twitter storm源码走读之2 -- tuple消息发送场景分析
欢迎转载,转载请注明出处源自徽沪一郎。本文尝试分析tuple发送时的具体细节,本博的另一篇文章《bolt消息传递路径之源码解读》主要从消息接收方面来阐述问题,两篇文章互为补充。
worker进程内消息接收与处理全景图
先上幅图简要勾勒出worker进程接收到tuple消息之后的处理全过程
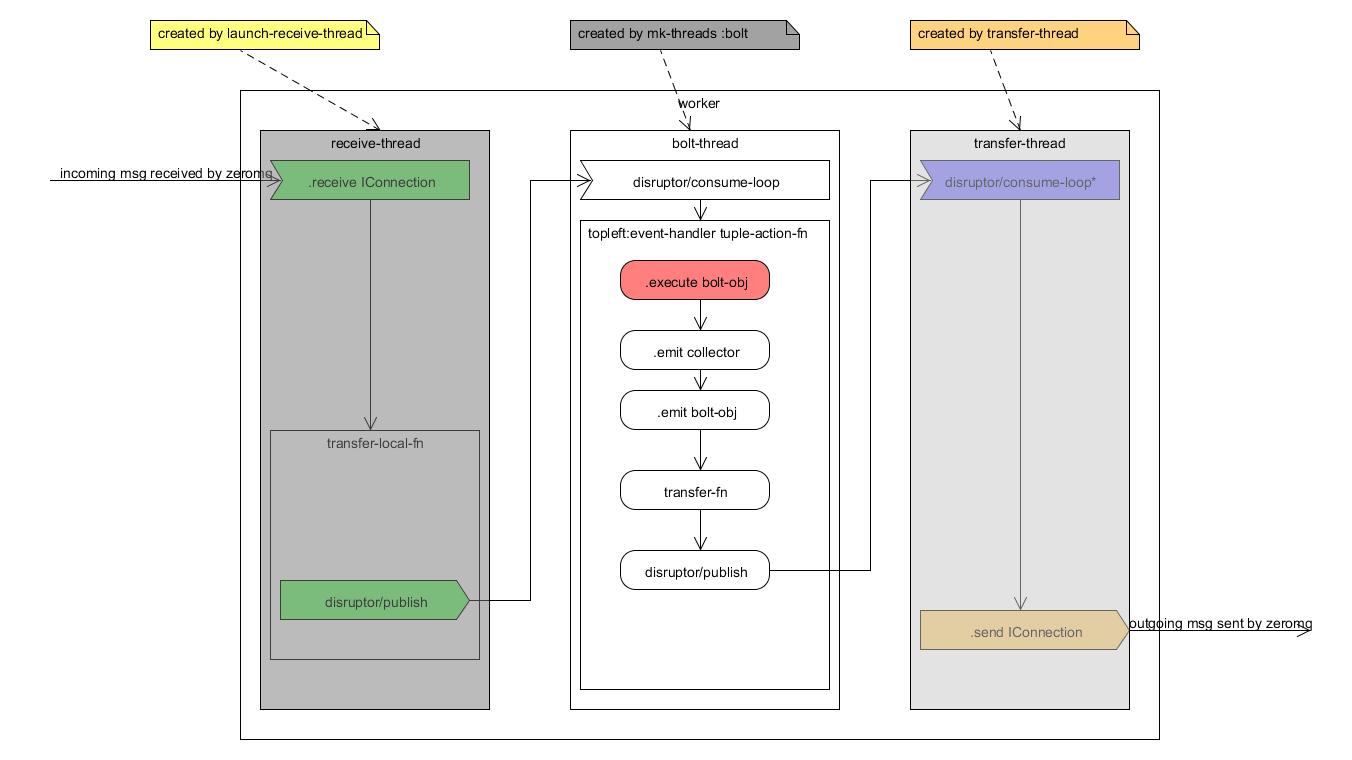
IConnection的建立与使用
话说在mk-threads :bolt函数的实现中有这么一段代码,其主要功能是实现tuple的emit功能
bolt-emit (fn [stream anchors values task]
(let [out-tasks (if task
(tasks-fn task stream values)
(tasks-fn stream values))]
(fast-list-iter [t out-tasks]
(let [anchors-to-ids (HashMap.)]
