 53777 172.16.199.136 42487 www.myf5.net A NOERROR DNSX ",
"qid": "42487",
"clientport": "53777",
"@timestamp": "2018-06-28T09:05:20.594Z",
"clientip": "202.202.100.100",
"qname": "www.myf5.net",
"host": "192.168.214.1",
"@version": "1",
"svrip": "172.16.199.136",
"status": "NOERROR"
}
}
相关REST API输出
http://192.168.214.138:8083/connectors/elasticsearch-sink/tasks [
{
"id": {
"connector": "elasticsearch-sink",
"task": 0
},
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "doc",
"value.ignore": "true",
"tasks.max": "1",
"topics": "f5-dns-kafka",
"transforms.MyRouter.topic.format": "${topic}-${timestamp}",
"transforms": "MyRouter",
"key.ignore": "true",
"schema.ignore": "true",
"transforms.MyRouter.timestamp.format": "yyyyMMdd",
"task.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkTask",
"name": "elasticsearch-sink",
"connection.url": "http://192.168.214.137:9200",
"transforms.MyRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter"
}
}
] http://192.168.214.138:8083/connectors/elasticsearch-sink/
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "doc",
"value.ignore": "true",
"tasks.max": "1",
"topics": "f5-dns-kafka",
"transforms.MyRouter.topic.format": "${topic}-${timestamp}",
"transforms": "MyRouter",
"key.ignore": "true",
"schema.ignore": "true",
"transforms.MyRouter.timestamp.format": "yyyyMMdd",
"name": "elasticsearch-sink",
"connection.url": "http://192.168.214.137:9200",
"transforms.MyRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter"
},
"tasks": [
{
"connector": "elasticsearch-sink",
"task": 0
}
],
"type": "sink"
} http://192.168.214.138:8083/connectors/elasticsearch-sink/status
{
"name": "elasticsearch-sink",
"connector": {
"state": "RUNNING",
"worker_id": "172.16.150.179:8083"
},
"tasks": [
{
"state": "RUNNING",
"id": 0,
"worker_id": "172.16.150.179:8083"
}
],
"type": "sink"
}
http://192.168.214.138:8082/brokers
{
"brokers": [
0
]
} http://192.168.214.138:8082/topics
[
"__confluent.support.metrics",
"_confluent-ksql-default__command_topic",
"_schemas",
"connect-configs",
"connect-offsets",
"connect-statuses",
"f5-dns-2018.06",
"f5-dns-2018.06.27",
"f5-dns-kafka",
"test-elasticsearch-sink"
] http://192.168.214.138:8082/topics/f5-dns-kafka
{
"name": "f5-dns-kafka",
"configs": {
"file.delete.delay.ms": "60000",
"segment.ms": "604800000",
"min.compaction.lag.ms": "0",
"retention.bytes": "-1",
"segment.index.bytes": "10485760",
"cleanup.policy": "delete",
"follower.replication.throttled.replicas": "",
"message.timestamp.difference.max.ms": "9223372036854775807",
"segment.jitter.ms": "0",
"preallocate": "false",
"segment.bytes": "1073741824",
"message.timestamp.type": "CreateTime",
"message.format.version": "1.1-IV0",
"max.message.bytes": "1000012",
"unclean.leader.election.enable": "false",
"retention.ms": "604800000",
"flush.ms": "9223372036854775807",
"delete.retention.ms": "86400000",
"leader.replication.throttled.replicas": "",
"min.insync.replicas": "1",
"flush.messages": "9223372036854775807",
"compression.type": "producer",
"min.cleanable.dirty.ratio": "0.5",
"index.interval.bytes": "4096"
},
"partitions": [
{
"partition": 0,
"leader": 0,
"replicas": [
{
"broker": 0,
"leader": true,
"in_sync": true
}
]
}
]
}
测试中kafka的配置基本都为确实配置,没有考虑任何的内存优化,kafka使用磁盘的大小考虑等
测试参考:
https://docs.confluent.io/current/installation/installing_cp.html
https://docs.confluent.io/current/connect/connect-elasticsearch/docs/elasticsearch_connector.html
https://docs.confluent.io/current/connect/connect-elasticsearch/docs/configuration_options.html
存储机制参考 https://blog.csdn.net/opensure/article/details/46048589
kafka配置参数参考 https://blog.csdn.net/lizhitao/article/details/25667831
更多kafka原理 https://blog.csdn.net/ychenfeng/article/details/74980531
confluent CLI:
confluent: A command line interface to manage Confluent services
Usage: confluent <command> [<subcommand>] [<parameters>]
These are the available commands:
acl Specify acl for a service.
config Configure a connector.
current Get the path of the data and logs of the services managed by the current confluent run.
destroy Delete the data and logs of the current confluent run.
list List available services.
load Load a connector.
log Read or tail the log of a service.
start Start all services or a specific service along with its dependencies
status Get the status of all services or the status of a specific service along with its dependencies.
stop Stop all services or a specific service along with the services depending on it.
top Track resource usage of a service.
unload Unload a connector.
'confluent help' lists available commands. See 'confluent help <command>' to read about a
specific command.
