并发容器——ConcurrentHashMap
ConcurreentHashMap的实现原理与使用
ConcurrentHashMap是线程安全且高效的HashMap。
为什么要使用ConcurrentHashMap
在并发编程中使用HashMap可能导致程序死循环。而使用线程安全的HashTable效率又非常低下,基于以上两个原因,便有了ConcurrentHashMap的登场机会。
线程不安全的HashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,,就会产生死循环获取Entry。
效率低下的HashTable
HashTable容器使用了synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。
ConcurrentHashMap的锁分段技术可有效提升并发访问率
容器里有很多把锁,每一把锁用于锁容器中其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。
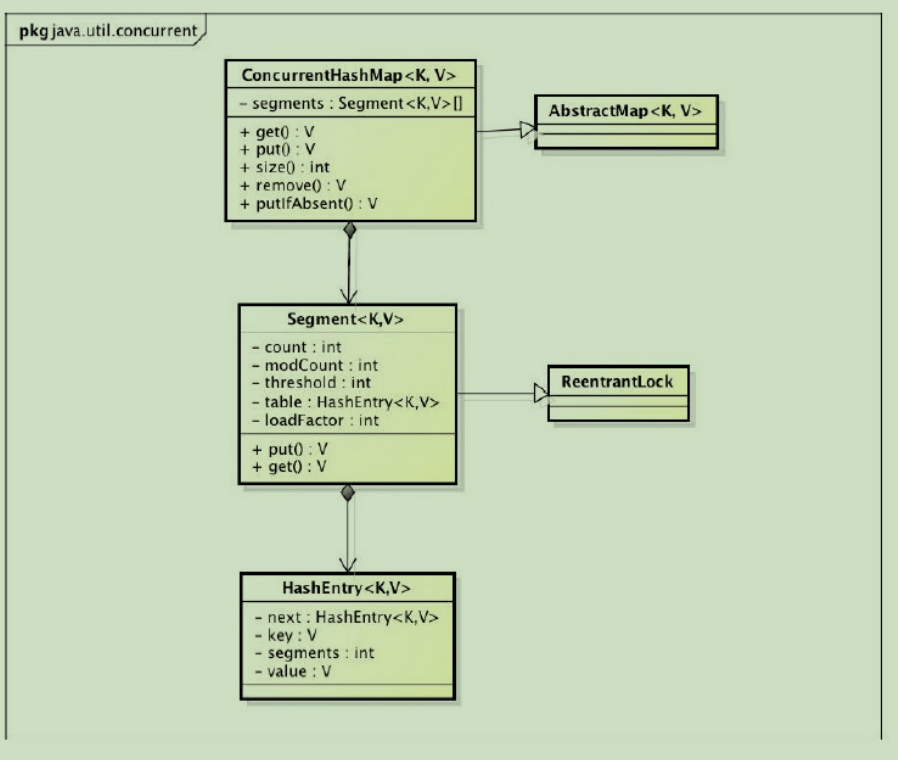
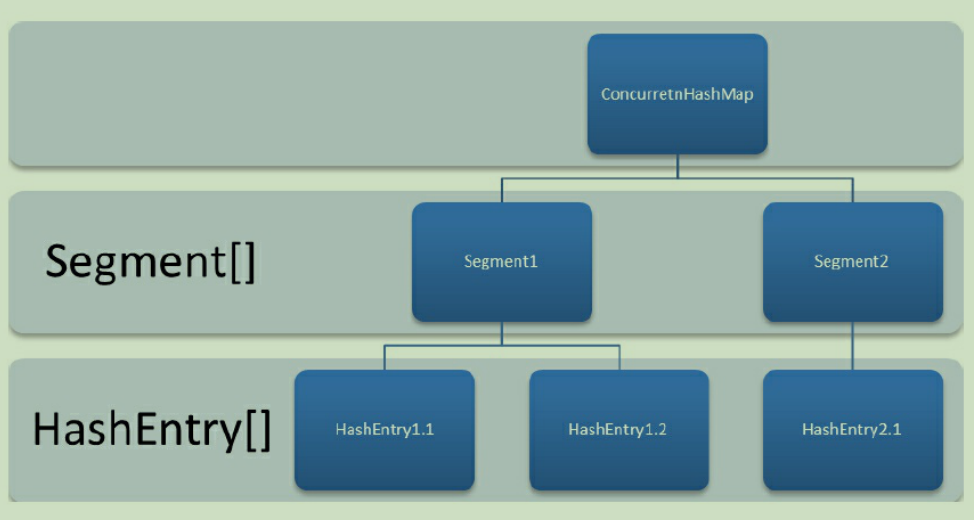
ConcurrentHashMap的结构
ConcurrentHashMap是由Segment数组结构和HashEntry数据结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。
ConcurrentHashMap的操作
get操作
Segment的get操作实现非常简单和高效。先经过一次再散列,然后使用这个散列值通过散列运算定位到Segment,再通过散列算法定位到元素:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
put操作
由于put操作方法里需要对共享变量进行写操作,所以为了线程安全,在操作共享变量时必须加锁。
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
(1)是否需要扩容
在插入元素前先会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阈值,则对数组进行扩容
(2)如何扩容
在扩容的时候,首先会创建一个容量是原来容量两倍的数组,然后对原数组里的元素进行再散列后插入到新的数组里。为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
size操作
如果要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里的元素的大小后求和。
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
并发容器——ConcurrentHashMap的更多相关文章
- 计算机程序的思维逻辑 (74) - 并发容器 - ConcurrentHashMap
本节介绍一个常用的并发容器 - ConcurrentHashMap,它是HashMap的并发版本,与HashMap相比,它有如下特点: 并发安全 直接支持一些原子复合操作 支持高并发.读操作完全并行. ...
