(未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果
环境:
火狐浏览器
pycharm2017.3.3
python3.5
1.url不仅可以是一个字符串,例如:http://www.baidu.com。url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为URLopen的参数使用,方法如下:
from urllib import request
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
html = response.read()
html = html.decode("utf-8")
print(html)
这段代码同样可以得到网页信息
urlopen()返回的对象,可以使用read()进行读取,同样也可以使用geturl(),info()方法,getcode()方法。
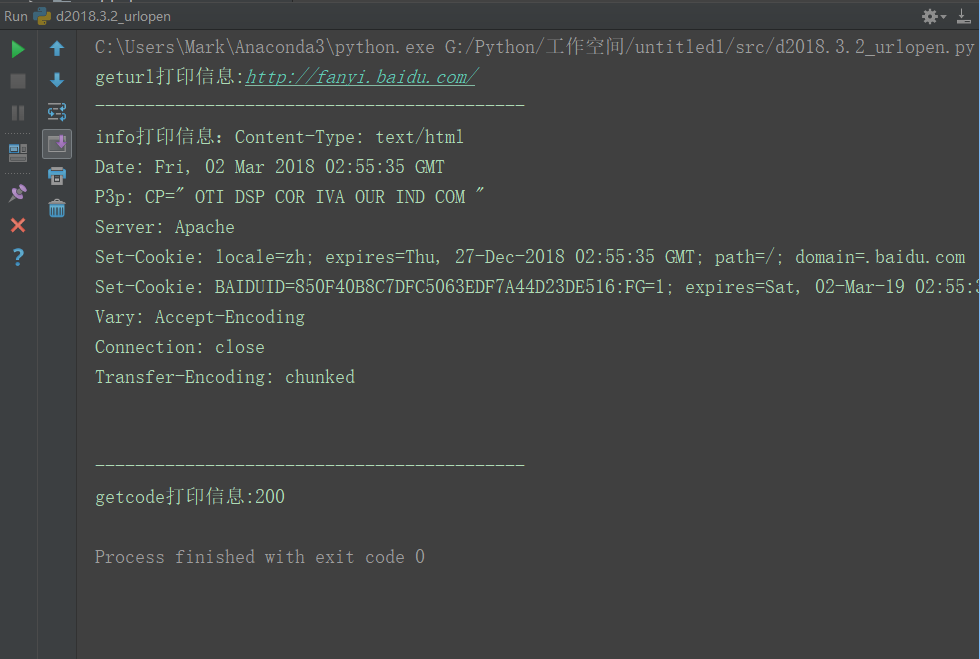
geturl()返回的是一个url的字符串;
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功;
根据这些,编写如下代码
from urllib import request
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