(fast-list-iter [^TupleImpl a anchors]
(let [root-ids (-> a .getMessageId .getAnchorsToIds .keySet)]
(when (pos? (count root-ids))
(let [edge-id (MessageId/generateId rand)]
(.updateAckVal a edge-id)
(fast-list-iter [root-id root-ids]
(put-xor! anchors-to-ids root-id edge-id))
))))
(transfer-fn t
(TupleImpl. worker-context
values
task-id
stream
(MessageId/makeId anchors-to-ids)))))
(or out-tasks [])))
加亮为蓝色的部分实现的功能是另外发送tuple,那么transfer-fn函数的定义在哪呢?见mk-threads的let部分,能见到下述一行代码
:transfer-fn (mk-executor-transfer-fn batch-transfer->worker)
在继续往下看每个函数实现之前,先确定一下这节代码阅读的目的。storm在线程之间使用disruptor进行通讯,在进程之间进行消息通讯使用的是zeromq或netty, 所以需要从transfer-fn追踪到使用zeromq或netty api的位置。
再看mk-executor-transfer-fn函数实现
(defn mk-executor-transfer-fn [batch-transfer->worker]
(fn this
([task tuple block? ^List overflow-buffer]
(if (and overflow-buffer (not (.isEmpty overflow-buffer)))
(.add overflow-buffer [task tuple])
(try-cause
(disruptor/publish batch-transfer->worker [task tuple] block?)
(catch InsufficientCapacityException e
(if overflow-buffer
(.add overflow-buffer [task tuple])
(throw e))
))))
([task tuple overflow-buffer]
(this task tuple (nil? overflow-buffer) overflow-buffer))
([task tuple]
(this task tuple nil)
)))
disruptor/publish表示将消息从本线程发送出去,至于谁是该消息的接收者,请继续往下看。
worker进程中,有一个receiver-thread是用来专门接收来自外部进程的消息,那么与之相对的是有一个transfer-thread用来将本进程的消息发送给外部进程。所以刚才的disruptor/publish发送出来的消息应该被transfer-thread接收到。
在transfer-thread中,能找到这行下述一行代码
transfer-thread (disruptor/consume-loop* (:transfer-queue worker) transfer-tuples)
对于接收到来自本进程中其它线程发送过来的消息利用transfer-tuples进行处理,transfer-tuples使用mk-transfer-tuples-handler来创建,所以需要看看mk-transfer-tuples-handler能否与zeromq或netty联系上呢?
(defn mk-transfer-tuples-handler [worker]
(let [^DisruptorQueue transfer-queue (:transfer-queue worker)
drainer (ArrayList.)
node+port->socket (:cached-node+port->socket worker)
task->node+port (:cached-task->node+port worker)
endpoint-socket-lock (:endpoint-socket-lock worker)
]
(disruptor/clojure-handler
(fn [packets _ batch-end?]
(.addAll drainer packets)
(when batch-end?
(read-locked endpoint-socket-lock
(let [node+port->socket @node+port->socket
task->node+port @task->node+port]
;; consider doing some automatic batching here (would need to not be serialized at this point to remo
;; try using multipart messages ... first sort the tuples by the target node (without changing the lo
17
(fast-list-iter [[task ser-tuple] drainer]
;; TODO: consider write a batch of tuples here to every target worker
;; group by node+port, do multipart send
(let [node-port (get task->node+port task)]
(when node-port
(.send ^IConnection (get node+port->socket node-port) task ser-tuple))
))))
(.clear drainer))))))
上述代码中出现了与zeromq可能有联系的部分了即加亮为红色的一行。
那凭什么说加亮的IConnection一行与zeromq有关系的,这话得慢慢说起,需要从配置文件开始。
在storm.yaml中有这么一行配置项,即
storm.messaging.transport: "backtype.storm.messaging.zmq"
这个配置项与worker中的mqcontext相对应,所以在worker中以mqcontext为线索,就能够一步步找到IConnection的实现。connections在函数mk-refresh-connections中建立
refresh-connections (mk-refresh-connections worker)
mk-refresh-connection函数中与mq-context相关联的一部分代码如下所示
(swap! (:cached-node+port->socket worker)
#(HashMap. (merge (into {} %1) %2))
(into {}
(dofor [endpoint-str new-connections
:let [[node port] (string->endpoint endpoint-str)]]
[endpoint-str