- Java编程的逻辑 (74) - 并发容器 - ConcurrentHashMap
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http: ...
- JAVA 多线程随笔 (三) 多线程用到的并发容器 (ConcurrentHashMap,CopyOnWriteArrayList, CopyOnWriteArraySet)
1.引言 在多线程的环境中,如果想要使用容器类,就需要注意所使用的容器类是否是线程安全的.在最早开始,人们一般都在使用同步容器(Vector,HashTable),其基本的原理,就是针对容器的每一个操 ...
- Java并发编程:并发容器ConcurrentHashMap
Java并发编程:并发容器之ConcurrentHashMap(转载) 下面这部分内容转载自: http://www.haogongju.net/art/2350374 JDK5中添加了新的concu ...
- 多线程之并发容器ConcurrentHashMap
这部分内容转载自: http://www.haogongju.net/art/2350374 JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步 ...
- 并发容器ConcurrentHashMap#put方法解析
jdk1.7.0_79 HashMap可以说是每个Java程序员用的最多的数据结构之一了,无处不见它的身影.关于HashMap,通常也能说出它不是线程安全的.这篇文章要提到的是在多线程并发环境下的Ha ...
- 8.并发容器ConcurrentHashMap#put方法解析
jdk1.7.0_79 HashMap可以说是每个Java程序员用的最多的数据结构之一了,无处不见它的身影.关于HashMap,通常也能说出它不是线程安全的.这篇文章要提到的是在多线程并发环境下的Ha ...
- 多线程之并发容器ConcurrentHashMap(JDK1.6)
简介 ConcurrentHashMap 是 util.concurrent 包的重要成员.本文将结合 Java 内存模型,分析 JDK 源代码,探索 ConcurrentHashMap 高并发的具体 ...
- 并发容器-ConcurrentHashMap,CopyOnWriteArrayList
ConcurrentHashMap HashMap是线程非安全的,在多线程环境下,采用的是Fail-Fast快速失败机制,即当A线程在访问容器的时候,如果此时B线程修改了HashMap的结构,那么就会 ...
随机推荐
- windows服务中对外提供API接口
public class SendMqService { private static bool isExcute = true; private static HttpListener listen ...
- [译]通往 Java 函数式编程的捷径
原文地址:An easier path to functional programming in Java 原文作者:Venkat Subramaniam 译文出自:掘金翻译计划 以声明式的思想在你的 ...
- SpringBoot日记——任务处理 之 异步、定时、邮件
---恢复内容开始--- 直接步入正题. 异步任务 异步任务比较简单,只需要两个注解就可以搞定,我们直接来看如何使用: 1.创建一个service,带上@EnableAsync,就是开启异步任务的注解 ...
- JMeter:响应结果乱码解决方法
JMeter:响应结果乱码解决方法 我们经常使用jmeter做接口测试或者正则匹配 看到的响应结果存在乱码,这是小白经常会问的问题,这是因为jmeter会按照jmeter.properties文件中, ...
- 时区提示:Local time zone must be set--see zic manual page 2018的解决办法
问题描述:在centos服务器上执行date命令时,显示的时间信息中的时区不正常,如下: [root@ulocalhost ~]# date Mon Apr 9 02:57:38 Local time ...
- 运维中的日志切割操作梳理(Logrotate/python/shell脚本实现)
对于Linux系统安全来说,日志文件是极其重要的工具.不知为何,我发现很多运维同学的服务器上都运行着一些诸如每天切分Nginx日志之类的CRON脚本,大家似乎遗忘了Logrotate,争相发明自己的轮 ...
- 个人博客-week7
团队任务收获及个人感想 团队任务已经进行了一个多月的时间,我很荣幸能和软剑攻城队的小伙伴们度过这一个月的开发时光.在这一个月的时间里,我亲身经历了一个软件从想法到实现,从创意到实体的过程.同时我也在和 ...
- 01springboot快速入门
SpringBoot快速入门 springboot的宗旨是习惯大于配置,所以spring里面大量使用了默认的配置来简化spring的配置.spring Boot的主要优点: 为所有Spring开发者更 ...
- C++中struct 和 class的区别
首先,C++中类的定义,从狭义上理解,就是我们使用的class类型.从广义上,类就是定义了一个新的类型和新的作用域,它具有成员函数和成员数据. 而对广义类定义的实现分为两种,一种是使用struct实现 ...
- QQ的小秘密
http://ssl.ptlogin2.qq.com/test http://ping.huatuo.qq.com/ http://localhost.ptlogin2.qq.com:4300/mc_ ...