print("geturl打印信息:%s" % (response.geturl()))
print("-------------------------------------------")
print("info打印信息:%s" % (response.info()))
print("-------------------------------------------")
print("getcode打印信息:%s" % (response.getcode()))
运行结果
2.urlopen的data参数
我们可以使用data参数,向服务器发送数据
从客户端向服务器提交数据使用post
如果没有设置urlopen()函数的data参数,HTTP请求采用get方式也就是从服务器获取数据,如果我们设置data参数,HTTP请求采用post方式,就可以向服务器传送数据
3.发送data实例
向有道翻译发送data,得到翻译结果
(1)打开有道翻译界面,如下图所示
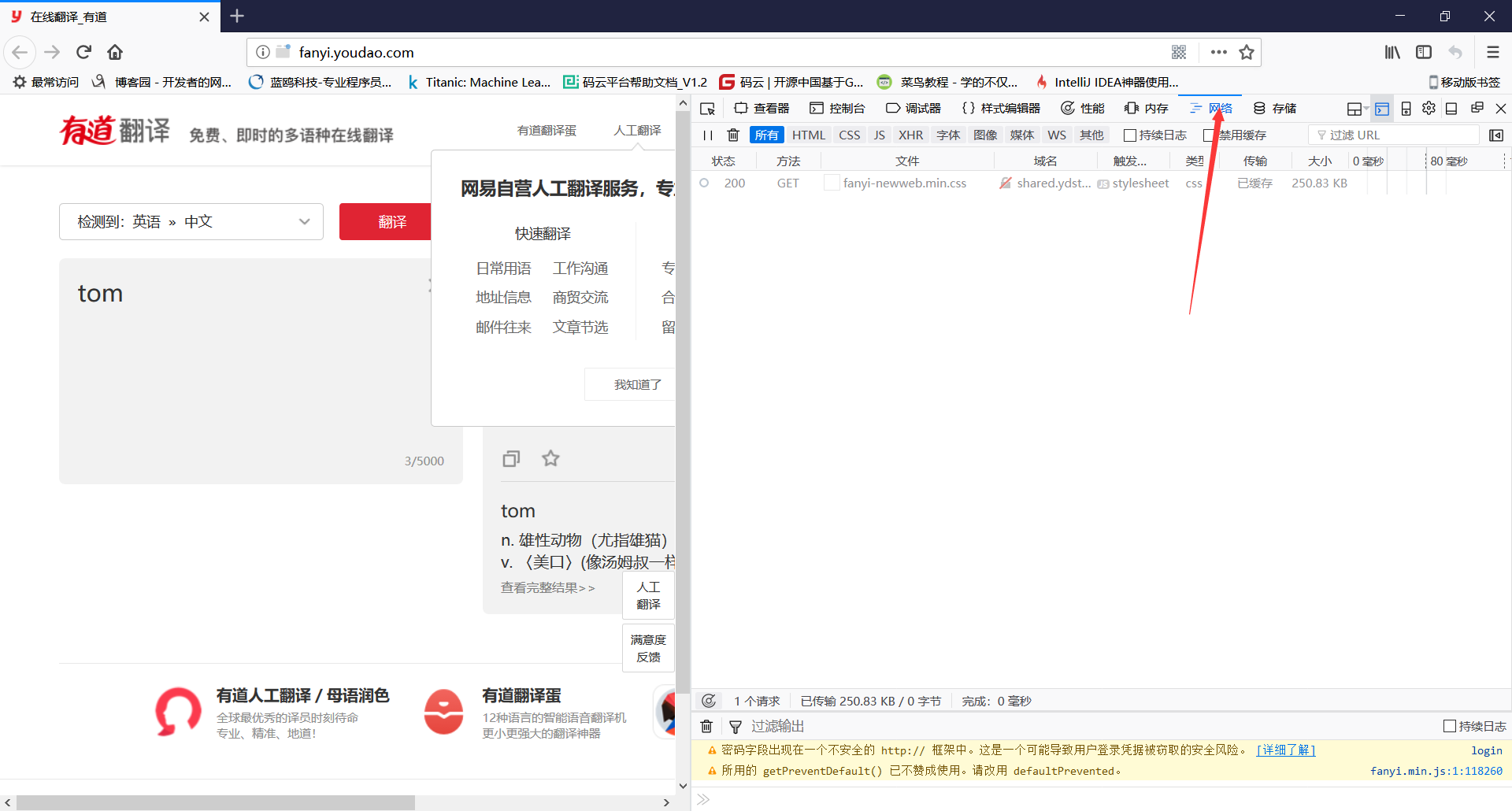
(2)右键查看元素,选择网络
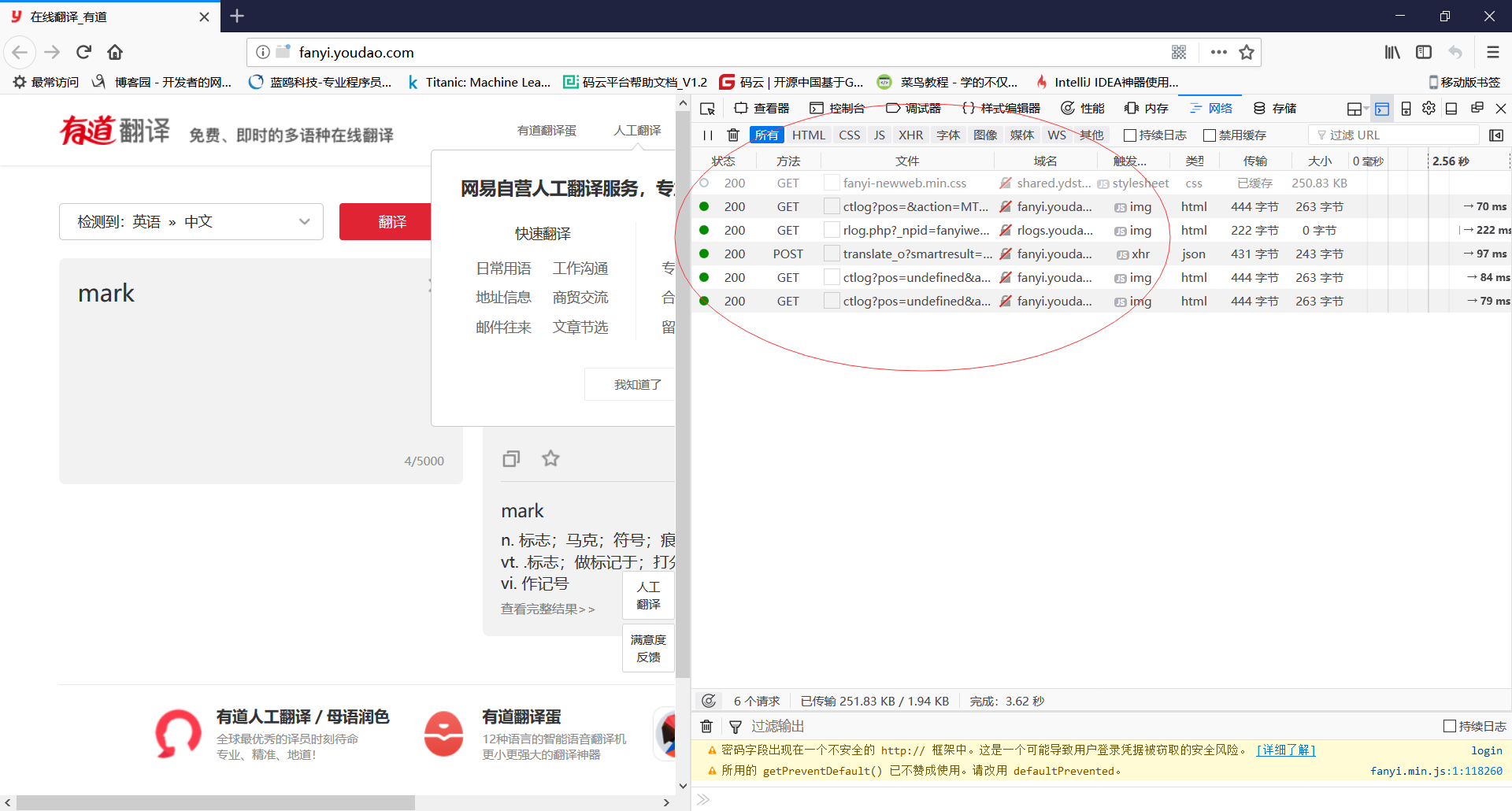
(3)在翻译中输入单词mark,点击翻译,可以看到列表出现了新东西,双击方式为post的这行
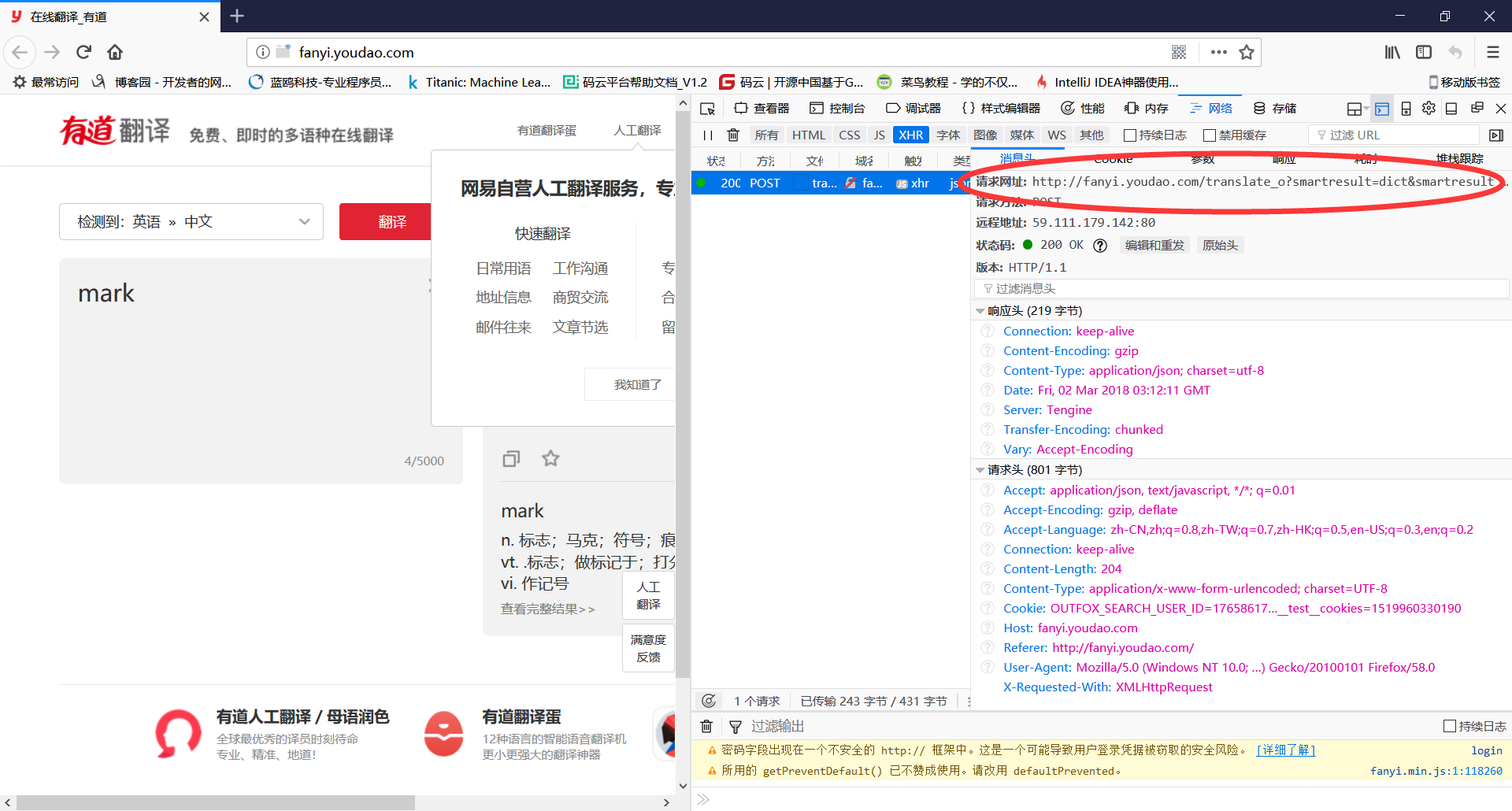
(4)查看消息头中的请求网址,记录下来,一会要用
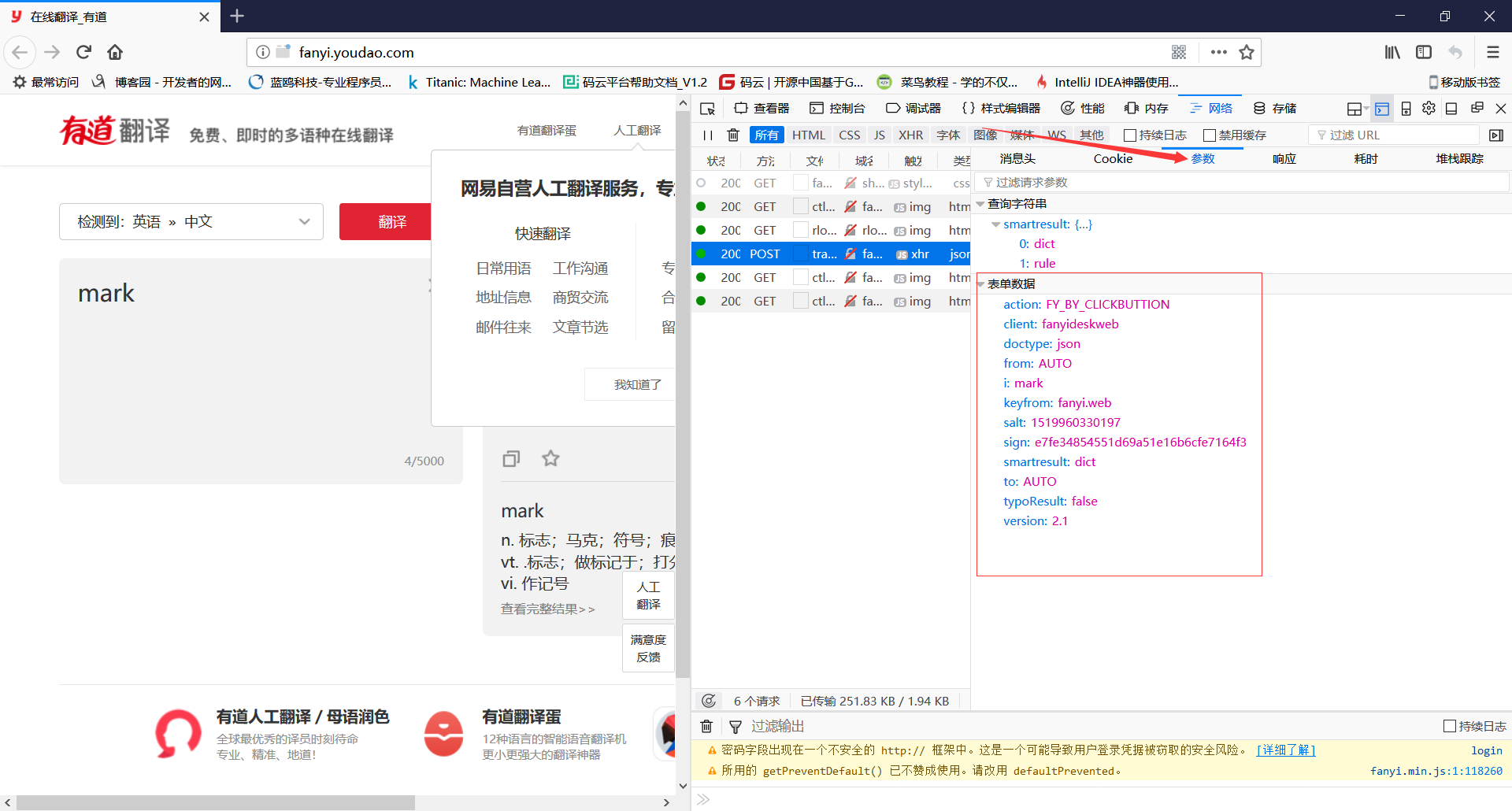
