celery简单应用
写作背景介绍
在celery简单入门中已经介绍了写作的背景,这篇文章主要是深入介绍celery的使用技巧。在实际的项目中我们需要明确前后台的分界线,因此我们的celery编写的时候就应该是分成前后台两个部分编写。在celery简单入门中的总结部分我们也提出了另外一个问题,就是需要分离celery的配置文件。
第一步
编写后台任务tasks.py脚本文件。在这个文件中我们不需要再声明celery的实例,我们只需要导入其task装饰器来注册我们的任务即可。后台处理业务逻辑完全独立于前台,这里只是简单的hello world程序需要多少个参数只需要告诉前台就可以了,在实际项目中可能你需要的是后台执行发送一封邮件的任务或者进行复杂的数据库查询任务等。
import timefrom celery.task import task@taskdef say(x,y):time.sleep(5)return x+y
第二步
有了那么完美的后台,我们的前台编写肯定也轻松不少。到底简单到什么地步呢,来看看前台的代码吧!为了形象的表明其职能,我们将其命名为client.py脚本文件。
from celery import Celeryapp = Celery()app.config_from_object('celeryconfig')app.send_task("tasks.say",['hello','world'])
可以看到只需要简单的几步
- 声明一个
celery实例。 - 加载配置文件。
- 发送任务
第三步
让我们完成celery的配置吧!官方的介绍使用celeryconfig.py作为配置文件名,这样可以防止与你现在的应用的配置同名。
CELERY_IMPORTS = ('tasks')CELERY_IGNORE_RESULT = FalseBROKER_HOST = '127.0.0.1'BROKER_PORT = 5672BROKER_URL = 'amqp://'CELERY_RESULT_BACKEND = 'amqp'
可以看到我们指定了CELERY_RESULT_BACKEND为amqp默认的队列!这样我们就可以查看处理后的运行状态了,后面将会介绍处理结果的查看。
第四步
启动celery后台服务,这里是测试与学习celery的教程。在实际生产环境中,如果是通过这种方式启动的后台进程是不行的。所谓后台进程通常是需要作为守护进程运行在后台的,在python的世界里总是有一些工具能够满足你的需要。这里可以使用supervisor作为进程管理工具。在后面的文章中将会介绍如何使用supervisor工具。
celery worker -l info --beat
注意现在运行worker的方式也与前面介绍的不一样了,下面简单介绍各个参数。
-l info与--loglevel=info的作用是一样的。--beat周期性的运行
运行后可以看到下面这样的输出。

第五步
前台的运行就比较简单了,与平时运行的python脚本一样。
python client.py
此时应该是什么也没有看到,脚本也没有返回任何数据。运行后立即结束,这是正常的。我们看到后台会发现已经输出了一些数据,这些内容应该大致是显示如下信息。