(.connect
^IContext (:mq-context worker)
storm-id
((:node->host assignment) node)
port)
]
)))
注意加亮部分,利用mq-conext中connect函数来创建IConnection. 当打开zmq.clj时候,就能验证我们的猜测。
(^IConnection connect [this ^String storm-id ^String host ^int port]
(require 'backtype.storm.messaging.zmq)
(-> context
(mq/socket mq/push)
(mq/set-hwm hwm)
(mq/set-linger linger-ms)
(mq/connect (get-connect-zmq-url local? host port))
mk-connection))
代码走到这里,IConnection什么时候建立起来的谜底就揭开了,消息是如何从bolt或spout线程传递到transfer-thread,再由zeromq将tuple发送给下跳的路径打通了。
tuple的分发策略 grouping
从一个bolt中产生的tuple可以有多个bolt接收,到底发送给哪一个bolt呢?这牵扯到分发策略问题,其实在twitter storm中有两个层面的分发策略问题,一个是对于task level的,在讲topology submit的时候已经涉及到。另一个就是现在要讨论的针对tuple level的分发。
再次将视线拉回到bolt-emit中,这次将目光集中在变量t的前前后后。
(let [out-tasks (if task
(tasks-fn task stream values)
(tasks-fn stream values))]
(fast-list-iter [t out-tasks]
(let [anchors-to-ids (HashMap.)]
(fast-list-iter [^TupleImpl a anchors]
(let [root-ids (-> a .getMessageId .getAnchorsToIds .keySet)]
(when (pos? (count root-ids))
(let [edge-id (MessageId/generateId rand)]
(.updateAckVal a edge-id)
(fast-list-iter [root-id root-ids]
(put-xor! anchors-to-ids root-id edge-id))
))))
(transfer-fn t
(TupleImpl. worker-context
values
task-id
stream
(MessageId/makeId anchors-to-ids)))))
上述代码显示t从out-tasks来,而out-tasks是tasks-fn的返回值
tasks-fn (:tasks-fn task-data)
一谈tasks-fn,原来从未涉及的文件task.clj这次被挂上了,task-data与由task/mk-task创建。将中间环节跳过,调用关系如下所列。
- mk-task
- mk-task-data
- mk-tasks-fn
tasks-fn中会使用到grouping,处理代码如下
fn ([^Integer out-task-id ^String stream ^List values]
(when debug?
(log-message "Emitting direct: " out-task-id "; " component-id " " stream " " values))
(let [target-component (.getComponentId worker-context out-task-id)
component->grouping (get stream->component->grouper stream)
grouping (get component->grouping target-component)
out-task-id (if grouping out-task-id)]
(when (and (not-nil? grouping) (not= :direct grouping))
(throw (IllegalArgumentException. "Cannot emitDirect to a task expecting a regular grouping")))
(apply-hooks user-context .emit (EmitInfo. values stream task-id [out-task-id]))
(when (emit-sampler)
(builtin-metrics/emitted-tuple! (:builtin-metrics task-data) executor-stats stream)
(stats/emitted-tuple! executor-stats stream)
(if out-task-id
(stats/transferred-tuples! executor-stats stream 1)
(builtin-metrics/transferred-tuple! (:builtin-metrics task-data) executor-stats stream 1)))
(if out-task-id [out-task-id])
))
而每个topology中的grouping策略又是如何被executor知道的呢,这从另一端executor-data说起。
在mk-executor-data中有下面一行代码
:stream->component->grouper (outbound-components worker-context component-id)
outbound-components的定义如下
(defn outbound-components
"Returns map of stream id to component id to grouper"
[^WorkerTopologyContext worker-context component-id]
(->> (.getTargets worker-context component-id)
clojurify-structure
(map (fn [[stream-id component->grouping]]
[stream-id
(outbound-groupings
worker-context
component-id
stream-id
(.getComponentOutputFields worker-context component-id stream-id)
component->grouping)]))
(into {})
(HashMap.)))
twitter storm源码走读之2 -- tuple消息发送场景分析的更多相关文章
- twitter storm 源码走读之5 -- worker进程内部消息传递处理和数据结构分析
欢迎转载,转载请注明出处,徽沪一郎. 本文从外部消息在worker进程内部的转化,传递及处理过程入手,一步步分析在worker-data中的数据项存在的原因和意义.试图从代码实现的角度来回答,如果是从 ...