(5)点击参数,得到表单数据,记录下来,一会要用
(6)得到以上数据后,写代码如下
这。。。里有点问题了,好像不能通过抓包爬了,还得使用它的api,研究了一会没整明白,写了这么多,不舍得删了,先撂这,以后再弄,我去找一个抓包可以爬的,再写一篇新的
(未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果的更多相关文章
- Python3网络爬虫(三):urllib.error异常
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 转载请注明作者和出处:http://blog.csdn.net/c406495762/article ...
- 利用urllib.urlopen向有道翻译发送数据获得翻译结果
from urllib import request,parseimport requests, sys,ssl,json ssl._create_default_https_context = ss ...
- Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息
一.urlopen的url参数 Agent url不仅可以是一个字符串,例如:https://baike.baidu.com/.url也可以是一个Request对象,这就需要我们先定义一个Reques ...
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
随机推荐
- Luogu1514 NOIP2010 引水入城 BFS、贪心
传送门 NOIP的题目都难以写精简题意 考虑最上面一排的某一个点对最下面一排的影响是什么样的,不难发现必须要是一段连续区间才能够符合题意. 如果不是一段连续区间,意味着中间某一段没有被覆盖的部分比周围 ...
- (转)Linux SSH配置和禁止Root远程登陆设置
原文 一.修改vi /etc/ssh/sshd_config 文件 1.修改默认端口:默认Port为22,并且已经注释掉了:修改是把注释去掉,并修改成其它的端口. 2.禁止root用户远程登陆:修改P ...
- Bitcoin 使用及配置记录
常用配置 bitcoin-qt.exe -testnet -printtoconsole -conf=D:\Bitcoin\bitcoin.conf -datadir=D:\Bitcoin\Data ...
- Newtonsoft的序列化和反序列化
class test { public string a; public int b; public byte[] c; public In ...
- VMware workstation运维实践系列博客导航
第一章:VMware workstation虚拟化1.1 VMware workstation计算网络存储介绍1.2 VMware workstation其他功能特性介绍1.3 VMware work ...
- Windows10 家庭版 Docker的安装
Docker的安装 1.简介:Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中, 然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全 ...
- 12.18 Daily Scrum
最近大家确实都很忙,所以所有功能的实现要等到下周. Today's Task Tomorrow's Task 丁辛 实现和菜谱相关的餐厅列表. 实现和菜谱相关的餐厅列表. ...
- QT 窗口置顶功能
Qt中,保持窗口置顶的设置为: Qt::WindowFlags m_flags = windowFlags(); setWindowFlags(m_flags | Qt::WindowStaysOnT ...
- Leetcode 546. Remove Boxes
题目链接: https://leetcode.com/problems/remove-boxes/description/ 问题描述 若干个有序排列的box和它们的颜色,每次可以移除若干个连续的颜色相 ...
- 在Eclipse中使用JUnit4进行单元测试(图文教程一)
在Eclipse中使用JUnit4进行单元测试 单元测试,JUnit4. 这两个有什么关系呢?这就好比(草)单元测试和(割草机).用这个JUnit4工具去辅助我们进行测试.其实不理解这个也没关系,听多 ...