现在前台的任务是运行了,可是任务是被写死了。我们的任务大多数时候是动态的,为演示动态工作的情况我们可以使用终端发送任务。

在python终端导入celery模块声明实例然后加载配置文件,完成了这些步骤后就可以动态的发送任务并且查看任务状态了。注意在配置文件celeryconfig.py中我们已经开启了处理的结果回应模式了CELERY_IGNORE_RESULT = False并且在回应方式配置中我们设置了CELERY_RESULT_BACKEND = 'amqp'这样我们就可以查看到处理的状态了。
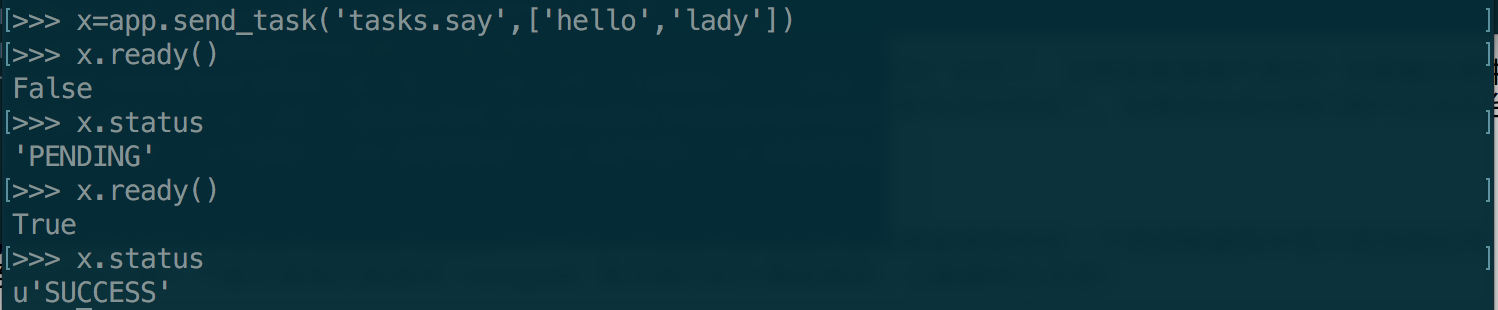
从图中,我们可以看到任务发送给celery后马上查看任务状态会处于PENDING状态。稍等片刻就可以查看到SUCCESS状态了。这种效果真棒不是吗?在图像处理中或者其他的一些搞耗时的任务中,我们只需要把任务发送给后台就不用去管它了。当我们需要结果的时候只需要查看一些是否成功完成了,如果返回成功我们就可以去后台数据库去找处理后生成的数据了。
总结
现在我们的celery看起来有模有样了,不过我们的结果并没有保存在我们最喜欢的数据库中。大多时候我们都希望计算结果能够保存在一个常规数据库中而不是消息队列中,那么celery应该怎么配置才能把数据保存到数据库中呢?下篇文章我们就使用mongodb保存我们的计算结果吧!让数据持久化吧!
celery简单应用的更多相关文章
- celery 分布式异步任务框架(celery简单使用、celery多任务结构、celery定时任务、celery计划任务、celery在Django项目中使用Python脚本调用Django环境)
一.celery简介: Celery 是一个强大的 分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行.我们通常使用它来实现异步任务(async tas ...
- celery简单入门
写作背景介绍 最近在做后台图像处理,需要使用到celery这个异步任务框架.但是使用的时候遇到很多技术问题,为了方便日后再遇到相似问题时能够快速解决.写下这篇文章也希望能够帮助共同奋战在同一战线的程序 ...
- Python—异步任务队列Celery简单使用
一.Celery简介 Celery是一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具.它是一个任务队列,专注于实时处理,同时还支持任务调度. 中间人boker: ...
- celery简单理解和使用
解决同步阻塞的问题 将耗时任务放到后台异步执行,不影响用户其他操作. 实现原理 任务队列是一种跨线程,跨机器的机制. 任务队列中包含称作任务的工作单元.有专门的进程持续不断的监视任务队列,并从中得到新 ...
- celery 简单示例
目录结构 第一步 celery_task 里面的celery文件 import time from celery import Celery # celery from celery.schedul ...
- celery与mangodb搭配应用
写作背景介绍 在celery简单应用中已经介绍了如何去配置一个celery应用,也知道怎么分离任务逻辑代码与客户端代码了.我们现在的任务是怎么把计算结果保存到数据库中,这种数据持久化是非常重要的.你一 ...
- 分布式任务队列Celery入门与进阶
一.简介 Celery是由Python开发.简单.灵活.可靠的分布式任务队列,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务.Celery侧重于实时操作,但对调度支持也很好,其 ...
- 10: Celery
目录: 1.1 Celery介绍 1.2 celery简单使用 1.3 在项目中如何使用celery 1.4 celery与Django项目最佳实践 1.5 基于步骤1.4:在django中使用计划任 ...
- Python 并行分布式框架 Celery
Celery 简介 除了redis,还可以使用另外一个神器---Celery.Celery是一个异步任务的调度工具. Celery 是 Distributed Task Queue,分布式任务队列,分 ...
随机推荐
- jQuery数组处理汇总
jQuery数组处理汇总 有段时间没写什么了, 打算把jquery中的比较常用的数组处理方法汇总一下 $.each(array, [callback])遍历,很常用 1 2 3 4 5 6 7 8 ...
- TCP/ip协议栈之内核调优
大并发带来服务器各种层出不穷的问题,我们要善用服务器系统内核,因为其性能优于用户态的玩意 注:若想永久保存参数,可将其加入到/etc/sysctl.conf中,执行sysctl -p使其永久生效,临时 ...
- flask--虚拟环境
1.安装虚拟环境mosson@mosson:~$ sudo apt-get install virtualenv2.创建一个项目目录mosson@mosson:~$ mkdir myproject3. ...
- [转] MovieClip转Bitmap方法
package { import flash.display.Bitmap; import flash.display.BitmapData; import flash.display.Loader; ...
- Python学习笔记-Day5
冒泡算法: 实现1: a = [,,,,,,,,,,,,,,] def bubble(badlist): sort = False while not sort: sort = True ): ]: ...
- 剑指offer题目21-30
面试题21:包含min函数的栈 import java.util.Stack; public class Solution { private Stack<Integer> stack = ...
- highcharts 使用实例
后端使用django实现,返回的数据可以修改为从数据库获取或其他方式获取,实例里是写死的数据. urls配置: url(r'^outip/chart/$', views.charts), url(r' ...
- android studio view.setId报错
自定义控件设置id的时候会报错,如:view.setId(100); 解决方法: 方案一:通过调用View.generateViewId()作为setId的参数,但此方案不是最佳方案,因为View.g ...
- maven打包时使用的pom配置
<build> <plugins> <!-- compiler插件, 设定JDK版本 --> <plugin> <groupId>org.a ...
- IOS-synthesize和dynamic的异同(转)
一,retain, copy, assign区别 1. 假设你用malloc分配了一块内存,并且把它的地址赋值给了指针a,后来你希望指针b也共享这块内存,于是你又把a赋值给(assign)了b.此时a ...