- twitter storm源码走读之3--topology提交过程分析
概要 storm cluster可以想像成为一个工厂,nimbus主要负责从外部接收订单和任务分配.除了从外部接单,nimbus还要将这些外部订单转换成为内部工作分配,这个时候nimbus充当了调度室 ...
- twitter storm源码走读之7 -- trident topology可靠性分析
欢迎转载,转载请注明出处,徽沪一郎. 本文详细分析TridentTopology的可靠性实现, TridentTopology通过transactional spout与transactional s ...
- twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. 概述 worker进程启动过程中最 ...
- twitter storm源码走读之1 -- nimbus启动场景分析
欢迎转载,转载时请注明作者徽沪一郎及出处,谢谢. 本文详细介绍了twitter storm中的nimbus节点的启动场景,分析nimbus是如何一步步实现定义于storm.thrift中的servic ...
- twitter storm源码走读之6 -- Trident Topology执行过程分析
欢迎转载,转载请注明出处,徽沪一郎. TridentTopology是storm提供的高层使用接口,常见的一些SQL中的操作在tridenttopology提供的api中都有类似的影射.关于Tride ...
- twitter storm源码走读之8 -- TridentTopology创建过程详解
欢迎转载,转载请注明出处,徽沪一郎. 从用户层面来看TridentTopology,有两个重要的概念一是Stream,另一个是作用于Stream上的各种Operation.在实现层面来看,无论是str ...
- 【原】storm源码之mac os x编译twitter storm源码
twitter storm是由backtype公司创始人nathanmarz一手研发和开源的流计算(实时计算)框架,堪称实时计算领域的hadoop.nathanmarz也是在mac os x环境下开发 ...
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
随机推荐
- Mysql查询比较
创建一个表: article,书编码:dealer,书店:price ,书的价格. 导入一些数据: INSERT INTO shop VALUES (1,'A',3.45),(1,'B',3.99), ...
- 【读书笔记】读《编写高质量代码—Web前端开发修炼之道》 - JavaScript原型继承与面向对象
JavaScript是基于原型的语言,通过new实例化出来的对象,其属性和行为来自于两部分,一部分来自于构造函数,另一部分是来自于原型.构造函数中定义的属性和行为的优先级比原型中定义的属性和优先级高, ...
- cocos2dx实现象棋之运动
1.头文件 void moveStone(int moveid, int killid, int x, int y); void moveComplete(CCNode*, void*); bool ...
- .net学习笔记---Asp.net的生命周期之二页生命周期
用户请求 从 用户角度来说,我不管你后台经历了什么,我只想要我请求的页面.请求到服务器端,服务器必须得有所表示的是吧,即使不想搭理人家也得让IIS给人家说声:找不到服务器.请求来到服务器端,肯定要让服 ...
- Ubuntu安装dos2unix工具
Ubuntu下默认没有安装dos2unix工具,而且也没有一个叫这个名字的工具(我在solaris里用过dos2unix,不知道为啥Ubuntu没有).但是有一个替代工具——tofrodos , 下面 ...
- python联接主流SQL的类库个人收藏
我现在主要是用以下这个类库来分别连接oracle,postgresql,mysql,mssql的. PyMySQL,pymssql,cx_Oracle,psycopg2 收藏 一下.. https:/ ...
- ytu 2011: C语言实验——找中间数(水题)
2011: C语言实验——找中间数 Time Limit: 1 Sec Memory Limit: 64 MBSubmit: 212 Solved: 122[Submit][Status][Web ...
- 【现代程序设计】homework-04
题目要求: 第四次作业,构造一个方阵将指定单词填入 stage 1:每个单词只出现1次,且八个方向各至少有两个单词 stage 2:矩阵长宽相等 stage 3:方阵的四个角都要参与单词的构建 算法思 ...
- 怎样删除github中的项目
前几周上传了下做的app的源码,后来发现源码中有太多错误,匆匆便上传了,之后想删掉一直找不到按钮,看了下help:https://help.github.com/articles/deleting-a ...
- mysql的常用函数
原文地址参考:http://www.cnblogs.com/ringwang/archive/2008/07/05/1236292.html 1. 控制流函数 1.1 IFNULL(expr1,ex ...