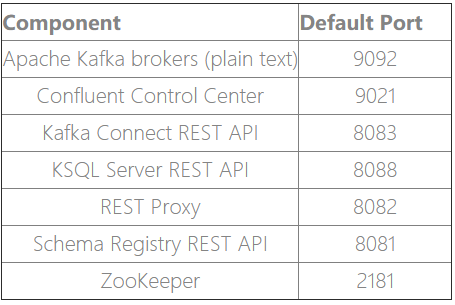
confluent platform 服务端口表
参考
ELK学习笔记之基于kakfa (confluent)搭建ELK的更多相关文章
- Solr学习笔记之1、环境搭建
Solr学习笔记之1.环境搭建 一.下载相关安装包 1.JDK 2.Tomcat 3.Solr 此文所用软件包版本如下: 操作系统:Win7 64位 JDK:jdk-7u25-windows-i586 ...
- ESP32学习笔记(一) 环境搭建与下载
ESP32学习笔记(一) 环境搭建与下载 作者:Nevel 博客:nevel.cnblogs.com 转载请保留出处 前几天刚入手了ESP32模块,趁着放假有时间,我们先把ESP32的编译环境搭建好 ...
- RocketMQ学习笔记(16)----RocketMQ搭建双主双从(异步复制)集群
1. 修改RocketMQ默认启动端口 由于只有两台机器,部署双主双从需要四个节点,所以只能修改rocketmq的默认启动端口,从官网下载rocketmq的source文件,解压后使用idea打开,全 ...
- RocketMQ学习笔记(4)----RocketMQ搭建双Master集群
前面已经学习了RockeMQ的四种集群方式,接下来就来搭建一个双Master(2m)的集群环境. 1. 双Master服务器环境 序号 ip 用户名 密码 角色 模式 (1) 47.105.145.1 ...
- Java学习笔记【一、环境搭建】
今天把java的学习重新拾起来,一方面是因为公司的项目需要用到大数据方面的东西,需要用java做语言 另一方面是原先使用的C#公司也在慢慢替换为java,为了以后路宽一些吧,技多不压身 此次的学习目标 ...
- ZooKeeper学习笔记一:集群搭建
作者:Grey 原文地址:ZooKeeper学习笔记一:集群搭建 说明 单机版的zk安装和运行参考:https://zookeeper.apache.org/doc/r3.6.3/zookeeperS ...
- ELK学习笔记之CentOS 7下ELK(6.2.4)++LogStash+Filebeat+Log4j日志集成环境搭建
0x00 简介 现在的公司由于绝大部分项目都采用分布式架构,很早就采用ELK了,只不过最近因为额外的工作需要,仔细的研究了分布式系统中,怎么样的日志规范和架构才是合理和能够有效提高问题排查效率的. 经 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
随机推荐
- N76E003的环境搭建
一.准备工作: 1.下载编译工具keil c51 2.下载N76E003提供的板级支持包(BSP),可到nuvoton上下载 二.开发环境搭建 1.安装keil c51,然后和谐...不能随便发链 ...
- 将ubuntu的home迁移至第二块磁盘
在忍受了一整周的磁盘将满的报警之后,今天终于着手准备将占据64G磁盘中的44G的Home迁移至另外一块磁盘,当然,这也是使用Linux做PC OS的正确使用方式.在Linux的目录管理风格的基础上,这 ...
- [git] 能在关键时刻救命的git指令
* 查看所有分支的所有操作记录(关键时刻能救命) git reflog
- Cookiecutter: 更好的项目模板工具:(1)简介及可用资源汇总
原文档地址:https://cookiecutter.readthedocs.io/en/latest/ 本系列只介绍cookiecutter的基础使用,而且会删除与功能使用无关的部分.深度使用及了解 ...
- Docker学习笔记之二:制作镜像并PUSH
Pull 如果是Public的(docker官方仓库和加速器) 直接 docker pull ubuntu:16.04 即可 若是私有的 首先登陆 docker login 仓库Host 之后 doc ...
- windows 下面必备软件
弹窗拦截软件 http://www.pc6.com/pc/tcguanggaolj/
- Java高并发系列 — AQS
只懂volatile和CAS是不是可以无视concurrent包了呢,发现一个好链接,继续死磕,第一日: 首先,我承认很多时候要去看源码才能更好搞懂一些事,但如果站在巨人肩膀上呢?有了大概思想源码看还 ...
- Yarn Node Labels
Yarn Node Labels + Capacity-Scheduler 在yarn-site.xml中开启capacity-schedule yarn-site.xml <property& ...
- 合并两个git仓库并保留提交记录
case如下: 有2个git仓库:repo1.repo2: 想将repo1中的文件移入repo2: repo1的历史日志要保留: 1 2 # 1.将repo1作为远程仓库,添加到repo2中,设置 ...
- Python学习之旅(十)
Python基础知识(9):函数(Ⅰ) Python中函数的定义:是逻辑结构和过程化的一种编程方法 定义方法: def test(x): #def:定义函数的关键字 test:函数名 x:形参,也可以 ...